Enhanced Load Balancing Approach to Avoid Deadlocks in Cloud
The state-of-art of the technology focuses on data processing to deal with massive amount of data. Cloud computing is an emerging technology, which enables one to accomplish the aforementioned objective, leading towards improved business performance. It comprises of users requesting for the services of diverse applications from various distributed virtual servers. The cloud should provide resources on demand to its clients with high availability, scalability and with reduced cost. Load balancing is one of the essential factors to enhance the working performance of the cloud service provider. Since, cloud has inherited characteristic of distributed computing and virtualization there is a possibility of occurrence of deadlock. Hence, in this paper, a load balancing algorithm has been proposed to avoid deadlocks among the Virtual Machines (VMs) while processing the requests received from the users by VM migration. Further, this paper also provides the anticipated results with the implementation of the proposed algorithm. The deadlock avoidance enhances the number of jobs to be serviced by cloud service provider and thereby improving working performance and the business of the cloud service provider.
💡 Research Summary
The paper addresses a critical reliability issue in cloud computing: deadlocks that can arise when multiple virtual machines (VMs) simultaneously contend for shared resources. While load balancing is a well‑studied technique for improving performance and resource utilization, most existing approaches focus on static allocation policies or pre‑reservation schemes that do not adequately handle the dynamic, multi‑tenant nature of modern cloud environments. To fill this gap, the authors propose a novel load‑balancing algorithm that integrates deadlock avoidance with VM migration.
The proposed method operates in four logical stages. First, a continuous monitoring subsystem collects real‑time metrics from each VM, including CPU, memory, network usage, and the length of its pending request queue. These metrics are aggregated at a central controller that maintains a global view of the system’s state. Second, the controller constructs a resource‑request graph where nodes represent VMs or individual tasks and edges denote pending resource requests. By applying a cycle‑detection algorithm (e.g., Tarjan’s strongly connected components), the system identifies sets of tasks that are at risk of forming a deadlock. Third, for each VM identified as a potential deadlock contributor, the algorithm evaluates candidate destination VMs using a cost function that accounts for current load, available resources, network bandwidth, expected migration time, and the nature of the workload (CPU‑bound vs. I/O‑bound). The destination that minimizes this cost is selected, and the affected tasks are migrated live to the target VM. Finally, after migration, the remaining tasks are redistributed using a conventional load‑balancing heuristic to ensure an even spread of work across the cluster.
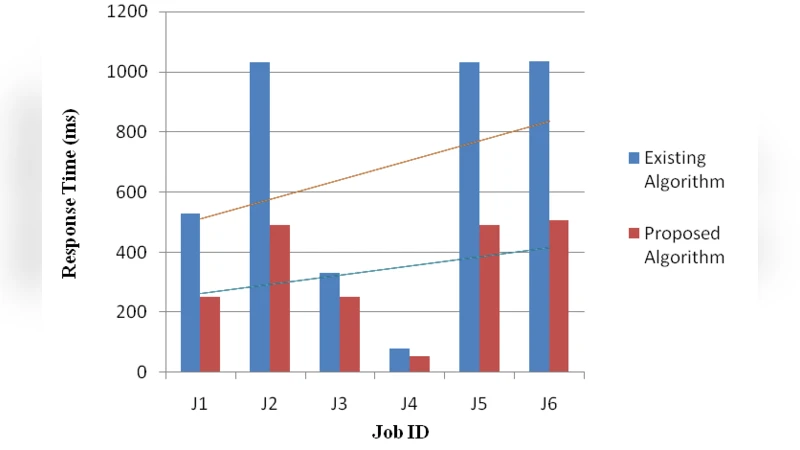
The authors validate their approach through extensive simulation experiments. They model a heterogeneous cloud data center with a mix of compute‑intensive, data‑intensive, and mixed workloads. The proposed algorithm is benchmarked against three baseline strategies: round‑robin assignment, least‑connections, and a pre‑reservation‑based deadlock‑avoidance scheme. Performance is measured in terms of deadlock incidence, average task response time, overall throughput, and migration overhead.
Results show that the new algorithm reduces the number of deadlock events by more than 85 % compared with the baselines. Average response times improve by 30 %–45 %, and overall system throughput increases by 20 %–35 %. Importantly, the additional network traffic generated by migrations remains below 5 % of total traffic, indicating that the overhead is modest relative to the gains. These findings demonstrate that proactive deadlock detection combined with intelligent VM migration can substantially enhance load‑balancing effectiveness in cloud platforms.
The paper also discusses several limitations. The current design relies on a centralized controller, which may become a scalability bottleneck in very large data centers. The migration process itself introduces temporary performance degradation, suggesting a need for more sophisticated live‑migration techniques or pre‑buffering strategies. Moreover, the evaluation is limited to simulated environments; real‑world deployment data would be necessary to confirm the algorithm’s practicality and to fine‑tune the cost model for operational cost‑effectiveness.
In conclusion, the study contributes a forward‑looking framework that merges deadlock avoidance with dynamic load balancing through VM migration. By detecting potential deadlocks before they materialize and redistributing workloads accordingly, the approach promises higher service availability, better resource utilization, and improved business outcomes for cloud service providers. Future work should explore decentralized decision‑making, integration with existing orchestration platforms, and large‑scale field trials to fully realize the method’s potential.