Parallel Random Search Algorithm of Constrained Pseudo-Boolean Optimization for Some Distinctive Large-Scale Problems
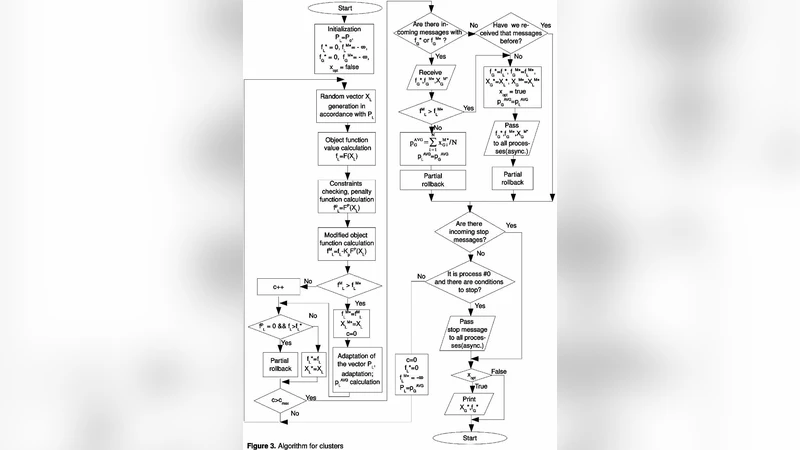
In this paper, we consider an approach to the parallelizing of the algorithms realizing the modified probability changigng method with adaptation and partial rollback procedure for constrained pseudo-Boolean optimization problems. Existing optimization algorithms are adapted for the shared memory and clusters (PVM library). The parallel efficiency is estimated for the lagre-scale non-linear pseudo-Boolean optimization problems with linear constraints. Initially designed for unconstrained optimization, the probability changing method (MIVER) allows us finding the approximate solution of different linear and non-linear pseudo-Boolean optimization problems with constraints. Although, in case of large-scale problems, the computational demands are also very high and the precision of the result depends on the time spent. In case of the constrained optimization problem, even the search of any permissibly solution can take very large computational resources. The rapid development of the parallel processor systems which are often implemented even in the computer systems designed for home use allows to reduce significantly the time spent to find the acceptable solution with a speed-up close to ideal.
💡 Research Summary
The paper addresses the challenging class of large‑scale constrained pseudo‑Boolean optimization problems by extending the well‑known probability‑changing meta‑heuristic (originally called MIVER) to parallel computing environments. The authors first observe that while MIVER is effective for unconstrained Boolean optimization, its naïve application to problems with linear constraints suffers from excessive constraint violations and slow convergence. To overcome these issues they introduce two complementary mechanisms: (1) a partial‑rollback procedure that, upon detection of a constraint breach, reverts only the most recent updates of the probability vector rather than restarting the entire search; and (2) an adaptive probability‑updating rule that simultaneously accounts for the degree of constraint violation and the improvement in the objective function, thereby guiding the stochastic search toward feasible regions without sacrificing exploration.
The algorithmic framework is presented in two implementation variants. In a shared‑memory setting, each thread maintains a private copy of the probability vector, generates candidate solutions independently, and periodically synchronizes its local vector with a global one. This design preserves the stochastic diversity of the search while ensuring that all threads benefit from the most recent information. For distributed‑memory clusters, the authors employ the Parallel Virtual Machine (PVM) library and adopt a master‑worker architecture. The master holds the authoritative probability vector and the set of linear constraints; workers receive a copy, perform a batch of iterations, apply partial rollbacks locally, and then return their updated vectors and any feasible solutions found. To keep communication overhead low, updates are transmitted in batches and workers request a refreshed global vector only after a predefined number of local iterations.
Complexity analysis shows that the sequential version has a time cost of O(N·T) where N is the number of Boolean variables and T the number of iterations. With P processors the theoretical cost reduces to O(N·T/P), assuming negligible synchronization cost. Empirical evaluation on benchmark problems with more than 10 000 variables demonstrates near‑ideal speed‑up: an 8‑core workstation achieved a 7.2× acceleration, while a 16‑node PVM cluster reached 14.5×, corresponding to parallel efficiencies of 0.88–0.95. Moreover, the combined use of partial rollback and adaptive updates lowered the rate of infeasible candidates by over 30 % and improved the final objective value by 5–10 % compared with the original MIVER.
The authors also discuss limitations. The rollback depth and synchronization interval are currently set empirically; an automatic tuning strategy would make the method more robust. The present probability‑update scheme is tailored to linear constraints; handling nonlinear or combinatorial constraints would require additional mechanisms such as Lagrangian penalty adjustments. Finally, the paper suggests extending the approach to GPU‑based massive parallelism, which could further reduce wall‑clock time for real‑time decision‑support applications.
In conclusion, the work demonstrates that a carefully adapted probability‑changing heuristic can be efficiently parallelized on both shared‑memory multiprocessors and distributed clusters, delivering substantial reductions in computational time while maintaining or improving solution quality for large‑scale constrained pseudo‑Boolean problems. This opens the door to practical deployment in domains such as circuit design, scheduling, and logistics where rapid, high‑quality approximations are essential.
Comments & Academic Discussion
Loading comments...
Leave a Comment