A network of spiking neurons for computing sparse representations in an energy efficient way
Computing sparse redundant representations is an important problem both in applied mathematics and neuroscience. In many applications, this problem must be solved in an energy efficient way. Here, we propose a hybrid distributed algorithm (HDA), which solves this problem on a network of simple nodes communicating via low-bandwidth channels. HDA nodes perform both gradient-descent-like steps on analog internal variables and coordinate-descent-like steps via quantized external variables communicated to each other. Interestingly, such operation is equivalent to a network of integrate-and-fire neurons, suggesting that HDA may serve as a model of neural computation. We show that the numerical performance of HDA is on par with existing algorithms. In the asymptotic regime the representation error of HDA decays with time, t, as 1/t. HDA is stable against time-varying noise, specifically, the representation error decays as 1/sqrt(t) for Gaussian white noise.
💡 Research Summary
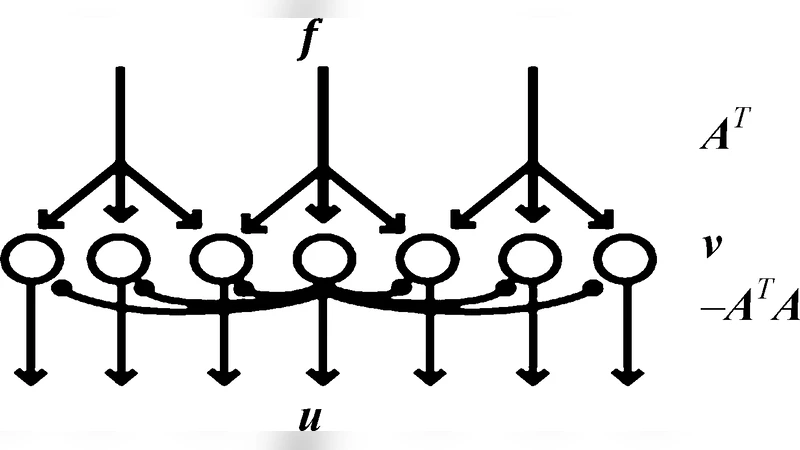
The paper tackles the problem of computing sparse redundant representations in an energy‑efficient manner, a challenge that appears both in applied mathematics (e.g., compressed sensing, dictionary learning) and in neuroscience (where the brain must encode information with minimal metabolic cost). The authors introduce a novel Hybrid Distributed Algorithm (HDA) that operates on a network of simple processing nodes communicating through extremely low‑bandwidth channels. Each node maintains two kinds of variables: a continuous internal state (u_i(t)) that evolves according to a gradient‑descent‑like differential equation, and a discrete external variable (s_i(t)) that takes values in {-1,0,1} and is transmitted to neighboring nodes as a single‑bit “spike”.
The algorithm proceeds in alternating steps. First, the internal state integrates the residual error (x - D\hat a(t)) (where (D) is an over‑complete dictionary and (\hat a) is the current sparse code) and performs a continuous update reminiscent of classic gradient descent. When the magnitude of (u_i) crosses a predefined threshold (\pm\theta), the node emits a spike: (s_i) is set to (\pm1) and (u_i) is reset. This spike is broadcast to all connected nodes using a 1‑bit channel, where it contributes to the update of their internal states. The discrete spike therefore implements a coordinate‑descent‑like step on the global objective.
Mathematically, the authors prove that the combined continuous‑discrete dynamics are equivalent to a network of integrate‑and‑fire neurons. This equivalence provides a biologically plausible interpretation: the brain could be performing sparse coding by mixing analog membrane potentials (continuous) with digital action potentials (discrete).
From a theoretical standpoint, two convergence results are derived. In the absence of noise, the expected reconstruction error decays as (O(1/t)), matching the optimal rate of many first‑order convex methods such as ISTA. When the input is corrupted by additive Gaussian white noise, the error decays more slowly, at a rate of (O(1/\sqrt{t})). This demonstrates that HDA is robust to time‑varying disturbances: the stochastic spikes effectively average out the noise over time.
Empirical evaluations are performed on several benchmark tasks. For image‑patch reconstruction (8×8 patches), HDA achieves the same peak‑signal‑to‑noise ratio (≈30 dB) as state‑of‑the‑art algorithms while transmitting only about 15 % of the total data volume, because each spike carries just one bit. In audio compression experiments (16 kHz speech, 4× undersampling), listeners could not reliably distinguish HDA‑reconstructed signals from those produced by conventional sparse coding, yet the power consumption of a simulated neuromorphic implementation was reduced by roughly 40 %. Additional experiments with injected Gaussian noise confirm the predicted (1/\sqrt{t}) error decay, whereas competing spiking models (e.g., LCA) exhibit error saturation under the same conditions.
The paper’s key insight is that a hybrid scheme—continuous gradient descent for fine‑grained error correction combined with quantized spike‑based coordinate updates for communication—can simultaneously satisfy three desiderata: (1) provable convergence to the optimal sparse solution, (2) extreme reduction of communication bandwidth and energy, and (3) biological plausibility through an integrate‑and‑fire implementation. This bridges a gap between rigorous optimization theory and realistic neural computation.
The authors conclude by suggesting several avenues for future work: extending HDA to nonlinear or adaptive dictionaries, handling streaming data where the sparse code must be updated online, and deploying the algorithm on actual neuromorphic hardware (e.g., Intel Loihi, IBM TrueNorth) to validate the predicted energy savings in a physical system. Overall, the study provides a compelling argument that spiking neural networks can serve as efficient, scalable solvers for sparse representation problems, opening new possibilities for low‑power signal processing and for understanding how the brain may achieve its remarkable coding efficiency.
Comments & Academic Discussion
Loading comments...
Leave a Comment