KARMA: Kalman-based autoregressive moving average modeling and inference for formant and antiformant tracking
Vocal tract resonance characteristics in acoustic speech signals are classically tracked using frame-by-frame point estimates of formant frequencies followed by candidate selection and smoothing using dynamic programming methods that minimize ad hoc …
Authors: Daryush D. Mehta, Daniel Rudoy, Patrick J. Wolfe
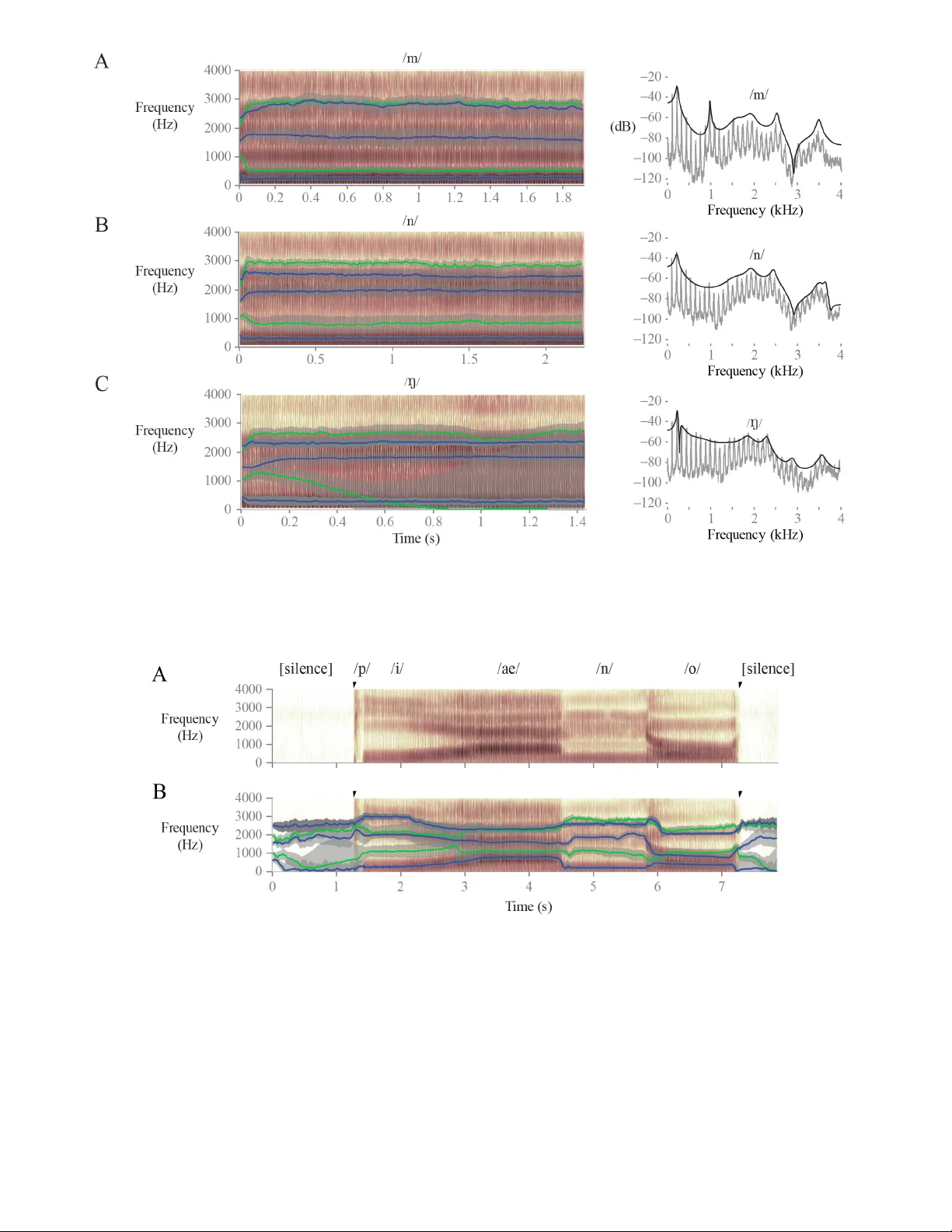
KARMA: Kalman-based autoregressiv e mo ving a v erage mo deling and inference for forman t and an tiforman t trac king a) Da ryush D. Mehta, b) Daniel Rudo y, and P atrick J. Wolfe c) Scho ol of Engineering and Applie d Scienc es, Harvard University, Cambridge, Massachusetts 02138 (Dated: Octob er 29, 2018) V o cal tract resonance characteristics in acoustic sp eec h signals are classically track ed using frame- b y-frame p oin t estimates of forman t frequencies follo w ed b y candidate selection and smoothing using dynamic programming methods that minimize ad ho c cost functions. The goal of the cur- ren t work is to provide b oth p oin t estimates and asso ciated uncertain ties of center frequencies and bandwidths in a statistically principled state-space framew ork. Extended Kalman (K) algorithms tak e adv antage of a linearized mapping to infer formant and antiforman t parameters from frame- based estimates of autoregressive mo ving a verage (ARMA) cepstral co efficien ts. Error analysis of KARMA, W av eSurfer, and Praat is accomplished in the all-p ole case using a manually marked forman t database and synthesized sp eec h wa v eforms. KARMA formant tracks exhibit low er ov er- all ro ot-mean-square error relative to the t wo b enchmark algorithms, with third forman t tracking more challenging. Antiforman t tracking p erformance of KARMA is illustrated using syn thesized and sp ok en nasal phonemes. The simultaneous tracking of uncertaint y levels enables practition- ers to recognize time-v arying confidence in parameters of interest and adjust algorithmic settings accordingly . P ACS n um b ers: 43.72.Ar, 43.70.Bk, 43.60.Cg, 43.60.Uv I. INTRODUCTION Sp eec h formant tracking has receiv ed con tinued atten- tion ov er the past sixty y ears to b etter c haracterize for- man t motion during vo w els as w ell as v ow el-consonant b oundaries. The de facto approac h to resonance estima- tion in volv es w a veform segmen tation and the assumption of an all-p ole mo del characterized by second-order digi- tal resonators (Schafer and Rabiner, 1970). The cen ter frequency and bandwidth of each resonator are then es- timated through picking p eaks in the all-p ole spectrum or finding ro ots of the prediction p olynomial. T rac king these estimates across frames is typically accomplished via dynamic programming metho ds that minimize cost functions to pro duce smo othly-v arying tra jectories. This general forman t-tracking algorithm is imple- men ted in W av eSurfer (Sj¨ olander and Besko w, 2005) and Praat (Bo ersma and W eenink, 2009), speech analysis to ols that enjoy widespread use in the sp eec h recognition, clinical, and linguistic communities. There are, how ever, n umerous shortcomings to this classical approach. F or example, formant trac k smo othing and correction (e.g., for large frequency jumps) are p erformed in an ad ho c manner that precludes that ability to apply statistical a) Portions of this work were presented at the INTERSPEECH con- ference in Ant werp, Belgium, in August 2007 (Rudoy et al. , 2007). b) Electronic address: dmehta@seas.harv ard.edu; also with the Cen- ter for Laryngeal Surgery and V oice Rehabilitation, Massach usetts General Hospital, Boston, Massach usetts 02114 c) Also with the Departmen t of Statistics, Harv ard Univ ersity , and the Speech and Hearing Bioscience and T ec hnology Pro- gram, Harv ard-MIT Division of Health Sciences and T echnology , Massach usetts Institute of T echnology , Cambridge, Massach usetts 02139. analysis to obtain confidence interv als around the esti- mated tracks. Initial developmen t of the formant tracking approac h describ ed here has b een rep orted by Rudoy et al. (2007) using a m an ually marked formant database for error anal- ysis (Deng et al. , 2006b). The current work contin ues this line of research and offers tw o main contributions. The first pro vides improv emen ts to the Kalman-based autoregressiv e approach of Deng et al. (2007) and ex- tensions to enable antiforman t frequency and bandwidth trac king in a Kalman-based autoregressive moving av er- age (KARMA) framework. The second empirically deter- mines the performance of the KARMA approach through visual and quan titative error analysis and compares this p erformance with that of W av eSurfer and Praat. A. Classical formant tracking algorithms Linear predictive coding (LPC) mo dels hav e b een sho wn to efficien tly encode source/filter c haracteristics of the acoustic sp eec h signal (Atal and Hanauer, 1971). T o extract frame-by-frame formant parameters, the p oles of the LPC sp ectrum can b e computed as the ro ots of the prediction p olynomial, p eaks in the LPC sp ectrum, or p eaks in the second deriv ative of the frequency sp ectrum (Christensen et al. , 1976). The first complete formant tr acker ov er multiple contin uous sp eec h frames incorp o- rated sp ectral p eak-pic king, selection of formants from the candidate p eaks using contin uity constraints, and v oicing detection to handle silent and unv oiced sp eec h segmen ts (McCandless, 1974). Extensions to LPC anal- ysis incorp orate autoregressive moving av erage (ARMA) mo dels that added estimates of candidate zeros asso ci- ated with anti-resonances during consonantal and nasal sp eec h sounds (Steiglitz, 1977; Atal and Schroeder, 1978). Kalman-based formant and antiforman t trac king 1 FIG. 1. Illustration of the (A) classical and (B) prop osed approaches to forman t trac king. Key adv antages to the prop osed KARMA approac h include intra-frame observ ation of autoregressiv e moving a verage (ARMA) parameters for both formant and an tiformant tracking, inter-frame tracking using linearized Kalman (K) inference, and the av ailability of b oth p oin t estimates and uncertainties for eac h tra jectory . Fig. 1A illustrates the classical tracking pro cess for the all-p ole case. F ollo wing pre-pro cessing steps, LPC sp ectral co efficients yield intra-frame p oin t estimates of candidate frequency and bandwidth parameters via ro ot finding or p eak-pic king. In tra-frame parameter estima- tion can b e accomplished using a num b er of methods (A tal and Hanauer, 1971; A tal and Sc hroeder, 1978; Broad and Clermon t, 1989; Y egnanaray ana, 1978), and in ter-frame parameter selection and smo othing can b e p erformed by minimizing v arious cost functions in a dy- namic programming environmen t (Sj¨ olander and Besko w, 2005; Bo ersma and W eenink, 2009). Note that the re- quired ro ot-finding (or p eak-pic king) pro cedure cannot b e written in closed form. Consequently , statistical anal- ysis (distributions, bias, v ariance) of the resultant for- man t and bandwidth estimates is challenging. Alter- nativ e sp ectrographic representations primarily apply to sustained vo wels and require significant manual interac- tion (F ulop, 2010). B. Statistical formant tracking algorithms Probabilistic and statistical mo dels for trac king for- man ts hav e gained widespread use in the past 15 years with motiv ation from automatic sp eec h recognition ap- plications. The first suc h probabilistic mo del was intro- duced b y Kop ec (1986), in which a hidden Mark ov model w as used to constrain the evolution of vector-quan tized sets of formant frequencies and bandwidths. Similarly , a state-space dynamical mo del can appropriately constrain the ev olution of formant parame ters, where observ ations of the acoustic sp eec h wa veform are linked through non- linear relationships to “hidden” states (formant parame- ters) that evolv e ov er time. Inference of the state v alues can be p erformed b y v arian ts of Kalman filter algorithms (Kalman, 1960). In these algorithms, ad ho c assignmen t of p oles and zeros to appropriate formant indices is precluded by the inheren t asso ciation of sp ectral/cepstral co efficien ts to forman t and an tiformant frequencies and bandwidths. The first rep orted state-space approac h to formant track- ing inferred formant frequencies and bandwidths directly from LPC sp ectral co efficien ts (Rigoll, 1986). An ex- tension to this LPC approach was made by T oy oshima et al. (1991) to build a track er that inferred frequen- cies and bandwidths of b oth formants and antiforman ts from time-v arying ARMA sp ectral co efficien ts (Miyanaga et al. , 1986). More recent state-space mo dels define the observ ations as co efficients in the LPC c epstr al domain (Zheng and Hasegaw a-Johnson, 2004; Deng et al. , 2007), pro viding statistical metho ds to supp ort or refute empir- ical relations obtained b et ween low-order cepstral co ef- ficien ts and formant frequencies (Broad and Clermont, 1989). The prop osed KARMA (Kalman-based autoregressive mo ving a verage) approac h explores the p erformance of suc h a state-space mo del with ARMA cepstral coeffi- cien ts as observ ations to trac k forman t and antiforman t parameters. T aking adv antage of a linearized mapping b et w een frequency and bandwidth v alues and cepstral co efficien ts, KARMA applies Kalman inference to yield p oin t estimates and uncertain ties for the output tra jec- tories. I I. METHODS Fig. 1B illustrates the prop osed statistical mo deling approac h to formant and an tiforman t tracking. This approac h affords several adv antages o ver classical ap- proac hes: (1) b oth formant and an tiforman t tra jecto- ries are track ed, (2) b oth frequency and bandwidth es- timates are propagated as distributions instead of point estimates to provide for uncertaint y quantification, and (3) p ole/zero assignment to formants/an tiforman ts is made through a linearized cepstral mapping instead of candidate selection using ad ho c cost functions. Kalman-based formant and antiforman t trac king 2 A. Step 1: Pre-processing The sampled acoustic speech wa veform s [ m ] is first windo wed into short-time frames s t [ m ] = s [ m ] w t [ m ] us- ing ov erlapping windows w t [ m ] with frame index t . Each short-time frame s t [ m ] is then pre-emphasized via s t [ m ] = s t [ m ] − γ s t [ m − 1] , (1) where γ is the pre-emphasis co efficien t defining the in- heren t high-pass filter c haracteristic that is typically ap- plied to equalize energy across the sp eec h spectrum for impro ved mo del fitting. B. Step 2: Intra-frame observation generation 1. ARMA mo del of sp eech F ollo wing windowing and pre-emphasis, the acoustic w av eform s t [ m ] is mo deled as a sto chastic ARMA( p, q ) pro cess: s t [ m ] = p X i =1 a i s t [ m − i ] + q X j =1 b j u [ m − j ] + u [ m ] , (2) where a i are the p AR co efficien ts, b j are the q MA co ef- ficien ts, and u [ m ] is the sto c hastic excitation wa v eform. The z -domain transfer function asso ciated with Eq. (2) is T ( z ) , 1 + P q j =1 b j z − j 1 − P p i =1 a i z − i . (3) A n um b er of standard sp ectral estimation techniques can b e emplo yed in order to fit data to the ARMA( p, q ) mo del (see Marelli and Balazs, 2010, for a recent review of ARMA estimation metho ds). In the current study , ARMA estimation was p erformed using the ‘armax’ func- tion in MA TLAB’s System Iden tification toolb ox (The MathW orks, Natic k, MA), which implements an iterativ e metho d to minimize a quadratic error prediction criterion (Ljung, 1999, Section 10.2). 2. Generation of observations: ARMA cepstral co efficients In the prop osed approac h, the ARMA sp ectral co effi- cien ts in Eq. (3) are transformed to the complex cepstrum b efore inferring forman t c haracteristics. This mapping from ARMA spe ctral coefficients to ARMA cepstral co- efficien ts has b een derived in the all-p ole case (e.g., Deng et al. , 2006a) and can b e extended to accoun t for the presence of zeros in the sp ectrum. Letting C n denote the n th cepstral co efficien t, C n = c n − c 0 n , (4) where C n dep ends on separate contributions from the de- nominator and numerator of the ARMA mo del through the following recursive relationships: c n = a n if n = 1 a n + P n − 1 i =1 i n a n − i c i if 1 < n ≤ p P n − 1 i = n − p i n a n − i c i if p < n , (5a) c 0 n = b n if n = 1 b n + P n − 1 j =1 j n b n − j c 0 j if 1 < n ≤ q P n − 1 j = n − q j n b n − j c 0 j if q < n . (5b) Deriv ation of Eqs. (5) is giv en in the App endix. The pro of is derived under the minimum-phase assumption that constrains the p oles and zeros of the ARMA transfer function to lie within the unit circle. C. Step 3: Inter-frame pa rameter tracking The prop osed algorithm trac ks p oin t estimates and un- certain ties for I formants and J antiforman ts from frame to frame. T o accommo date the temp oral dimension, the parameters of frame t are placed in column v ector x t : x t , f 1 . . . f I b 1 . . . b I f 0 1 . . . f 0 J b 0 1 . . . b 0 J T , (6) where ( f i , b i ) is the frequency/bandwidth pair of the i th forman t and ( f 0 j , b 0 j ) is the frequency/bandwidth pair for the j th antiforman t. 1. Observation mo del Inference of the output parameters is facilitated b y a closed-form mapping from the state vector x t to the ob- serv ed cepstral co efficien ts C n in Eq. (4). Extending the sp eec h pro duction mo del of Sc hafer and Rabiner (1970) to capture zeros, we assume that the transfer function T ( z ) of the ARMA mo del can b e written as a cascade of I second-order digital resonators and J second-order digital anti-resonators: T ( z ) = Q J j =1 (1 − β j z − 1 )(1 − β j z − 1 ) Q I i =1 (1 − α i z − 1 )(1 − α i z − 1 ) , (7) where ( α i , α i ) and ( β j , β j ) denote complex-conjugate p ole and zero pairs, respectively . Each p ole and zero are parameterized by a center frequency and 3-dB bandwidth (b oth in units of Hertz) using the follo wing relations: ( α i , α i ) = exp − π b i ± 2 π √ − 1 f i f s , (8a) ( β j , β j ) = exp − π b 0 j ± 2 π √ − 1 f 0 j f s ! , (8b) where f s is the sampling rate (in Hz). P erforming a T aylor-series expansion of log T ( z ) yields log T ( z ) = I X i =1 ∞ X n =1 ( α n i + α n i ) n z − n − J X j =1 ∞ X n =1 β n j + β j n n z − n . (9) Kalman-based formant and antiforman t trac king 3 Recalling that C n is the n th cepstral co efficien t, log T ( z ) = C 0 + P ∞ n =1 C n z − n . Thus, equating the co- efficien ts of p o wers of z − 1 leads to C n = 1 n I X i =1 ( α n i + α i n ) − 1 n J X j =1 β n j + β j n . (10) Finally , inserting α i and β j from Eqs. (8) into Eq. (10) yields the following observ ation mo del h ( x t ) that maps elemen ts of x t to C n : h ( x t ) , C n = 2 n I X i =1 exp − π n f s b i cos 2 π n f s f i − 2 n J X j =1 exp − π n f s b 0 j cos 2 π n f s f 0 j . (11) 2. State-space mo del W e adopt a state-space framework similar to that by Deng et al. (2007) to mo del the ev olution of the state v ector in Eq. (6) from frame t to frame t + 1: x t +1 = F x t + w t , (12a) y t = h ( x t ) + v t , (12b) where F is the state transition matrix, and w t and v t are uncorrelated white Gaussian sequences with cov ari- ance matrices Q and R , resp ectiv ely . The function h ( x t ) is the nonlinear mapping of Eq. (11), and vector y t con- sists of estimates of the first N cepstral co efficien ts of C n (not including the zeroth co efficient). The initial state x 0 follo ws a normal distribution with mean µ 0 and co- v ariance Σ 0 . The state-space mo del of Eqs. (12) is th us parameterized by the set θ : θ , ( F , Q , R , µ 0 , Σ 0 ) . (13) 3. Linea rization via Taylo r appro ximation The cepstral mapping in Eq. (11) can b e lin- earized to enable appr oximate minim um-mean-square- error (MMSE) estimates of the track ed states via the extended Kalman filter. The mapping h ( x t ) is linearized b y computing the first-order terms of the T aylor-series expansion of C n in Eq. (11): ∂ C n ∂ f i = − 4 π f s exp − π n f s b i sin 2 π n f s f i , ∂ C n ∂ b i = − 2 π f s exp − π n f s b i cos 2 π n f s f i , ∂ C n ∂ f 0 j = 4 π f s exp − π n f s b 0 j sin 2 π n f s f 0 j , ∂ C n ∂ b 0 j = 2 π f s exp − π n f s b 0 j cos 2 π n f s f 0 j . T ABLE I. Extended Kalman smo other algorithm. 1. Initialization: Set m 0 | 0 = µ 0 and P 0 | 0 = Σ 0 2. Filtering: Rep eat for t = 1 , . . . , T m t | t − 1 = F m t − 1 | t − 1 P t | t − 1 = F P t − 1 | t − 1 F T + Q K t = P t | t − 1 H T t H t P t | t − 1 H T t + R − 1 (16) m t | t = m t | t − 1 + K t ( y t − h ( m t | t − 1 )) P t | t = P t | t − 1 − K t H t P t | t − 1 3. Smo othing: Rep eat for t = T , . . . , 1 S t = P t − 1 | t − 1 F T P − 1 t | t − 1 m t − 1 | T = m t − 1 | t − 1 + S t m t | T − F m t − 1 | t − 1 P t − 1 | T = P t − 1 | t − 1 + S t P t | T − P t − 1 | t − 1 S T t The Jacobian matrix H t th us consists of four sub- matrices for eac h frame t : H t , H ( f i ) H ( b i ) H ( f 0 j ) H ( b 0 j ) , (14) where H ( f i ) and H ( b i ) each consists of N rows and p/ 2 columns: H ( f i ) , ∂ C 1 ∂ f 1 ∂ C 1 ∂ f 2 · · · ∂ C 1 ∂ f p/ 2 ∂ C 2 ∂ f 1 ∂ C 2 ∂ f 2 · · · ∂ C 2 ∂ f p/ 2 . . . . . . . . . . . . ∂ C N ∂ f 1 ∂ C N ∂ f 2 · · · ∂ C N ∂ f p/ 2 , (15a) H ( b i ) , ∂ C 1 ∂ b 1 ∂ C 1 ∂ b 2 · · · ∂ C 1 ∂ b p/ 2 ∂ C 2 ∂ b 1 ∂ C 2 ∂ b 2 · · · ∂ C 2 ∂ b p/ 2 . . . . . . . . . . . . ∂ C N ∂ b 1 ∂ C N ∂ b 2 · · · ∂ C N ∂ b p/ 2 , (15b) and H ( f 0 j ) and H ( b 0 j ) are defined analogously each with N rows and q / 2 columns. 4. Kalman-based inference Giv en observ ations y t for frame indices 1 to T , the extended Kalman smo other (EKS) can b e used to com- pute the mean m t | T (p oin t estimates) and cov ariance P t | T (estimate uncertainties) of each parameter in x t . T able I displays the steps of the EKS, which employs a t wo-pass filtering (forward) and smo othing (backw ard) pro cedure. F or real-time pro cessing, the forward filter- ing stage may b e applied without a backw ard smo othing pro cedure; naturally , this will lead to larger uncertain ties in the corresp onding parameter estimates. Care must b e tak en when appro ximating the observ a- tion mo del of Eq. (11) to av oid suboptimal p erformance or algorithm divergence in the case of the Kalman fil- ter (Julier and Uhlmann, 1997). T o verify the appro- priateness of the linearization in Section I I.C.3 in this Kalman-based formant and antiforman t trac king 4 FIG. 2. (Color online) Comparison of KARMA (blue) and particle filter (red) tracking p erformance in terms of ro ot- mean-square error (RMSE) av eraged ov er 25 Mon te Carlo trials and rep orted with 95 % confidence in terv als (gray). setting, comparisons are made to a more computation- ally intensiv e metho d of sto c hastic computation termed a particle filter, whic h approximates the densities in ques- tion by sequentially propagating a fixed n umber of sam- ples, or “particles,” and hence av oids the linearization of Eq. (11). Tw ent y-five Mon te Carlo simulations of 100-sample data sequences were p erformed according to Eqs. (12) with four complex-conjugate p ole pairs ( p = 8, q = 0) and N = 15 cepstral co efficien ts. Fig. 2 compares the output of KARMA using the extended Kalman filter of T able I and that of a particle filter in terms of ro ot-mean- square error (RMSE) as a function of the num b er of par- ticles, av eraged ov er all forman t frequency tracks (true bandwidths w ere provided to both algorithms). The p er- formance of the EKF compares fa vorably to that of the particle filter, even when a large n umber of particles is used. Similar results hold ov er a broad range of parame- ter v alues. 5. Observabilit y of states The mo del of Eq. (12) do es not explicitly take into accoun t the existence of sp eec h and non-sp eec h states. T o con tinue to track or c o ast parameters during silence frames, the state v ector x t can b e augmented with a bi- nary indicator v ariable to sp ecify the presence of sp eec h in the frame. The approximate MMSE state estimate is then obtained via EKS inference by mo difying the Kalman gain in Eq. 16: K t = M t P t | t − 1 H T t H t P t | t − 1 H T t + R − 1 , where M t is a diagonal matrix with diagonal entries equal to 1 or 0 dep ending on the presence or absence, resp ec- tiv ely , of sp eec h energy in frame t . In addition, to handle the presence or absence of particular tracks, the state vector x t can b e dynam- ically mo dified to include or omit corresp onding fre- quency/bandwidth states in Eq. (6). The approximate MMSE state estimate is then obtained via EKS inference in T able I with the mo dified state v ector. If an absent state reapp ears in a giv en frame, that state is reinitialized with corresp onding entries in µ 0 and Σ 0 . 6. Model order selection and system identification As is commonly done, the orders p and q of the ARMA mo del are c hosen to capture as muc h information as p os- sible on the p eaks and v alleys in the resonance spec- trum, while av oiding ov erfitting and mistakenly captur- ing source-related information. The ARMA cepstral or- der N is chosen to b e at least max( p, q ) so that all p ole/zero information is incorp orated p er Eq. (5). Fi- nally , selecting I and J in Eq. (11) dep ends on the ex- p ected num b er of formants and an ti-formants, respec- tiv ely , in the speech bandwidth f s / 2. F orman ts do not ev olve indep endently of one another, and their temp oral tra jectories are not indep enden t in frequency . In the synthesis of front vo wels, it is common practice to employ a line ar r e gr ession of f 3 on to f 1 and f 2 (Nearey, 1989, e.g.). Empirically , we found the for- man t cross-correlation function to deca y slowly (Rudoy et al. , 2007), implying that a set of formant v alues at frame t might b e helpful in predicting v alues of all for- man ts at frame t + 1. T h us, instead of setting the state transition matrix F to the identit y matrix (Deng et al. , 2006a, 2007), F is estimated a priori for a particular utterance from first-pass W a veSurfer formant frequency trac ks using a linear least-squares estimator (Hamilton, 1994). The state transition co v ariance matrix Q , which dic- tates the frame-to-frame frequency v ariation, consists of a diagonal matrix with v alues corresp onding to standard deviations of approximately 320 Hz for cen ter frequencies and 100 Hz for bandwidths. These v alues were empiri- cally found to follow temp oral v ariations of sp eec h articu- lation. The co v ariance matrix R , represen ting the signal- to-noise ratio of the cepstral co efficien ts, is a diagonal matrix with elements R nn = 1 /n for n ∈ { 1 , 2 , . . . , N } . This was observed to b e in reasonable agreemen t with the v ariance of the residual vector of the cepstral co efficien ts deriv ed from sp eec h w av eforms. The center frequencies and bandwidths are initialized to µ 0 = 500 1500 2500 80 120 160 Hz. The initial co v ariance Σ 0 is set to Q . D. Summa ry of KARMA approach T able I I outlines the steps of the prop osed KARMA algorithm, which includes a pre-pro cessing stage, intra- frame ARMA cepstral co efficien t estimation, and in ter- frame tracking of formant and an tiformant parameters using Kalman inference. E. Benchma rk algo rithms P erformance of KARMA is compared with that of Praat (Bo ersma and W eenink, 2009) and W av eSurfer (Sj¨ olander and Besk ow, 2005), tw o soft ware pack ages Kalman-based formant and antiforman t trac king 5 T ABLE I I. Prop osed KARMA algorithm for formant and an- tiforman t tracking. Rep eat for frames t = 1 , . . . , T (Online or batch mo de) 1. Pre-pro cessing of input sp eec h wa veform s [ m ] (a) Window: s t [ m ] = s [ m ] w t [ m ] (b) Pre-emphasize s t [ m ] 2. Intra-frame observ ation of N cepstral co efficients (a) Estimate ARMA( p, q ) sp ectral co efficien ts ˆ a i and ˆ b j in Eq. (3) (b) Conv ert ˆ a i and ˆ b j to ARMA cepstral co efficients using Eq. (4) 3. Inter-frame parameter trac king of I formants and J an- tiforman ts (a) Apply Kalman filtering step in T able I (b) m t | t are p oin t estimates and diagonal elements of P t | t are asso ciated v ariances of the estimates Rep eat for frames t = T , . . . , 1 (Batch mo de only) 4. Inter-frame parameter trac king of I formants and J an- tiforman ts (a) Apply Kalman smo othing step in T able I (b) m t | T are p oin t estimates and diagonal elements of P t | T are asso ciated v ariances of the estimates that see wide use among v oice and speech researchers. W a veSurfer and Praat b oth follow the classical formant trac king approach in which frame-b y-frame format fre- quency candidates are obtained from the all-p ole sp ec- trum and smo othed across the entire speech utterance to remo ve outliers and constrain the tra jectories to physi- ologically plausibile v alues. Smo othing is accomplished through dynamic programming to minimize the sum of the following three cost functions: (1) the deviation be- t ween the frequency for each formant from baseline v al- ues of each frequency; (2) a measure of the quality fac- tor f i /b i of a formant, where higher qualit y factors are fa vored; and (3) a transition cost that p enalizes large frequency jumps. The user sets weigh ts to these cost functions to tune the algorithm’s p erformance. I II. RESUL TS Ev aluation of KARMA is accomplished in the all-p ole case using the vocal tract resonance (VTR) database (Deng et al. , 2006b). Since the VTR database itself only yields estimates of ground truth and exhibits observ able lab eling errors, tw o sp eec h databases are created using o verlap-add of syn thesis sp eec h frames using the four VTR forman t tracks. Antiforman t trac king p erformance of KARMA is illustrated using synthesized and sp ok en nasal phonemes. A. Erro r analysis using a hand-corrected formant database The VTR database con tains a represen tative subset of the TIMIT sp eech corpus (Garofolo et al. , 1993) that consists of 516 diverse, phonetically-balanced utterances collated across gender, individual sp eak ers, dialects, and phonetic con texts. The VTR database contains state in- formation for four formant tra jectory pairs (cen ter fre- quency and bandwidth). The first thr e e center frequency tra jectories were manually corrected after an initial au- tomated pass (Deng et al. , 2004). Corrections were made using knowledge-based interv en tion based on the sp eec h wa v eform, its wideband sp ectrogram, word- and phoneme-lev el transcriptions, and phonemic b oundaries. Analysis parameters of KARMA are set to the follow- ing v alues: f s = 7 kHz, 20 ms Hamming windows with 50 % o verlap, γ = 0 . 7, p = 12 ( q = 0), and I = 3 ( J = 0). Each frame is fit with an ARMA(12 , 0) mo del using the auto correlation metho d of linear prediction and, subsequently , transformed to N = 15 cepstral co- efficien ts via Eq. (5). The initial state vector is set to x 0 = 500 1500 2500 T , and Σ 0 is set to Q . TIMIT phone transcriptions are used to indicate whether each frame contains sp eec h energy or a silence region. A frame is considered silen t if all its samples are lab eled as a pause ( p au , epi , h# ), closure interv al ( b cl , dcl , gcl , p cl , tcl , kcl ), or glottal stop ( q ). Thus, errors due to sp eec h activity detection are minimized, and all tracks are coasted dur- ing silent frames. Default smo othing settings are set within W av eSurfer and Praat. Other analysis parameters are matched to KARMA: f s = 7 kHz, 20 ms Hamming windows with 50 % o verlap, γ = 0 . 7, p = 12 ( q = 0), and I = 3 ( J = 0). T able I I I summarizes the performance of KARMA, W av eSurfer, and Praat on the VTR database. The ro ot- mean-square error (RMSE) p er formant is computed ov er all sp eech frames for each utterance and then av eraged, p er forman t, across all 516 utterances in the database. The cepstral-based KARMA approach results in low er o verall error compared to the classical algorithms, with particular gains for f 1 and f 2 trac king. Praat exhibits the low est av erage error for f 3 . Figure 3 illustrates the formant trac ks output from the three algorithms for VTR utterance 200 sp ok en by an adult female. During non-speech regions (the first 700 ms exhibits noise energy during inhalation), mean KARMA T ABLE I II. F ormant trac king p erformance of KARMA, W a veSurfer, and Praat in terms of ro ot-mean-square error (RMSE) p er formant av eraged across 516 utterances in the VTR database (Deng et al. , 2006b). RMSE is only computed o ver sp eec h-lab eled frames. F ormant KARMA W a veSurfer Praat f 1 114 Hz 170 Hz 185 Hz f 2 226 Hz 276 Hz 254 Hz f 3 320 Hz 383 Hz 303 Hz Ov erall 220 Hz 276 Hz 247 Hz Kalman-based formant and antiforman t trac king 6 FIG. 3. (Color online) Estimated formant tracks on sp ectrogram of VTR utterance 200: “Withdraw only as m uch money as y ou need.” Reference tra jectories from the VTR database are sho wn in red along with the formant frequency tracks in blue from (A) KARMA, (B) W av eSurfer, and (C) Praat. The KARMA output additionally displays uncertainties (gra y shading, ± 1 standard deviation) for each formant tra jectory and sp eech-labeled frames (green). Rep orted ro ot-mean-square error (RMSE) is av eraged across formants conditioned on sp eech presence for each frame. trac k estimates are linear with increasing uncertaint y for frames that are farther from frames with formant infor- mation. Compared to the W a veSurfer and Praat trac ks, KARMA tra jectories are smo other and better b ehav ed, reflecting the slow-mo ving nature of the speech articula- tors. The classical algorithms exhibit errant tracking of f 2 during the /i/ vo wel in “need” at 2 . 5 s that is handled b y the KARMA approac h. B. Erro r analysis using synthesized databases Sp eec h wa veforms in the first database (VTRsyn th) are synthesized through o verlap-add of frames that each follo w the ARMA mo del of Eq. (2). ARMA spec- tral co efficien ts are deriv ed from the four formant fre- quency/bandwidth pairs in the corresp onding frame of the VTR database utterance using the impulse-inv ariant transformation of a digital resonator (Klatt, 1980). The source excitation is white Gaussian noise during non- silence frames. Synthesis parameters are set to the fol- lo wing v alues: f s = 16 kHz, 20 ms Hanning windows with 50 % ov erlap, and p = 8 ( q = 0). The second database (VTRsyn thf0) in tro duces a mo del mismatch b et ween synthesis and KARMA anal- ysis b y applying a Rosenberg C source wa veform (Rosen- b erg, 1971) instead of white noise for each frame consid- ered voiced. The fundamental frequency of each voiced frame in the original VTR database is estimated by W av eSurfer. The VTRsynthf0 database thus includes v oiced, un voiced, and non-sp eec h frames. Synthesis pa- rameters are set as in the VTRsyn th database. F ormant tra jectories from these tw o syn thesized databases act as truer ground truth con tours than in the VTR database to test the p erformance of the cepstral-based KARMA algorithm. T able IV and T able V display performance on the VTRsyn th and VTRsyn thf0 databases, resp ectiv ely , of the three tested algorithms with settings as described in the previous section. The prop osed KARMA approac h compares fav orably to W av eSurfer and Praat. The sim- ilar error of KARMA and W av eSurfer v alidates the use of ARMA cepstral co efficients as observ ations in place of ARMA sp ectral co efficien ts. C. Antifo rmant tracking The KARMA approac h to formant and antiforman t trac king is illustrated in this section. Syn thesized and real speech examples are presen ted to determine the abil- T ABLE IV. Average RMSE of KARMA, W av eSurfer, and Praat forman t tracking of the first three formant tra jecto- ries in the VTRsynth database that resynthesizes utterances using a sto c hastic source and formant trac ks from the VTR database. Error is only computed ov er sp eec h-lab eled frames. F ormant KARMA W a veSurfer Praat f 1 29 Hz 37 Hz 58 Hz f 2 53 Hz 60 Hz 123 Hz f 3 64 Hz 54 Hz 130 Hz Ov erall 48 Hz 50 Hz 104 Hz Kalman-based formant and antiforman t trac king 7 it y of the ARMA-derived cepstral co efficien ts to capture p ole and zero information. 1. Synthesized wavefo rm In the synthesized case, a speech-lik e wa veform /n A n/ is generated with v arying frame-by-frame forman t and an tiformant characteristics and a p eriodic source excita- tion as was implemented for the VTRsynthf0 database. The /n A n/ wa veform is s yn thesized at f s = 10 kHz us- ing 75 100 ms frames with 50 % o verlap. F ormant fre- quencies (bandwidths) of the /n/ phonemes are set to 257 Hz (32 Hz) and 1891 Hz (100 Hz). One antiforman t is placed at 1223 Hz (bandwidth of 52 Hz) to mimic the lo cation of an alveolar nasal antiforman t. F ormant fre- quencies (bandwidths) of / A / were set to 850 Hz (80 Hz) and 1500 Hz (120 Hz). A random term with zero mean and standard deviation of 10 Hz w as added to each tra- jectory to sim ulate realistic v ariation. Fig. 4 sho ws the results of formant and antiforman t trac king using KARMA on the synthesized phoneme string /n A n/. Two different visualizations are display ed. Fig. 4A plots point estimates and uncertan ties of the cen- ter frequency and bandwidth tra jectories for each frame. Fig. 4B displa ys the wideband sp ectrogram with o verlaid cen ter frequency tracks whose width reflects the corre- sp onding 3-dB bandwidth v alue. Note that the length of the state vector in the KARMA’s state-space mo del is mo dified dep ending on the presence or absence of an- tiforman t energy . Estimated tra jectories fit the ground truth v alues well once initialized v alues reach a steady state. 2. Spoken nasals During real sp eec h, a vocal tract configuration consist- ing of multiple acoustic paths results in the p ossible ex- istence of b oth p oles and zeros in transfer function T ( z ) (Eq. 7). F or example, the effects of an tiresonances might en ter the transfer function of nasalized sp eec h sounds as zeros in T ( z ). Typically , the frequency of the low est zero dep ends on tongue p osition. F or the labial nasal conso- nan t /m/, the frequency of this antiresonance is approxi- mately 1100 Hz. As the p oin t of closure mov es tow ard the bac k of the oral ca vity—suc h as for the alv eolar and velar T ABLE V. Average RMSE of KARMA, W av eSurfer, and Praat formant tracking of the first three formant tra jectories in the VTRsynthf0 database that resyn thesizes VTR database utterances using stochastic and perio dic sources. Error is only computed ov er sp eec h-lab eled frames. F ormant KARMA W a veSurfer Praat f 1 44 Hz 57 Hz 57 Hz f 2 53 Hz 58 Hz 117 Hz f 3 62 Hz 59 Hz 111 Hz Ov erall 53 Hz 58 Hz 95 Hz nasal consonants—the length of the resonator decreases, and the frequency of this zero increases. The frequency of a second zero is approximately three times the fre- quency of the lo west zero due to the quarter-wa velength oral cavit y configuration. KARMA p erformance was ev aluated visually on sp o- k en nasal consonants pro duced with closure at the labial (/m/), alveolar (/n/), and velar (/ N /) p ositions. The extended Kalman smo other w as applied using an ARMA(16 , 4) mo del, f s = 8 kHz, 20 ms Hamming win- do ws with 50 % o v erlap, N = 20 cepstral co efficients, and γ = 0 . 7. The frequencies (bandwidths) of the formants w ere initialized to 500 Hz (80 Hz), 1500 Hz (120 Hz), and 2500 Hz (160 Hz). The frequencies (bandwidths) of the antiforman ts were initialized to 1000 Hz (80 Hz) and 2000 Hz (80 Hz). Figure 5 displa ys KARMA outputs (p oin t estimate and uncertain ty of frequency trac ks) and a veraged sp ectra for the three sustained consonants. The KARMA algorithm tak es a few frames to settle to its steady-state estimates. As exp ected, the frequency of the an tiformant increases as the p osition of closure mov es to ward the back of the oral ca vity . The uncertaint y of the first antiforman t of / N / increases significantly , indicating that this antifor- man t is not well observ ed in the wa veform. Note that the inclusion of zeros greatly improv es the ability of the ARMA mo del to fit the underlying wa veform sp ectra. Finally , the KARMA track er was applied to the sp o- k en w ord “piano” to determine if the an tiformant tracks w ould capture any zeros during the nasal phoneme. Fig- ure 6 displa ys the KARMA forman t and an tiformant trac ks with their asso ciated uncertainties. During the non-nasalized regions, the uncertain ty around the p oin t estimates of the antiforman t trac k is large, reflecting the lac k of antiresonance information. During the /n/ seg- men t, the uncertain t y of the an tiformant tracks decreases to reveal observ able antiforman t information. IV. DISCUSSION In this article, the task of trac king frequencies and bandwidths of forman ts and antiforman ts w as ap- proac hed from a statistical p oin t of view. The ev olution of parameters was cast in a state-space mo del to provide access to p oint estimates and uncertainties of each trac k. The key relationship w as a linearized mapping b et ween cepstral coefficients and forman t and antiforman t param- eters that allow ed for the use of the extended family of Kalman inference algorithms. The VTR database provides an initial b enc hmark of “ground truth” for the first three formant frequency v al- ues to which multiple algorithm outputs can b e com- pared. The v alues in the VTR database, how ever, should b e interpreted with caution b ecause starting v alues were initially obtained via a first-pass automatic algorithm Deng et al. (2004). It is unclear how muc h manual in- terv ention was required and what types of errors w ere corrected. In particular, VTR tracks do not alwa ys ov er- lap high-energy sp ectral regions. Despite the presence of v arious lab eling errors in the VTR database, it is still Kalman-based formant and antiforman t trac king 8 FIG. 4. (Color online) Illustration of the output from KARMA for the synthesized utterance /n A n/. Plots in panel A ov erlay the true tra jectories (red) with the mean estimates (blue for forman ts, green for antiforman ts) and uncertain ties (gray shading) for each frequency and bandwidth. Panel B plots an alternative display with a wideband sp ectrogram along with estimated frequency and bandwidth tracks of formants (blue) and antiforman ts (green). The 3-dB bandwidths dictate the width of the corresp onding frequency tracks. useful to obtain initial p erformance of formant tracking algorithms on real sp eec h. In the current framework, cepstral co efficien ts are de- riv ed from the sp ectral co efficien ts of the fitted sto chas- tic ARMA mo del (Section I I.B). Source information re- lated to phonation is th us separated from vocal tract res- onances by assuming that the source is a white Gaussian noise pro cess. This is not the case in reality , esp ecially for v oiced sp eech, where the source excitation component has its o wn characteristics in frequency (e.g., sp ectral slop e) and time (e.g., p erio dicit y). This mo del mismatch has b een explored here via VTRsynthf0, though we note that it is also p ossible to incorp orate more sophisticated source mo deling through the use flexible basis functions suc h as wa velets (Mehta et al. , 2011). An alternative approach to ARMA mo deling is to com- pute the nonparametric (real) cepstrum directly from the sp eec h samples. Based on the conv olutional mo del of sp eec h, low-quefrency cepstral co efficien ts are largely link ed to vocal tract information up to ab out 5 ms (Childers et al. , 1977), dep ending on the fundamen tal frequency . Skipping the 0th cepstral co efficien t that quan tifies the o verall sp ectral lev el, this w ould trans- late to including up to the first 35 cepstral co efficien ts in the observ ation vector y t in the state-space framew ork (Eq. 12). Although coefficients from the real cepstrum do not strictly adhere to the observ ation mo del derived in Eq. 11, the appro ximate separation of source and filter in the nonparametric cepstral domain makes this approach viable. Figure 7 illustrates the output of the algorithm using the first 15 co efficients of the real cepstrum as obser- v ations. Interestingly the p erformance of the nonpara- metric cepstrum is comparably to that of the paramet- ric ARMA cepstrum, esp eically for the first formant fre- quency . Most of the error stems from underestimating the second and third formant frequencies. Adv antages to using the nonparametric cepstrum include computational efficiency and freedom from ARMA mo del constraints. The capability of automated metho ds to track the third forman t strongly dep ends on the resampling fre- quency , which con trols the amount of energy in the sp ec- trum at higher frequencies. F or example, if the signal w ere resampled to 10 kHz, a giv en algorithm might erro- neously track the third formany frequency through sp ec- tral regions typically ascrib ed to the fourth formant. T ra- ditional formant tracking algorithms hav e access to mul- tiple candidate frequencies, which are constantly resorted so that f 4 > f 3 > f 2 > f 1 . In the prop osed statisti- cal approach, the ordering of formant indices is inher- en t in the mapping of formants to cepstral co efficien ts (11), and further empirical study of this formants-to- Kalman-based formant and antiforman t trac king 9 FIG. 5. (Color online) KARMA output for three sp ok en nasals: (A) /m/, (B) /n/, and (C) / N /. On the left, sp ectrograms o verla y the mean estimates (blue for formants, green for antiforman ts) and uncertainties (gray shading) for each frequency and bandwidth. Plots to the righ t display the corresp onding p erio dogram (gray) and sp ectral ARMA mo del fit (black). FIG. 6. (Color online) KARMA formant and antiforman t tracks of utterance by adult male: “piano.” Display ed are the (A) wideband sp ectrogram of the sp eech wa veform and (B) the sp ectrogram ov erlaid with formant frequeny estimates (blue), an tiformant frequency estimates (green), and uncertainties ( ± 1 standard deviation) for each track (gra y). Arro ws indicate b eginning and ending of utterance. Note that the increase in uncertaint y during silence regions. cepstrum mapping can be exp ected to lead to improv ed metho ds when there are additional resonances present in the sp eech bandwidth. F urther analysis of “noise” in the estimated ARMA cepstrum can also b e exp ected to im- pro ve ov erall robustness in the presence of v arious sources of uncertaint y (T ourneret and Lacaze, 1995). Ov erall, the prop osed KARMA approach compares fa- v orably with W a veSurfer and Praat in terms of root- mean-square error. RMSE, ho wev er, is only one selected error metric, whic h must b e v alidated b y observing how Kalman-based formant and antiforman t trac king 10 FIG. 7. (Color online) KARMA formant tracks using observ ations from (A) parametric ARMA cepstrum and (B) nonparametric real cepstrum for VTRsyn thf0 utterance 1: “Even then, if she to ok one step forw ard, he could catc h her.” Reference tra jectories from the VTR database are sho wn in red with the outputs of KARMA in blue. KARMA uncertainties ( ± 1 standard deviation) are shown as gray shading. Rep orted ro ot-mean-square error (RMSE) av erages across 3 formants conditioned on the presence of sp eec h energy for each frame. w ell ra w tra jectories b eha ve. The proposed KARMA trac ker yields smo other outputs as a result and offers pa- rameters that allo w the user to tune the p erformance of the algorithm in a statistically principled manner. Such w ell b ehav ed tra jectories may b e particularly desirable for the resyn thesis of p erceptually natural sp eec h. Though considerably more complex and more sensi- tiv e to mo del assumptions, a time-v arying autoregres- siv e moving a verage (TV-ARMA) mo del has b een pre- viously prop osed for forman t and an tiformant tracking (T oy oshima et al. , 1991) with little follo w-up inv estiga- tion. In their study , T o yoshima et al. used an extended Kalman filter to solv e for ARMA sp ectral co efficien ts at eac h sp eec h sample. One real zero and one real p ole w ere included to mo del changes in gross sp ectral shap e o ver time. While a frame-based approach (as tak en in KARMA) app ears to yield more salient parameters at a lo wer computational cost, future w ork could consider this as well as alternative time-v arying approaches (Rudoy et al. , 2011). As a final observ ation, antiforman t tracking remains a challenging task in sp eech analysis. An tiresonances are typically less strong than their resonant coun terparts during nasalized phonation, and the estimation of sub- glottal resonances contin ues to rely on empirical relation- ships rather than direct acoustic observ ation (Arsik ere et al. , 2011). Nevertheless, the prop osed approac h allows the user the option of trac king an tiformants during select sp eec h regions of interest. P otential improv ements here include the use of formal statistics tests for detecting the presence of zeros within a frame prior to trac king them. V. CONCLUSIONS This article has presented KARMA, a Kalman-based autoregressiv e moving a verage modeling approach to for- man t and antiforman t tracking. The contributions of this w ork are tw ofold. The first is methodological, with im- pro vemen ts to the Kalman-based AR approac h of Deng et al. (2007) and extensions to enable antiforman t fre- quency and bandwidth trac king in a KARMA frame- w ork. The second is empirical, with visual and quan- titativ e error analysis of the KARMA algorithm demon- strating impro vemen ts o ver tw o standard speech pro cess- ing to ols, W a veSurfer (Sj¨ olander and Besko w, 2005) and Praat (Bo ersma and W eenink, 2009). It is exp ected that additional impro vemen ts will come with b etter understanding of precisely how forman t infor- mation is captured through this class of nonlinear ARMA (or nonparametric) cepstral co efficient mo dels. As noted, an tiformant tracking remains c hallenging, although it has b een shown here that appropriate results can b e obtained for selected cases exhibiting antiresonances. The demon- strated effectiveness of this approach, coupled with its abilit y to capture uncertain ty in the frequency and band- width estimates, yields a statistically principled to ol ap- propriate for use in clinical and other applications where it is desired, for example, to quantitativ ely assess acous- tic features suc h as nasality , subglottal resonances, and coarticulation. APPENDIX: DERIV A TION OF CEPSTRAL COEFFICIENTS FROM THE ARMA SPECTRUM Assume an ARMA pro cess with the minim um-phase rational transfer function T ( z ) , B ( z ) A ( z ) = 1 + P q j =1 b j z − j 1 − P p i =1 a i z − i , (A.1) whic h in turn implies a right-sided complex cepstrum. F or the moment, assume b j = 0 for 1 ≤ j ≤ q to initially deriv e the all-p ole LPC cepstrum whose Z -transform is Kalman-based formant and antiforman t trac king 11 denoted by C ( z ): C ( z ) , log T ( z ) = ∞ X n =0 c n z − n , (A.2) where c n = 1 2 π I z = e iw (log T ( z )) z n − 1 dz is the n th co efficien t of the LPC cepstrum. Using the c hain rule, d dz − 1 T ( z ) can b e obtained in- dep enden tly from Eq. (A.1) or Eq. (A.2), yielding the relation dC ( z ) dz − 1 = 1 T ( z ) dT ( z ) dz − 1 = P p i =1 ia i z − i +1 1 − P p i =1 a i z − i , whic h implies that P p i =1 ia i z − i +1 1 − P p i =1 a i z − i = ∞ X n =0 c n d dz − 1 z − n = ∞ X n =0 nc n z − n +1 . Rearranging the terms ab o ve, we obtain ∞ X n =0 nc n z − n +1 = p X i =1 ia i z − i +1 + p X i =1 a i z − i ∞ X n =0 nc n z − n +1 . (A.3) Using Eq. (A.3), we can match the co efficien ts of terms on b oth sides with equal exp onen ts. In the constant- co efficien t case (asso ciated to z 0 ), we ha ve c 1 = a 1 . F or 1 < n ≤ p , w e obtain c n = a n + n − 1 X i =1 n − i n a i c n − i = a n + n − 1 X i =1 1 − i n a i c n − i . On the other hand, if n > p , then Eq. (A.3) implies that c n = n − 1 X i = n − p n − i n a i c n − i = n − 1 X i =1 1 − i n a i c n − i . In summary , we hav e obtained the follo wing relationship b et w een the prediction p olynomial co efficients and the complex cepstrum: c n = a 1 if n = 1 a n + P n − 1 i =1 n − i n a i c n − i if 1 < n ≤ p P n − 1 i = n − p n − i n a i c n − i if p < n . Rev ersing the roles of i and ( n − i ) yields the all-pole v ersion in Eq. (5a). T o allo w for nonzero b j co efficien ts in Eq. (A.1), we obtain the ARMA cepstral co efficien ts C n b y separating con tributions from the numerator and denominator of Eq. (A.1) as follows: C n = Z − 1 log T ( z ) = Z − 1 log 1 A ( z ) − Z − 1 log 1 B ( z ) = c n − c 0 n , yielding the resp ectiv e p ole and zero recursions of Eqs. (5). Arsik ere, H., Lulich, S. M., and Alwan, A. ( 2011 ). “Auto- matic estimation of the first subglottal resonance”, J. Acoust. So c. Am. 129 , EL197–EL203. A tal, B. S. and Hanauer, S. L. ( 1971 ). “Sp eec h analysis and syn thesis by linear prediction of the sp eec h wa ve”, J. Acoust. So c. Am. 50 , 637–655. A tal, B. S. and Sc hro eder, M. R. ( 1978 ). “Linear prediction analysis of sp eec h based on a p ole-zero representation”, J. Acoust. So c. Am. 64 , 1310–1318. Bo ersma, P . and W eenink, D. ( 2009 ). “Praat: Doing phonet- ics by computer”, v ersion 5.1.40 retrieved from www.praat.org 13 July 2009. Broad, D. J. and Clermont, F. ( 1989 ). “F ormant estimation b y linear transformation of the LPC cepstrum”, J. Acoust. So c. Am. 86 , 2013–2017. Childers, D. G., Skinner, D. P ., and Kemerait, R. C. ( 1977 ). “The cepstrum: A guide to pro cessing”, Pro c. IEEE 65 , 1428–1443. Christensen, R., Strong, W., and Palmer, E. ( 1976 ). “A com- parison of three metho ds of extracting resonance informa- tion from predictor-co efficien t coded sp eec h”, IEEE T rans. Acoust. 24 , 8–14. Deng, L., Acero, A., and Bazzi, I. ( 2006 a). “T racking vocal tract resonances using a quantized nonlinear function embed- ded in a temp oral constraint”, IEEE T rans. Audio Sp eec h Lang. Pro cessing 14 , 425–434. Deng, L., Cui, X., Pruv enok, R., Huang, J., Momen, S., Chen, Y., and Alwan, A. ( 2006 b). “A database of vocal tract res- onance tra jectories for research in sp eech pro cessing”, Pro c. IEEE Int. Conf. Acoust. Sp eec h Signal Pro cess. 1 , 369–372. Deng, L., Lee, L. J., Attias, H., and Acero, A. ( 2004 ). “A structured sp eech mo del with contin uous hidden dynam- ics and prediction-residual training for tracking vocal tract resonances”, IEEE In ternational Conference on Acoustics, Sp eec h, and Signal Pro cessing 1 , I–557–60. Deng, L., Lee, L. J., Attias, H., and Acero, A. ( 2007 ). “Adaptiv e Kalman filtering and smo othing for tracking vocal tract resonances using a contin uous-v alued hidden dynamic mo del”, IEEE T rans. Audio Sp eec h Lang. Pro cessing 15 , 13– 23. F ulop, S. A. ( 2010 ). “Accuracy of forman t measuremen t for syn thesized v o wels using the reassigned sp ectrogram and com- parison with linear prediction”, J. Acoust. So c. Am. 127 , 2114–2117. Garofolo, J. S., Lamel, L., Fisher, W., Fiscus, J., Pallett, D., Dahlgren, N., and Zue, V. ( 1993 ). TIMIT A c oustic- Phonetic Continuous Sp e e ch Corpus (Linguistic Data Con- sortium, Philadelphia, P A). Hamilton, J. D. ( 1994 ). Time Series Analysis (Princeton Univ ersity). Julier, S. and Uhlmann, J. ( 1997 ). “A new extension of the Kalman filter to nonlinear systems”, Proceedings of AeroSense: The 11th International Symp osium on Aerospace/Defense Sensing, Simulation, and Controls 3 , 26. Kalman, R. E. ( 1960 ). “A new approach to linear filtering and prediction problems”, T rans. ASME J. Basic Eng. 82 , 35–45. Klatt, D. H. ( 1980 ). “Soft ware for a cascade/parallel forman t syn thesizer”, J. Acoust. So c. Am. 67 , 971–995. Kop ec, G. ( 1986 ). “F ormant tracking using hidden marko v mo dels and vector quantization”, IEEE T rans. Acoust. 34 , 709–729. Ljung, L. ( 1999 ). System Identific ation (Upp er Saddle River, NJ: Prentice-Hall). Marelli, D. and Balazs, P . ( 2010 ). “On p ole-zero model esti- mation methods minimizing a logarithmic criterion for speech Kalman-based formant and antiforman t trac king 12 analysis”, IEEE T rans. Audio Sp eech Lang. Pro cessing 18 , 237–248. McCandless, S. ( 1974 ). “An algorithm for automatic for- man t extraction using linear prediction spectra”, IEEE T rans. Acoust. 22 , 134–141. Meh ta, D. D., Rudoy , D., and W olfe, P . J. ( 2011 ). “Joint source-filter mo deling using flexible basis functions”, IEEE In t. Conf. Acoust. Sp eech Signal Pro cessing . Miy anaga, Y., Miki, N., and Nagai, N. ( 1986 ). “Adaptive iden tification of a time-v arying arma sp eec h mo del”, IEEE T rans. Acoust. 34 , 423–433. Nearey , T. M. ( 1989 ). “Static, dynamic, and relational prop- erties in vo wel p erception”, J. Acoust. So c. Am. 85 , 2088– 2113. Rigoll, G. ( 1986 ). “A new algorithm for estimation of forman t tra jectories directly from the sp eec h signal based on an ex- tended k alman-filter”, Pro c. IEEE Int. Conf. Acoust. Sp eech Signal Pro cess. 11 , 1229–1232. Rosen b erg, A. E. ( 1971 ). “Effect of glottal pulse shape on the qualit y of natural vo wels”, J. Acoust. So c. Am. 49 , 583–590. Rudo y , D., Quatieri, T., and W olfe, P . ( 2011 ). “Time-v arying autoregressions in sp eech: Detection theory and applica- tions”, IEEE T rans. Audio Sp eec h Lang. Pro cessing 19 , 977– 989. Rudo y , D., Sp endley , D. N., and W olfe, P . J. ( 2007 ). “Con- ditionally linear Gaussian mo dels for estimating vocal tract resonances”, Pro c. INTERSPEECH 526–529. Sc hafer, R. W. and Rabiner, L. R. ( 1970 ). “System for au- tomatic formant analysis of voiced sp eech”, J. Acoust. So c. Am. 47 , 634–648. Sj¨ olander, K. and Besko w, J. ( 2005 ). “Wav eSurfer for Win- do ws”, version 1.8.5 retrieved 1 Nov em b er 2005. Steiglitz, K. ( 1977 ). “On the simultaneous estimation of p oles and zeros in sp eec h analysis”, IEEE T rans. Acoust. 25 , 229– 234. T ourneret, J.-Y. and Lacaze, B. ( 1995 ). “On the statistics of estimated reflection and cepstrum co efficients of an autore- gressiv e pro cess”, Signal Pro cessing 43 , 253–267. T o yoshima, T., Miki, N., and Nagai, N. ( 1991 ). “Adapa- tiv e forman t estimation with comp ensation for gross sp ectral shap e”, Electronics and Communications in Japan (Part I II: F undamen tal Electronic Science) 74 , 58–68. Y egnanara yana, B. ( 1978 ). “F orman t extraction from linear- prediction phase sp ectra”, J. Acoust. So c. Am. 63 , 1638–1640. Zheng, Y. and Hasegaw a-Johnson, M. ( 2004 ). “F ormant trac king by mixture state particle filter”, Pro c. IEEE Int. Conf. Acoust. Sp eec h Signal Pro cess. 1 , 565–568. Kalman-based formant and antiforman t trac king 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment