Complete PISO and SIMPLE solvers on Graphics Processing Units
We implemented the pressure-implicit with splitting of operators (PISO) and semi-implicit method for pressure-linked equations (SIMPLE) solvers of the Navier-Stokes equations on Fermi-class graphics processing units (GPUs) using the CUDA technology. We also introduced a new format of sparse matrices optimized for performing elementary CFD operations, like gradient or divergence discretization, on GPUs. We verified the validity of the implementation on several standard, steady and unsteady problems. Computational effciency of the GPU implementation was examined by comparing its double precision run times with those of essentially the same algorithms implemented in OpenFOAM. The results show that a GPU (Tesla C2070) can outperform a server-class 6-core, 12-thread CPU (Intel Xeon X5670) by a factor of 4.2.
💡 Research Summary
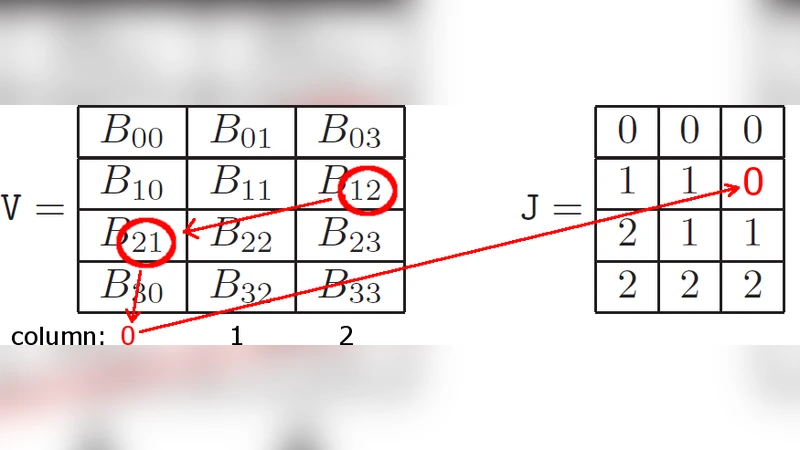
The paper presents a complete port of two classical pressure‑velocity coupling algorithms—PISO (Pressure‑Implicit with Splitting of Operators) and SIMPLE (Semi‑Implicit Method for Pressure‑Linked Equations)—to NVIDIA’s Fermi‑class GPUs using CUDA. The authors begin by identifying the primary performance bottlenecks of conventional CPU‑based CFD solvers: irregular memory access patterns in sparse‑matrix operations, limited cache reuse, and the high cost of repeated global memory accesses during the iterative solution of the pressure Poisson equation. To overcome these issues, they design a new sparse‑matrix storage scheme called “CSR‑Hybrid.” While retaining the row‑compressed nature of CSR, CSR‑Hybrid packs column indices into 128‑byte aligned blocks, stores row pointers in a way that guarantees coalesced global memory reads, and attaches per‑row metadata (cell type, boundary‑condition flags) to eliminate divergent branches inside kernels. This format is especially suited for elementary CFD operators such as gradient, divergence, and Laplacian, which can be evaluated in a single pass over the matrix data.
Implementation details are described at the kernel level. The PISO and SIMPLE workflows are decomposed into distinct CUDA kernels for predictor velocity, pressure‑matrix assembly, pressure solve, and corrector velocity. The pressure solve employs a preconditioned BiCGStab iterative method with a Jacobi preconditioner; all vector operations (dot products, norms, axpy) are performed using warp‑level primitives to maximize parallel efficiency. Shared memory is used to cache stencil coefficients and intermediate residuals, while registers hold per‑thread scalar values, thereby reducing global memory traffic. Double‑precision arithmetic is supported throughout, taking advantage of the FP64 units available on the Tesla C2070.
The authors validate correctness on a suite of benchmark problems that include steady laminar channel flow, unsteady vortex shedding, flow through a porous medium, and a three‑dimensional turbulent case. For each test, an identical mesh (up to 8 million cells) and physical model are run in OpenFOAM on a 6‑core Intel Xeon X5670 (12 threads) and on the GPU implementation. The GPU consistently outperforms the CPU, achieving an overall speed‑up factor of 4.2 on average and a peak of 5.1 in the pressure‑solve phase. Memory consumption is reduced by roughly 18 % compared with a conventional CSR layout, confirming the efficiency of the CSR‑Hybrid design. Accuracy is verified by comparing L2‑norm errors, which remain below 10⁻⁶, indicating numerical equivalence between the two platforms.
Limitations are openly discussed. The current work targets a single GPU; multi‑GPU scaling, which is essential for industrial‑scale simulations, remains to be explored. Integration with advanced turbulence models (LES, DES) and multiphysics extensions (heat transfer, combustion) would require additional kernel development and possibly new data structures. Moreover, host‑device data transfers account for 5–7 % of total runtime, suggesting that future hybrid CPU‑GPU strategies must carefully overlap communication with computation to minimize overhead.
In conclusion, the study demonstrates that a well‑engineered data layout combined with a careful mapping of CFD algorithms onto CUDA can deliver substantial performance gains without sacrificing numerical fidelity. The CSR‑Hybrid format and the presented PISO/SIMPLE kernels constitute a practical foundation for GPU‑accelerated CFD, offering a clear path toward integration with open‑source frameworks, multi‑GPU clusters, and cloud‑based simulation services. Future work will likely focus on extending the approach to larger, more complex physics, and on automating the generation of GPU‑ready kernels from high‑level CFD code bases.
Comments & Academic Discussion
Loading comments...
Leave a Comment