An analysis of Twitter messages in the 2011 Tohoku Earthquake
Social media such as Facebook and Twitter have proven to be a useful resource to understand public opinion towards real world events. In this paper, we investigate over 1.5 million Twitter messages (tweets) for the period 9th March 2011 to 31st May 2011 in order to track awareness and anxiety levels in the Tokyo metropolitan district to the 2011 Tohoku Earthquake and subsequent tsunami and nuclear emergencies. These three events were tracked using both English and Japanese tweets. Preliminary results indicated: 1) close correspondence between Twitter data and earthquake events, 2) strong correlation between English and Japanese tweets on the same events, 3) tweets in the native language play an important roles in early warning, 4) tweets showed how quickly Japanese people’s anxiety returned to normal levels after the earthquake event. Several distinctions between English and Japanese tweets on earthquake events are also discussed. The results suggest that Twitter data can be used as a useful resource for tracking the public mood of populations affected by natural disasters as well as an early warning system.
💡 Research Summary
**
The paper presents an empirical study of Twitter activity surrounding the 2011 Tohoku earthquake, tsunami, and the subsequent Fukushima nuclear crisis, focusing on the Tokyo metropolitan area. Using the Twitter API, the authors collected all geolocated tweets posted from March 9 to May 31, 2011, resulting in a corpus of 1,660,623 messages—48,870 in English and 1,611,753 in Japanese. The study’s primary objective was to assess whether aggregated tweet volumes could serve as a real‑time indicator of public awareness, concern, and anxiety during a large‑scale natural disaster, and to compare the behavior of English‑language versus Japanese‑language users.
Data collection and preprocessing
The authors applied a geographic filter to capture only tweets originating within the Tokyo prefecture. After removing duplicates and obvious spam, they manually compiled three sets of keywords—one each for (1) earthquake and tsunami, (2) radiation, and (3) anxiety. English keywords included terms such as “earthquake,” “quake,” “tsunami,” “radiation,” “nuclear,” and “anxiety.” Japanese keywords comprised equivalents like “地震,” “津波,” “放射能,” and “怖い.” Tweets were filtered by simple substring matching, and daily frequencies were normalized by dividing the number of filtered tweets by the total number of tweets posted each day, yielding a relative event frequency f(event).
Temporal patterns for each event
- Earthquake and tsunami: The main shock occurred at 14:46 JST on March 11 (05:46 UTC). The first Japanese tweet mentioning the quake appeared at 05:48:08 UTC, roughly 1 minute 25 seconds after the event, while the earliest English tweet arrived at 05:48:54 UTC, about 2 minutes 30 seconds post‑event. Both language streams showed a sharp spike within five minutes, followed by smaller secondary peaks corresponding to aftershocks on April 7 and April 11.
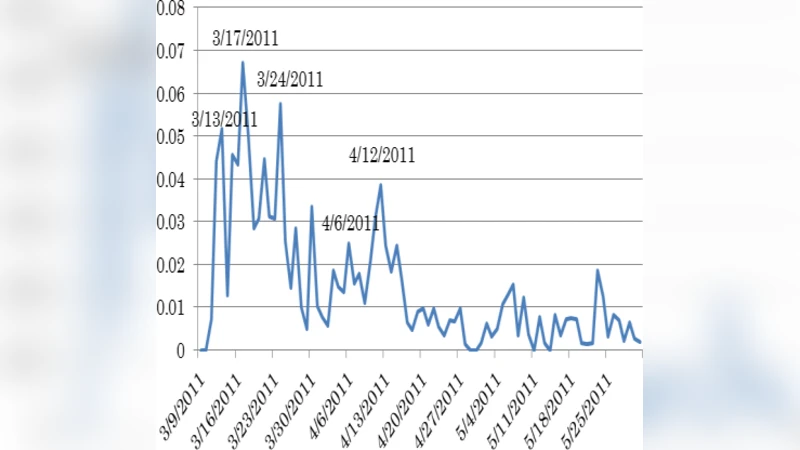
- Radiation: Significant radiation‑related incidents (hydrogen explosion on March 12, reactor meltdowns on March 15, and a later incident on April 11) produced distinct peaks. Japanese tweets surged immediately on March 12 and 15, whereas English tweets peaked one to two days later (March 13 and 17). The April 11 incident generated simultaneous peaks on April 12 in both languages. This lag suggests that local Japanese speakers perceived and reported radiation risks earlier than foreign residents.
- Anxiety: Anxiety‑related keywords spiked dramatically at the onset of the earthquake, then declined steadily over the next two weeks, reaching near‑baseline levels by late March. A modest secondary rise occurred around April 11, coinciding with renewed nuclear concerns, but the magnitude was far smaller than the initial earthquake‑related anxiety.
Cross‑language comparison
Correlation analysis revealed strong positive relationships (Pearson r > 0.85) between English and Japanese tweet frequencies for all three event categories, indicating that both language communities responded to the same real‑world stimuli. However, the absolute volume of Japanese tweets was roughly thirty times larger, underscoring the importance of native‑language data for early warning systems. Japanese tweets also contained more on‑the‑ground observations (photos, videos, eyewitness accounts), while English tweets were dominated by commentary from expatriates and international observers.
Limitations and future work
The study relied on a straightforward keyword‑matching approach, which may admit noise (e.g., unrelated uses of “quake” in marketing). The Twitter user base is not demographically representative of the entire Tokyo population, especially older adults and those without smartphones. The authors propose extending the methodology with automated term extraction, sentiment analysis, and topic modeling, as well as integrating data from other platforms (e.g., Facebook, LINE) to build a more robust, multimodal disaster surveillance framework.
Conclusions
The analysis demonstrates that Twitter activity closely mirrors the timing and intensity of major disaster events. Native‑language tweets provide a valuable early‑warning signal, often preceding English‑language reports by tens of seconds to minutes. Public anxiety, as reflected in tweet content, peaks immediately after the shock and normalizes within a fortnight, suggesting a rapid collective coping process among Tokyo residents. These findings support the incorporation of real‑time social‑media monitoring into disaster management and public‑health surveillance strategies, offering authorities a low‑cost, high‑frequency data source to gauge situational awareness and emotional wellbeing during crises.
Comments & Academic Discussion
Loading comments...
Leave a Comment