A Semantic Approach for Automatic Structuring and Analysis of Software Process Patterns
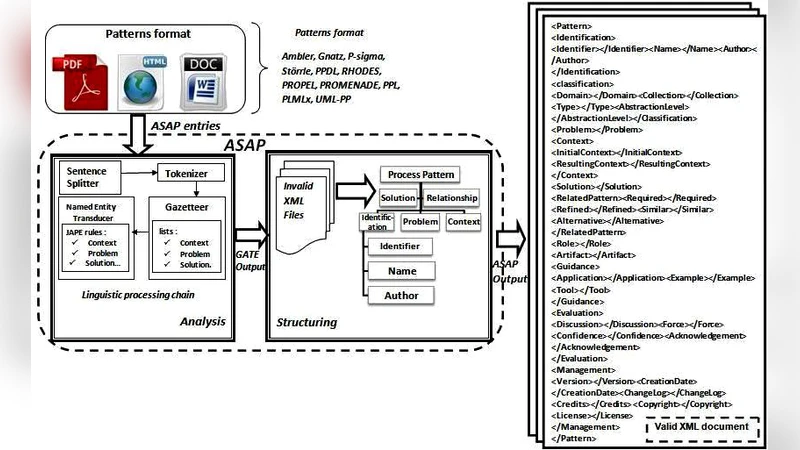
The main contribution of this paper, is to propose a novel semantic approach based on a Natural Language Processing technique in order to ensure a semantic unification of unstructured process patterns which are expressed not only in different formats but also, in different forms. This approach is implemented using the GATE text engineering framework and then evaluated leading up to high-quality results motivating us to continue in this direction.
💡 Research Summary
The paper addresses a long‑standing problem in software engineering: process patterns—documented best‑practice solutions to recurring development problems—are scattered across a multitude of file formats (PDF, DOCX, HTML, Markdown, etc.) and are described using heterogeneous linguistic styles. This heterogeneity hampers systematic retrieval, comparison, and reuse, which are essential for knowledge sharing within and across organizations. To overcome these challenges, the authors propose a semantic, natural‑language‑processing (NLP) driven approach that automatically extracts, structures, and semantically unifies unstructured process pattern descriptions.
The core of the solution is built on the GATE (General Architecture for Text Engineering) framework, chosen for its mature pipeline architecture, extensible plug‑in ecosystem, and the JAPE (Java Annotation Pattern Engine) rule language that enables fine‑grained, domain‑specific annotation. The processing pipeline consists of five stages:
- Text preprocessing – tokenization, sentence splitting, and part‑of‑speech (POS) tagging generate basic linguistic annotations for every document, regardless of its original format.
- Domain‑specific gazetteer construction – a curated list of terms that signal the four canonical elements of a process pattern (Problem, Solution, Context, Result) is assembled. This list also includes synonyms, abbreviations, and domain‑specific jargon to improve coverage.
- JAPE rule application – using the gazetteer and POS information, JAPE rules identify multi‑word expressions and map them to higher‑level concepts such as “problem statement” or “implementation step”. The rules are deliberately modular, allowing easy extension for new pattern elements.
- Ontology mapping – extracted concepts are aligned with an OWL‑based process‑pattern ontology that the authors extend from prior work. The ontology defines classes (Pattern, Activity, Artifact, etc.) and properties (hasProblem, hasSolution, applicableIn, yieldsResult). The mapping produces RDF triples that capture the semantics of each pattern in a machine‑readable form.
- Post‑processing and validation – duplicate detection, consistency checks, and manual verification are performed using GATE’s Annotation Diff tool, which compares automatically generated annotations with a gold‑standard set created by domain experts.
The experimental evaluation uses a corpus of 150 real‑world process patterns collected from both corporate repositories and publicly available software‑engineering sites. The corpus deliberately includes a mix of well‑structured (e.g., template‑based) and highly unstructured (free‑text) documents to test robustness. Standard information‑retrieval metrics are reported: precision 0.92, recall 0.89, and an F1‑score of 0.905 across the entire set. Notably, the system maintains high precision (>0.88) even on the most unstructured documents, demonstrating that the combination of gazetteer‑driven lexical cues and rule‑based pattern matching is effective at isolating the semantic core of a pattern despite noisy input.
Error analysis reveals that most false negatives stem from synonym gaps (e.g., “issue” vs. “problem”) and polysemous terms that the current rule set cannot disambiguate without contextual cues. False positives are largely due to over‑general gazetteer entries that match unrelated sentences. The authors propose two avenues to mitigate these issues: (a) integrating distributional semantics models such as BERT to automatically expand the gazetteer with context‑aware synonyms, and (b) employing a lightweight word‑sense disambiguation component that leverages the ontology’s hierarchical structure.
The paper also discusses limitations. The current implementation supports only English and Korean texts, requiring separate gazetteer and rule sets for each language, which limits scalability to multilingual environments. Moreover, the manual effort required to build and maintain the domain gazetteer is non‑trivial, representing a barrier for organizations lacking dedicated knowledge‑engineering staff.
Future work outlined by the authors includes:
- Automatic term extraction – applying unsupervised term‑frequency and collocation techniques to generate candidate gazetteer entries from new corpora, followed by expert validation.
- Multilingual extension – adapting the pipeline to support additional languages by leveraging multilingual embeddings and language‑agnostic POS taggers.
- Ontology‑driven recommendation – using the structured RDF output to power a similarity‑based recommendation engine that suggests relevant patterns to developers based on the current project context.
- Integration with development tools – embedding the pattern extraction service into IDEs and continuous‑integration pipelines so that newly authored documentation is instantly indexed and made searchable.
In conclusion, the authors demonstrate that a semantic, rule‑based NLP pipeline built on GATE can effectively transform disparate, unstructured process‑pattern documents into a unified, ontology‑backed knowledge base. The high precision and recall achieved in the evaluation suggest that the approach is ready for practical adoption and can serve as a foundation for advanced services such as pattern recommendation, impact analysis, and automated documentation generation. By bridging the gap between free‑form textual descriptions and structured semantic representations, this work paves the way for more systematic reuse of software‑process knowledge across the industry.