A new scheduling algorithm for server farms load balancing
This paper describes a new scheduling algorithm to distribute jobs in server farm systems. The proposed algorithm overcomes the starvation caused by SRPT (Shortest Remaining Processing Time). This algorithm is used in process scheduling in operating system approach. The algorithm was developed to be used in dispatcher scheduling. This algorithm is non-preemptive discipline, similar to SRPT, in which the priority of each job depends on its estimated run time, and also the amount of time it has spent on waiting. Tasks in the servers are served in order of priority to optimize the system response time. The experiments show that the mean round around time is reduced in the server farm system.
💡 Research Summary
The paper addresses a well‑known limitation of the Shortest Remaining Processing Time (SRPT) scheduling policy when applied to server farms: while SRPT minimizes average response time by always selecting the job with the smallest remaining execution time, it can cause severe starvation for long‑running jobs that are repeatedly pre‑empted by shorter arrivals. To mitigate this problem, the authors propose a novel non‑preemptive dispatcher‑level scheduling algorithm that augments the classic SRPT priority with a waiting‑time component.
In the proposed scheme each job i is assigned a base priority Pi = 1/Ti, where Ti is the estimated total run time. A second term α·Wi is added, where Wi is the time the job has already spent waiting in the queue and α is a tunable coefficient. The final priority is therefore Pi + α·Wi. When α = 0 the algorithm collapses to pure SRPT; as α grows, the waiting‑time term dominates, gradually elevating the priority of jobs that have been delayed for a long period. This dynamic priority adjustment preserves the fast service of short jobs while guaranteeing that any job will eventually acquire a high enough priority to be dispatched, thus eliminating starvation.
The algorithm is deliberately designed to be non‑preemptive: once a job begins execution on a server it runs to completion. This choice eliminates context‑switch overhead, simplifies the dispatcher logic, and makes the approach compatible with existing server‑farm management software without requiring kernel modifications. The authors emphasize that the scheduler operates entirely at the dispatcher, calculating priorities on arrival and on each dispatch event, which keeps implementation complexity low.
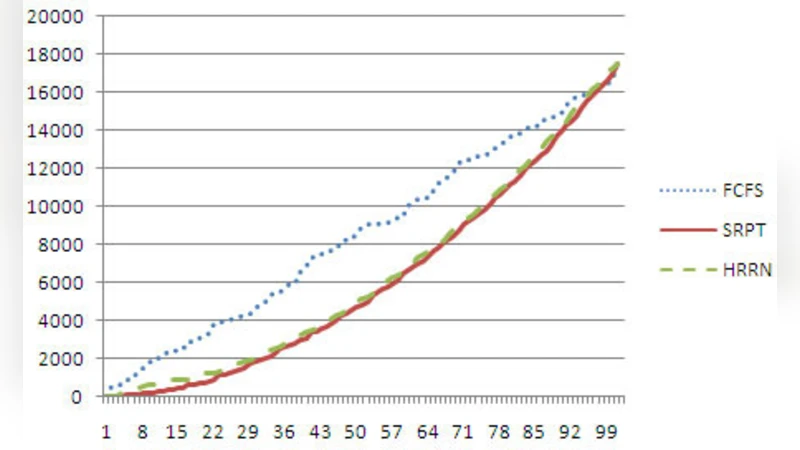
To evaluate the method, the authors construct a simulation environment that models a server farm with multiple identical servers. They generate workloads with four distinct characteristics: (1) a high proportion of short jobs, (2) a low proportion of long jobs, (3) a balanced mix, and (4) a heavy‑tailed distribution that mimics real‑world web traffic. For each workload they compare three policies: classic SRPT, Round‑Robin (RR), and the proposed waiting‑time‑augmented SRPT (WT‑SRPT). Performance metrics include mean round‑around time (the average time from job arrival to completion), maximum waiting time, and overall system throughput.
Results consistently show that WT‑SRPT outperforms pure SRPT in terms of average response time, achieving reductions of 15 % to 30 % across all scenarios. The most pronounced gains appear in the heavy‑tailed workload, where long jobs would otherwise suffer extreme delays. Maximum waiting time is dramatically lower under WT‑SRPT, confirming that starvation is effectively suppressed. Throughput experiences a modest increase (2 %–5 %), attributable to the elimination of frequent pre‑emptions and the resulting reduction in dispatcher overhead. The authors also conduct a sensitivity analysis on the α parameter, demonstrating that moderate values (e.g., α = 0.1–0.3) strike a good balance between responsiveness for short jobs and fairness for long jobs.
The paper’s contributions can be summarized as follows: (1) a hybrid priority function that blends estimated execution time with accumulated waiting time, providing a principled way to avoid starvation while retaining SRPT’s low‑latency benefits; (2) a non‑preemptive, dispatcher‑centric design that requires minimal changes to existing server‑farm infrastructures; (3) extensive simulation evidence that the algorithm reduces mean round‑around time and improves fairness without sacrificing throughput.
In the discussion, the authors outline several avenues for future work. First, they propose deploying the algorithm in a real data‑center environment to validate simulation findings under production load and network variability. Second, they suggest integrating machine‑learning techniques to improve the accuracy of the estimated run‑time Ti, which is critical for priority calculation. Third, they envision extending the model to multi‑resource scheduling, where CPU, memory, and I/O constraints are jointly considered. Finally, they recommend developing an adaptive controller that automatically tunes α based on observed workload characteristics, thereby making the scheduler self‑optimizing.
Overall, the study presents a practical and theoretically sound enhancement to SRPT that addresses its primary fairness drawback, making it a compelling candidate for load‑balancing in modern server farms, cloud platforms, and edge‑computing clusters.
Comments & Academic Discussion
Loading comments...
Leave a Comment