High-dimensional structure estimation in Ising models: Local separation criterion
We consider the problem of high-dimensional Ising (graphical) model selection. We propose a simple algorithm for structure estimation based on the thresholding of the empirical conditional variation distances. We introduce a novel criterion for tract…
Authors: Animashree An, kumar, Vincent Y. F. Tan
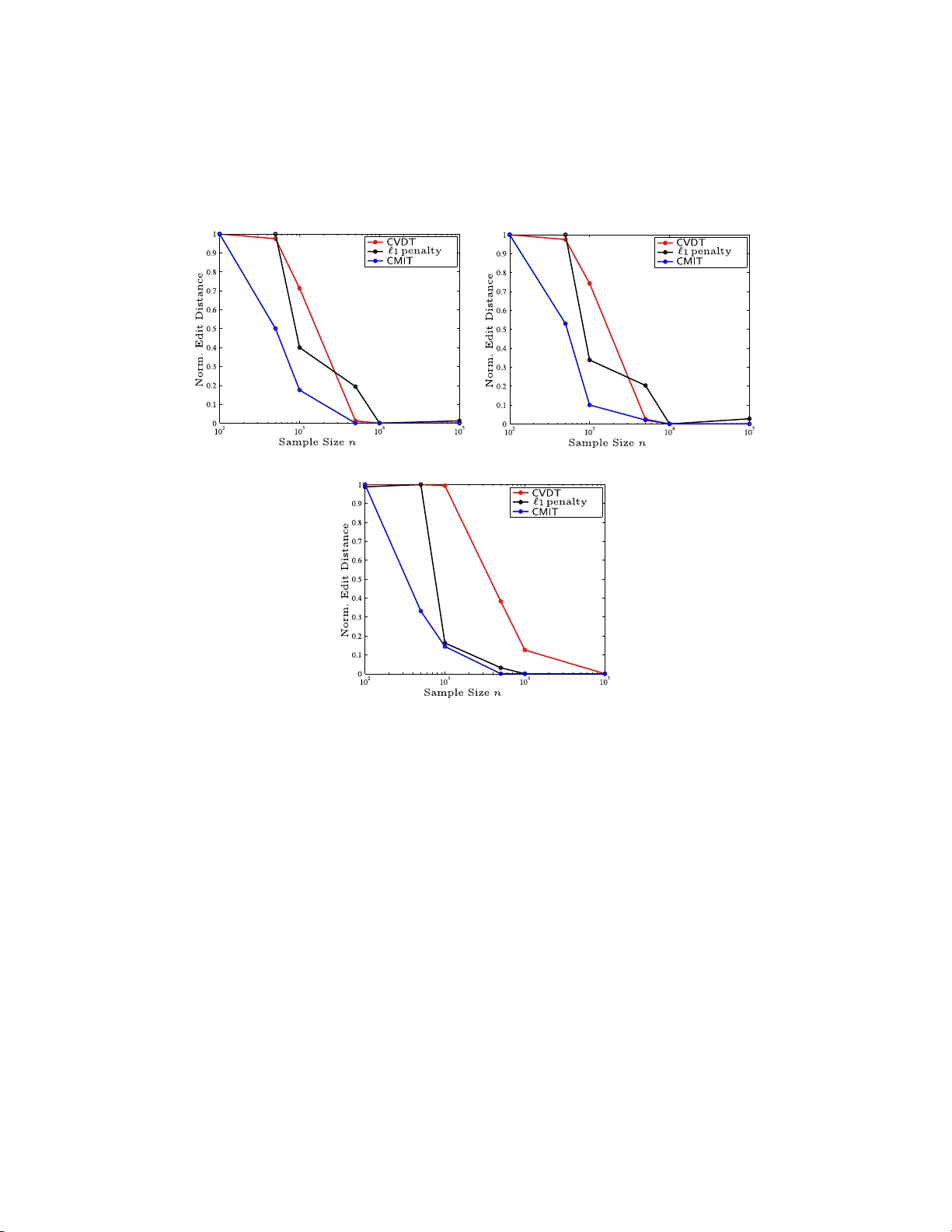
The Annals of Statistics 2012, V ol. 40, No. 3, 1346–13 75 DOI: 10.1214 /12-AOS1009 c Institute of Mathematical Statistics , 2 012 HIGH-DIMENSIONAL STR UCTURE E STIMA TION IN ISING MODELS: LOCAL SEP ARA TION CRITERION 1 By Animashree Anandk umar 2 , Vincent Y. F. T an 3 , 4 , Furong Huang 2 and Alan S. Willsky 4 University of California Irvine, Institute for Info c omm R ese ar ch and National University of Singap or e, University of California Irvine and Massachusetts Institute of T e c hnolo gy W e consider th e problem of high-dimensional Ising (graphical) mod el selection. W e prop ose a simple algorithm for structure esti- mation based on the th resholding of the empirical conditional v ari- ation d istances. W e introduce a nov el criterion for tractable graph families, where this metho d is efficient, based on the presence of sparse local separators b etw een no de pairs in the underlying graph. F or su ch graphs, the prop osed algorithm h as a sample complexity of n = Ω( J − 2 min log p ), where p is the num b er of v ariables, and J min is the minim um (absolute) edge p otential in the mo del. W e also estab- lish nonasymptotic n ecessary and sufficient conditions for structure estimation. 1. In tro duction. The use of p robabilistic grap h ical mo dels allo w s f or su c- cinct representati on of high-d imensional distrib utions, where the conditional- indep en d ence relationships among the v ariables are r epresent ed by a graph . Suc h mo dels ha ve f ou n d many applications in a v ariety of areas, includ- ing computer vision [ 14 ], bio-informatics [ 21 ], financial mo deling [ 15 ] and so cial net works [ 25 ]. F or instance, graphical m o dels are employ ed for con- textual ob ject r ecognition to imp ro v e detection p erformance based on ob- ject co-o ccurrences [ 14 ] and for mo d eling opinion formation and tec hnology adoption in so cial netw orks [ 25 , 30 ]. 1 An abridged versi on of this pap er app ears in Pro c. of N IPS 2011. 2 Supp orted by t h e setup funds at UCI and the AFOSR Award F A9550-10-1-0310. 3 Supp orted in part by A*ST AR, Singap ore. 4 Supp orted in part by AF OSR under Grant F A9550-08-1-1080. AMS 2000 subje ct classific ations. Primary 62H12; secondary 05C80. Key wor ds and phr ases. I sing models, graphical model selection, lo cal-separation prop- erty . This is an electronic repr int of the or iginal a r ticle publis he d by the Institute of Mathematical Statistics in The Annals of Statistics , 2012, V o l. 40, No. 3, 1 346–1 375 . This reprint differs fro m the o riginal in pagination a nd typo graphic detail. 1 2 ANAND KUMAR, T AN, HU ANG AND WILLSKY A ma jor c hallenge inv olving graphical mo dels is structur e estimation, giv en samples dra wn from the mo d el. It is kno wn th at such a learnin g task is NP-hard [ 7 , 27 ]. Th is c hallenge is comp ound ed in the high-dimensiona l regime, w here the num b er of a v ailable ob s erv ations is t ypically m uch smaller than the num b er of d imensions (or v ariables). It is th us imp erativ e to d e- sign efficien t algorithms for structur e estimation of graph ical mo dels with lo w sample complexit y . In their seminal wo rk, Ch o w and Liu p resen ted an efficien t algorithm for structure estimatio n of tree-structured graphical mo dels b ased on a max- im um w eigh t spanning tree algorithm [ 16 ]. Since then, v arious algorithms ha v e b een prop osed for stru cture estimation of s parse graphical mo dels. They can b e b roadly classified in to tw o categories: com binatorial algorithms [ 10 , 39 ] and those b ased on con vex relaxatio n [ 11 , 37 , 41 , 42 ]. The former ap- proac h is typica lly based on certain lo cal tests on sm all group s of d ata, and then com bining them to outpu t a graph s tr ucture, while the latter approac h in v olv es solving a p enalized con v ex optimization pr oblem. See Section 1.2 for a detailed discussion of these appr oac hes. In this pap er, we prop ose a nov el lo cal algorithm and analyze its p erfor- mance for structur e estimation of Ising mo dels, whic h are p airwise b inary graphical mo dels. Our p rop osed algorithm circum ve nts one of the primary limitations of existing lo cal algorithms [ 10 , 39 ] for consisten t estimation in high-dimensions—that the graphs hav e a b ounded degree as the num b er of no des p tends to in fi nit y . W e giv e a pr ecise c haracterization of the class of graphs wh ic h can b e consisten tly reco vered by our algorithm with lo w com- putational and sample complexitie s. W e demonstrate that a fundamenta l prop erty shared b y these graph s is that they ha v e sp arse lo c al vertex sep a- r ators b etw een an y t w o n onneigh b ors in the graph . A wide v ariet y of grap h s satisfy this prop ert y . These includ e large girth graph s, the Erd˝ os–R ´ en yi ran- dom graph s 5 [ 8 ] and th e p o wer-la w graphs [ 18 ], as well as graphs with short cycles suc h as the sm all-w orld graphs [ 51 ] and other hybrid graphs [ 18 , Chapter 12]. Our results are applicable in the realms of so cial netw orks, bio-informatics, computer vision and so on. Here, we elab orate on its relev ance to so cial net- w orks. The aforementio ned graph s (i.e., th e p o wer-la w and the small-wo rld graphs) ha v e b een emplo y ed extensiv ely for mo deling th e top ologies of so- cial netw orks [ 2 , 40 ]. More recent ly , Ising mo dels on suc h top ologies ha ve b een emplo yed for m o deling v arious ph enomena in so cial net w orks [ 48 ], suc h as opin ion formation [ 23 , 25 , 34 ] and tec h nology adoption [ 30 ]. A concrete example is the use of an Is ing mo del for the U.S . senate v oting netw ork [ 52 ]. 5 The Erd˝ os–R ´ enyi graphs hav e sparse lo cal vertex separators asymptotically almost surely (a.a.s.) with resp ect t o the random graph measure. I ndeed, whenever we m ention ensem bles of random graphs in the sequ el, our statemen ts are taken to hold a.a.s. STRUCTURE LEAR NING OF ISIN G MOD ELS 3 The no d es of th e graph repr esen t the s en ators, and the data are the vo t- ing decisions m ade b y the senators. Estimating the graph r ev eals interesting relationships b et wee n the senators and the effect of p olitical affiliatio ns on their decisions. Similarly , in many other scenarios (e.g., online so cial net- w orks), we ha v e access to a sequence of measur emen ts at the no des of the net w ork. F or instance, we ma y gather the opinions of different users or mea- sure the p opu larity of new tec hn ologies. As a fir st-order approximat ion, we can regard suc h a sequence of measuremen ts as b eing indep endent and iden- tically d istributed (i.i.d.) samples dr a w n from an Ising mo del. Ou r find ings imply that the topology of suc h so cial-net w ork mo dels can b e efficien tly estimated un der some mild an d tr an s paren t conditions. 1.1. Summary of r esults. Our main cont ribu tions in this work are thr ee- fold. W e prop ose a simple algorithm for structure estimation of Ising mo d - els. Th e algorithm is b ased on app ro ximate conditional indep endence testing based on cond itional v ariation distances. Second, we d eriv e sample complex- it y results for consistent structur e estimation in high dimensions . Third, w e pro ve no vel lo wer b oun ds on the sample complexit y requ ired for any learning algorithm to b e consistent for m o del selection. W e prop ose an algorithm for structure estimation, termed as conditional v ariation d istance thresholdin g ( CVDT ), which tests if tw o n o des are neigh- b ors b y searching for a no de set wh ich (appro ximately) separates them in the und er lyin g Marko v graph. It first computes the minimum empirical con- ditional v ariation distance in ( 14 ) of a giv en no de pair o v er conditioning sets of b oun ded cardinalit y η . Second, if the minim um exceeds a giv en thr eshold (dep endin g on th e n umb er of samples n and th e n umb er of no des p ), the no de pair is declared as an edge. This test has a computational complexit y of O ( p η +2 ). Thus, the computational complexit y is lo w if η is small. F urther, it requires only low-order statistics (up to ord er η + 2). W e establish th at the p arameter η is a b ound on the size of lo cal v ertex-separators b et wee n an y t w o nonneighbors in the graph, and is small for many common graph families, introd u ced b efore. W e establish that under a set of mild and transparen t assumptions, struc- ture learning is consisten t in h igh dimensions for CVDT w hen the num b er of samples scales as n = Ω( J − 2 min log p ), for a p -no de graph, wh ere J min is the minimum (absolute) edge-p otentia l of the Ising mo del. W e relate the conditions for s uccessful graph r eco very to certain p hase transitions in the Ising mo del. W e also deriv e (nonasymptotic) P AC guaran tees for CVDT and pro vide explicit resu lts for sp ecific graph families. W e derive a lo wer b ound (necessary condition) on th e sample complexit y required for consisten t stru cture learning with p ositiv e p robabilit y by any algorithm. W e p ro v e that n = Ω( c log p ) n umb er of samples is requir ed by an y algorithm to ensure consisten t learnin g of Erd˝ os–R ´ en yi rand om graphs , 4 ANAND KUMAR, T AN, HU ANG AND WILLSKY where c is the av erage d egree, and p is the num b er of no des. W e also pr esent a n onasymptotic n ecessary condition whic h emplo ys information-theoretic tec hn iques s uc h as F ano’s inequ alit y and t ypicalit y . W e also provide results for other graph families suc h as the girth-constrained graphs and augment ed graphs. Our results ha v e several r amifications: we charact erize the trade-off b e- t w een v arious graph parameters, su c h as the maxim um d egree, threshold for lo cal path length an d the strength of edge p otentia ls for efficien t and consis- ten t structure estimation. F or instance, we establish a n atural r elationship b et wee n maxim um d egree and girth of a graph for consisten t estimat ion: graphs with large degrees can b e consisten tly estimated by our algorithm when they also hav e large girths. Ind eed, in the extreme case of trees wh ic h ha v e infin ite girth, they can b e consisten tly estimated with no constraint on the no d e degrees, corrob orating the initial observ ation by C ho w and Liu [ 16 ]. W e also d eriv e stronger guarante es for man y rand om-graph families. F or in- stance, for the Erd˝ os–R ´ en yi random grap h family and the small-wo rld f am- ily (which is the union of a d -dimensional grid and an Erd˝ os–R ´ en y i random graph), the minim um sample complexity scales as n = Ω( c 2 log p ) , where c is the a v erage degree of the E rd˝ os–R ´ enyi random graph. Thus, when the a v- erage degree is b ounded [ c = O (1)], the sample complexit y of our algorithm scales as n = Ω (log p ) . Recall that the sample complexit y of learning tree mo dels is Ω(log p ) [ 47 ]. Thus, we establish that the complexit y of learnin g sparse r andom graphs using the p r op osed algorithm is akin to learning tree mo dels in certain parameter regimes. Our sufficien t conditions for consistent stru cture estimation imp ose trans- paren t constraints on the graph s tructure and the p arameters. The struc- tural prop erty is related to the presence of sparse local ve rtex separato rs b et wee n nonadjacent no de pairs in the graph . The conditions on the param- eters r equire that the edge p oten tials of the Isin g mo d el b e b elo w a certain threshold, which w e explicitly c haracterize. In fact, we establish that b e- lo w this threshold, the effect of long-range paths in the mo d el deca ys and that graph estimation is f easible via lo cal conditioning, as p rescrib ed by our algorithm. Similar notions ha v e been previously established in other con- texts, for example, to establish p olynomial m ixing time f or Gibbs sampling of the Ising mo del [ 32 ]. W e compare th ese different criteria and s h o w that w e can guaran tee consisten t learning in h igh dimensions u nder we ak er con- ditions than those r equired for p olynomial mixing of Gibbs samp lin g. Our s is the first work (to the b est of th e authors’ knowledge ) to establish su c h explicit connections b etw een stru cture estimation and the statistica l physics prop erties (i.e., phase transitions) of Ising m o dels. Establishing these results requires the dev elopment and us e of tools (e.g., self-a voiding w alk trees), not previously emplo yed for learning problems. STRUCTURE LEAR NING OF ISIN G MOD ELS 5 1.2. R elate d work. The pr oblem of stru cture estimation of a general graphical m o del [ 7 , 27 ] is NP-hard. Ho wev er, for tree-structured graphi- cal mo dels, the maxim um-like liho o d (ML) estimation can b e implemented efficien tly via the Chow–Liu algorithm [ 16 ] since ML estimation r educes to a maximum-w eight sp anning tree problem w here the edge weigh ts are the empirical mutual in formation quantitie s, computed from s amp les. It can b e established that the samp le complexit y for the Cho w–Liu algorithm scales as n = Ω(log p ), where p is the n umber of v ariables [ 47 ]. Error-exp on ent analysis of the Cho w–Liu algorithm was p erf ormed in [ 45 , 46 ], and exten- sions to general acyclic mo dels [ 33 , 47 ] and trees with laten t (or hidden) v ariables [ 15 ] hav e also b een studied recen tly . Giv en the feasibilit y of s tructure learning of tree mo dels, a natural ex- tension is to co nsider learning the structures of junction tr e es . 6 Efficien t algorithms hav e b een pr eviously p r op osed f or learnin g jun ction trees with b ound ed treewidth (e.g., [ 12 ]). Ho w ev er, th e complexit y of these algorithms is exp onent ial in the tree width, and h ence are not practical when the graph s ha v e unb ounded treewidth . 7 There are m ainly t w o classes of algorithms for graphical mo del selection: lo cal-searc h based approac hes [ 10 , 39 ] and those based on con v ex op timiza- tion [ 11 , 37 , 41 , 42 ]. The latter approac h typical ly incorp orates an ℓ 1 p enalt y term to encourage sp arsit y in the graph stru ctur e. In [ 41 ], structure estima- tion of Ising mo dels is co nsid er ed where neigh b orho o d sele ction for eac h no de is p erformed, b ased on ℓ 1 -p enalized logistic regression. It w as shown that th is algorithm has a sample complexit y of n = Ω(∆ 3 log p ) und er a set of so-called “incoherence” conditions. Ho wev er, th e incoherence cond itions are not easy to in terpret and NP-hard to verify in general mo dels [ 6 ]. F or more detailed comparison, see S ection 3.5 . In con trast to con ve x-relaxation app roac h es, the local-searc h based ap- proac h relies on a series of simple lo cal tests for n eigh b orho o d selection at individual no des. F or instance, the work in [ 10 ] p erforms neigh b orh o o d se- lection at eac h no d e based on a series of cond itional-indep endence tests. Abb eel et al. [ 1 ] p rop ose an algorithm, similar in sp irit to learning fac- tor graphs with b ound ed degree. The authors in [ 44 ] and [ 13 ] consider conditional-indep endence tests f or learnin g Ba y esian netw orks. I n [ 39 ], the authors s uggest an alternativ e, greedy algorithm, based on m inimizing con- ditional entrop y , for graphs w ith large girth and b ounded degree. Ho w ev er, 6 Junction trees are formed by triangulating a given graph, and its n od es corresp ond to the maximal cliques of the triangulated graph [ 49 ]. The tr e ewidth of a graph is one less than the minimum p ossible size of the maximum clique in the triangulated graph ov er all p ossible triangulations. 7 F or instance, it is k nown that for a Erd˝ os–R ´ enyi random graph G p ∼ G ( p, c/p ) when ( c > 1), the tree-width is greater than p ε , for some ε > 0 [ 29 ]. 6 ANAND KUMAR, T AN, HU ANG AND WILLSKY these works [ 1 , 10 , 13 , 39 , 44 ] requ ire the maxim um d egree in the graph to b e b ounded (∆ = O (1)) which may b e r estrictiv e in pr actical scenarios. W e consider graphical mo del select ion on grap h s where the maximum degree is allo we d to grow with the n umb er of no des (alb eit at a con trolled r ate). Moreo ver, w e establish a natural trade-off b et ween the maxim um degree and other parameters of the graph (e.g., girth) requir ed for consistent structure estimation. Necessary conditions on structure learning pr o vide lo we r b ounds on the sample complexit y for stru ctur e learning and hav e b een studied in [ 38 , 43 , 50 ]. Ho wev er, a standard assumption that these works mak e is that the u n- derlying set of graphs is un if orm ly distribu ted with b ounded d egree. F or this scenario, it is sh o wn that n = Ω(∆ k log p ) samples are required for consisten t structure estimation, for a graph with p n o des and maxim um degree ∆ , f or some k ∈ N , sa y k = 3 or 4. In con trast, our conv erse r esu lt is stated in terms of the aver age de gr e e , instead of the m axim um degree. 2. System mo del. In th is section, we defi ne the relev an t notation to b e used in th e rest of the pap er. 2.1. Notation. W e introdu ce s ome b asic n otions. Let k · k 1 denote the ℓ 1 norm. F or an y t w o discrete distr ib utions P , Q on the same alphab et X , the total v ariation distance is giv en by ν ( P , Q ) := 1 2 k P − Q k 1 = 1 2 X x ∈X | P ( x ) − Q ( x ) | , (1) and the Kullbac k–Leibler d istance (or relativ e en tropy) is giv en by D ( P k Q ) := X x ∈X P ( x ) log P ( x ) Q ( x ) . Giv en a p air of d iscrete random v ariables ( X, Y ) taking v alues on the set X × Y and distributed as P = P X,Y , the mutual i nf ormation is defi n ed as I ( X ; Y ) := D ( P ( x, y ) k P ( x ) P ( y )) = X x ∈X ,y ∈Y P ( x, y ) log P ( x, y ) P ( x ) P ( y ) . (2) Along s imilar lines, the c onditional mutual information of X and Y giv en another random v ariable Z , taking v alues on a coun table set Z , is defined as I ( X ; Y | Z ) := X x ∈X ,y ∈Y ,z ∈Z P ( x, y , z ) log P ( x, y | z ) P ( x | z ) P ( y | z ) . (3) It is also well kn o wn that I ( X ; Y | Z ) = 0 if and only if X and Y are inde- p end ent giv en Z , that is, P ( x, y | z ) = P ( x | z ) P ( y | z ) . STRUCTURE LEAR NING OF ISIN G MOD ELS 7 Giv en n s amples drawn i.i.d. from P ( x, y ) , denoted b y ( x n , y n ) = { ( x i , y i ) } n i =1 , the (joint ) empiric al distribution or the (join t) typ e is defined as b P n ( x, y ; x n , y n ) := 1 n n X i =1 I { ( x, y ) = ( x i , y i ) } . (4) W e lo osely u se the term empiric al distanc e to r efer to distance s b et ween empirical d istributions. F or instance, the empirical v ariation d istance is giv en b y ν ( b P n , b Q n ) := 1 2 X x ∈X | b P n ( x ) − b Q n ( x ) | . (5) Our algorithm for graph estimation w ill b e based on empirical v ariation dis- tance b et wee n conditional distr ib utions. W e emp lo y suc h empirical estimates for testing conditional ind ep endencies b etw een sp ecific distrib utions. 2.2. Ising mo dels. A gr aphic al mo del is a family of multiv ariate distrib u- tions whic h are Marko v in accordance to a p articular undir ected graph [ 31 ]. Eac h no de in the graph i ∈ V is asso ciated to a random v ariable X i , taking v alue in a set X . The set of edges 8 E ⊂ ( V 2 ) captures the s et of conditional- indep en d ence relationships among the ran d om v ariables. W e sa y that a v ec- tor of random v ariables X := ( X 1 , . . . , X p ) with a join t probabilit y mass function (p.m.f.) P is Mark o v on the graph G if the lo c al M arkov pr op e rty P ( x i | x N ( i ) ) = P ( x i | x V \ i ) (6) holds for all no des i ∈ V . More generally , w e say that P satisfies the glob al Markov pr op erty , if for al l disjoint sets A, B ⊂ V suc h that A ∩ N ( B ) = N ( A ) ∩ B = ∅ , we h a v e P ( x A , x B | x S ( A,B ; G ) ) = P ( x A | x S ( A,B ; G ) ) P ( x B | x S ( A,B ; G ) ) . (7) where the set S ( A, B ; G ) is a no de sep ar ator 9 b et wee n A and B , and N ( A ) denotes the n eigh b orh o o d of A in G . Th e lo cal and global Mark o v prop er- ties are equiv alen t u nder the p ositivity condition, giv en by P ( x ) > 0 , for all x ∈ X p [ 31 ]. The Hammersley–Clifford theorem [ 9 ] states that u nder the p ositivit y con- dition, a d istribution P satisfies the Mark o v pr op ert y according to a graph G if and only if it factorizes according to the cliques of G , that is, P ( x ) = 1 Z exp X c ∈C Ψ c ( x c ) , (8) 8 W e use th e notation E and G interc h an geably to d enote the set of edges. 9 A set S ( A, B ; G ) ⊂ V is a separator of sets A and B if the remo v al of no des in S ( A, B ; G ) separates A and B into distinct comp onents. 8 ANAND KUMAR, T AN, HU ANG AND WILLSKY where C is the set of cliques of G , and x c is the set of random v ariables on clique c . T he quantit y Z is known as the p artition function and serv es to normalize the p r obabilit y distribution. T he f u nctions Ψ c are kno wn as p otential fu n ctions. An imp ortan t class of graph ical mo d els is the class of pairwise mo dels, whic h f actorize according to the edges of the graph, P ( x ) = 1 Z exp X e ∈ E Ψ e ( x e ) . (9) One of the most we ll-studied pairwise mo dels is the Isin g mo del. Here, eac h rand om v ariable X i tak es v alues in th e set X = {− 1 , +1 } and th e prob- abilit y m ass function (p.m.f.) is give n by P ( x ) = 1 Z exp 1 2 x T J G x + h T x , x ∈ {− 1 , 1 } p , (10) where J G is known as the p oten tial matrix, and h as the p oten tial v ector. By con v en tion, J ( i, i ) = 0 for all i ∈ V . The sparsity pattern of J G corresp onds to that of the graph G , that is, J i,j = 0 for ( i, j ) / ∈ G . A mo del is said to b e attr active or ferr omagnetic if J i,j ≥ 0 and h i ≥ 0, for all i, j ∈ V . An Ising mo del is said to b e symmetric if h = 0 . W e assu me that there exists J min , J max ∈ R suc h that th e absolute v alues of the edge p oten tials are un if orm ly b ounded, that is, | J i,j | ∈ [ J min , J max ] ∀ ( i, j ) ∈ G. (11) W e can pr o vide guarant ees on s tructure reco ve ry , su b ject to conditions on J min and J max . W e assume that the node p oten tials h i are unif orm ly b ound ed aw ay from ±∞ . Giv en an Ising mo del, no des i, j ∈ V and a subset S ⊂ V \ { i, j } , w e defin e c onditional variation distanc e as ν i | j ; S := min x S ∈{± 1 } | S | ν ( P ( X i | X j = + , X S = x S ) , P ( X i | X j = − , X S = x S )) (12) = min x S ∈{± 1 } | S | 1 2 X x i = ± 1 | P ( X i = x i | X j = + , X S = x S ) (13) − P ( X i = x i | X j = − , X S = x S ) | . The empirical conditional v ariation distance b ν i | j ; S is defined by replacing the actual distributions with their empirical versions b ν n i,j ; S := min x S ∈{± 1 } | S | ν ( b P n ( X i | X j = + , X S = x S ) , b P n ( X i | X j = − , X S = x S )) . (14) Our algorithm will b e based on empirical conditional v ariation distances. This is b ecause the conditional v ariation distances 10 can b e used as a test 10 Note th at the conditional v ariation distances are in general asymmetric, that is, ν i | j ; S 6 = ν j | i ; S . STRUCTURE LEAR NING OF ISIN G MOD ELS 9 for conditional in dep end ence { X i ⊥ ⊥ X j | X S } ≡ { ν i | j ; S = 0 } ∀ i, j ∈ V , S ⊂ V \ { i, j } . (15) 2.3. T r actable gr aph families. W e consider the class of I s ing mo dels Mar- k o v on a graph G p b elonging to some ensemble G ( p ) of graph s with p n o des. W e consider th e high-dimens ional regime, where b oth p and the n umb er of samples n gro w sim u ltaneously; t ypically , the gro wth of p is muc h faster than that of n . W e emphasize that in our formulation, the graph ensemble G ( p ) can either b e deterministic or r andom—in the latter, w e also sp ecify a prob- abilit y measur e ov er the set of graph s in G ( p ) . In the setting where G ( p ) is a random-graph ensemble, let P X ,G denote the join t pr obabilit y distribu tion of the v ariables X and the graph G ∼ G ( p ) , and let P X | G denote the con- ditional d istribution of the v ariables giv en a graph G . Let P G denote the probabilit y distrib ution of graph G dra wn from a random en sem ble G ( p ) . In this setting, we use the term almost every (a.e.) graph G satisfies a certain prop erty Q if lim p →∞ P G [ G satisfies Q ] = 1 . In other wo rds, the prop ert y Q holds asymptotically almost sur ely 11 (a.a.s.) with r esp ect to the random-graph ensem ble G ( p ). Ou r conditions and theo- retical guarante es will b e b ased on this n otion for rand om graph ensembles. In tuitiv ely , this means that graphs that ha v e a v anish ing pr obabilit y of o c- currence as p → ∞ are ignored. W e now c haracterize the ensem ble of graphs amenable for consisten t struc- ture estimation und er our form ulation. T o this end, we c haracterize the so- called lo c al sep ar ators in graph s. S ee Figure 1 f or an illustration. F or γ ∈ N , let B γ ( i ; G ) d enote the s et of v ertices within distance γ from i with re- sp ect to graph G . Let F γ ,i := G ( B γ ( i )) denote the su bgraph of G spann ed b y B γ ( i ; G ), bu t in addition, we retain the no des n ot in B γ ( i ) (and r emo v e the corresp onding edges). Definition 1 ( γ -Lo cal separator). Giv en a graph G , a γ - lo c al sep ar ator S γ ( i, j ) b etw een i an d j , for ( i, j ) / ∈ G , is a minimal v ertex separator 12 with resp ect to the subgraph F γ ,i . In add ition, th e parameter γ is referred to as the p ath thr eshold for lo cal separation. In other w ords, the γ -lo cal separator S γ ( i, j ) separates no des i and j with resp ect to paths in G of length at most γ . W e no w c haracterize the ensemble of graphs based on the size of lo cal separators. 11 Note th at the term a.a.s. does not app ly to deterministic graph ensembles G ( p ) where no randomn ess is assumed, and in this setting, we assume that the prop erty Q holds for every graph in the ensemble. 12 A minimal separator is a separator of smallest cardinalit y . 10 ANAND KUMAR, T AN, HU ANG AND WILLSKY Fig. 1. Il lustr ation of l -lo c al sep ar ator set S ( i, j ; G, l ) for the gr aph shown ab ove with l = 4 . Note that N ( i ) = { a, b, c, d } is the neighb orho o d of i and the l -lo c al sep ar ator set S ( i, j ; G, l ) = { a, b } ⊂ N ( i ; G ) . This i s b e c ause the p ath along c c onne cting i and j has a length gr e ater than l and henc e no de c / ∈ S ( i, j ; G, l ) . Definition 2 (( η , γ )-Lo cal separation prop ert y ). An ensem ble of graph s G ( p ; η , γ ) s atisfies ( η , γ )-lo cal separation prop er ty if for a.e. G p ∈ G ( p ; η , γ ), max ( i,j ) / ∈ G p | S γ ( i, j ) | ≤ η . (16) In Section 3 , we pr op ose an efficien t algorithm for graphical m o del s elec- tion when the und erlying graph b elongs to a graph ensemble G ( p ; η , γ ) w ith sparse lo cal separators [i.e., small η , for η d efined in ( 16 )]. W e w ill see that the computational complexit y of our prop osed algorithm s cales as O ( p η +2 ). In Section 3.3 , we pr o vide examples of many graph families satisfying ( 16 ), whic h include the random regular graphs, Erd˝ os–R ´ en yi r an d om graph s and small-w orld graph s. Remark. The criterion of lo cal separation for tr actable learning is n o v el to the b est of our kno w ledge. The complexit y of a graphical mo d el is usually expressed in terms of its tr e e-width [ 49 ]. W e note that the criterion of sp arse lo cal separation is weak er than the tree-width; that is, η ≤ t , where t is the tree-width of the graph . In fact, our criterion is also w eak er than the criterion of b ound ed lo cal tree-width, introd uced in [ 22 ]. 3. Method and guarantees. 3.1. Assumptions. (A1) Sample c omplexity : W e consider the asymptotic setting where b oth the n umb er of v ariables (n o des) p and the num b er of i.i.d. s amp les n go to infinity . Th e required samp le complexity is n = Ω ( J − 2 min log p ) . (17) STRUCTURE LEAR NING OF ISIN G MOD ELS 11 W e require that the num b er of no des p → ∞ to exploit th e lo cal-separatio n prop erties of the class of graphs u n der consideration. (A2) Bounde d e dge p otentials : The Ising mo d el Mark ov on a.e. G p ∼ G ( p ) has the m aximum ab s olute p otentia l b elo w a thr eshold J ∗ . More precisely , α := tanh J max tanh J ∗ < 1 , (18) where the threshold J ∗ dep end s on the sp ecific graph ensemble G ( p ). See Section 8.1 in the sup plemen tary material [ 4 ] for an explicit charac terization of J ∗ for sp ecific ensem bles. (A3) L o c al-sep ar ation pr op erty : W e consider the ensem ble of graphs G ( p ) suc h that almost ev ery graph G dr a wn from G ( p ) satisfies the lo cal-separatio n prop erty ( η , γ ), according to Definition 2 , for some η = O (1) and γ ∈ N s u c h that 13 J min α − γ = e ω (1) , (19) where we say that a fun ction f ( p ) = e ω ( g ( p )), if f ( p ) g ( p ) log p → ∞ as p → ∞ . (A4) Generic e dge- p otentials : The edge p otent ials { J i,j , ( i, j ) ∈ G } of the Ising mo del are assumed to b e generically d ra wn f rom [ − J max , − J min ] ∪ [ J min , J max ]; that is, our results hold except for a set of Leb esgue measure zero. W e also c haracterize sp ecific classes of mo d els where this assumption can b e remov ed, and w e allo w f or any c hoice of edge p oten tials. See Sec- tion 8.3 in the sup p lemen tary material [ 4 ] for details. Assumption (A1) pro vides on the b ound on the sample complexit y . As- sumption (A2) limits the maxim um edge p oten tial J max of th e mo del. As- sumption (A3) relates the p ath threshold γ with th e m inim um ed ge p oten- tial J min in th e m o del. F or instance, if J min = Θ (1) and γ = O (log log p ) , w e require that α := tanh J max tanh J ∗ = 1 − Θ (1) < 1. Condition (A4) guaran tees the success of our method for generic edge p oten tials. Note that if the neigh b ors are m arginally indep enden t, then our metho d fails, and thus, w e cann ot exp ect our metho d to succeed for all edge p oten tials. Condition (A4) can b e remo v ed if w e limit to attractiv e mod- els (see Section 8.3.1 in th e su pplementa ry material [ 4 ]), or if we allo w for nonattractiv e mo dels, but limit to graph s w ith b ou n ded lo cal paths (see Section 8.3.3 in the supp lemen tary mate rial [ 4 ]). F or general mo dels, w e guaran tee success of our m etho ds for generic p otenti als; th at is, w e establish that the set of edge p oten tials where our metho d f ails has L eb esgue m ea- sure zero. S imilar assumptions ha v e b een pr eviously employ ed; for examp le, in [ 26 ] where learnin g d irected mo dels is considered, it is assumed that the graphical mo del is faithful with resp ect to the und erlying graph. 13 The cond ition in ( 19 ) invo lving e ω (1) is required for random graph ensembles such as Erd˝ os–R ´ enyi rand om graphs. It can b e w eakened as J min α − γ = ω ( 1) for degree-b ound ed ensem bles G Deg (∆). 12 ANAND KUMAR, T AN, HU ANG AND WILLSKY Algorithm 1 Algorithm CV DT ( x n ; ξ n,p , η ) for structure learning from x n samples based on empirical conditional v ariation distances. See ( 14 ). Initialize b G n p = ( V , ∅ ). F or eac h i, j ∈ V , if min S ⊂ V \{ i,j } | S |≤ η b ν i | j ; S > ξ n,p , (21) then add ( i, j ) to b G n p . Output: b G n p . 3.2. Conditional variation distanc e thr esholding. W e no w prop ose an algorithm, termed a s conditional v ariation distance thresholding ( CVDT ) whic h is prov en to b e consisten t for graph reconstruction under the ab ov e assumptions. T he pr o cedure for CVDT is provided in Algorithm 1 . Denote CVDT ( x n ; ξ n,p ) as the outpu t edge set from CVDT giv en n i.i.d. samples x n and threshold ξ n,p . The conditional v ariation distance test in the CVDT al- gorithm computes the emp irical conditional v ariation distance in ( 14 ) for eac h n o de pair ( i, j ) ∈ V 2 and finds the conditioning set w hic h ac hieve s the minim um o ver all sets of cardinalit y η . If the m inim um exceeds the thresh- old ξ n,p , the no de pair is declared an edge. The threshold ξ n,p needs to separate the edges and the n on ed ges in the Ising mo d el. It is c hosen as a fun ction of b oth num b er of no des p and n umb er of samples n and needs to satisfy the follo wing conditions: ξ n,p = O ( J min ) , ξ n,p = e ω ( α γ ) , ξ n,p = Ω r log p n ! . (20) F or example, w hen J min = Ω(1), α < 1 , γ = Ω(log p ) , n = Ω( g p log p ) , for some sequence g p = ω (1), we can choose ξ n,p = 1 min( g p , log p ) . Note that there is d ep enden ce on b oth n and p , since we n eed to regularize for sample s ize, as w ell as for the size of th e graph. In other words, with finite n umb er of samples n , the empirical conditional v ariation distances are noisy , and the threshold ξ n,p tak es this into accoun t via its inv erse dep endence on n . Similarly , as the graph size p increases, we establish that the tru e conditional v ariation d istance deca ys at a certain r ate und er assum ption (A2). Hence the thr esh old ξ n,p also d ep ends on the graph size p . Moreo v er, n ote that for all the cond itions in ( 20 ) to b e satisfied, the num b er of samples n should scale at least at a certain rate with resp ect to p , as giv en by ( 17 ). 3.2.1. Structur al c onsistency of CVDT . Assuming (A1)–(A4 ), we ha ve the follo wing result on asym p totic graph structure reco v ery . STRUCTURE LEAR NING OF ISIN G MOD ELS 13 Theorem 1 (Structural consistency of CVDT ). The algorithm CVD T is c onsistent for structur e r e c overy of Ising mo dels Markov o n a.e. gr aph G p ∼ G ( p ; η , γ ) : lim n,p →∞ n =Ω( J − 2 min log p ) P [ CVDT ( { x n } ; ξ n,p , η ) 6 = G p ] = 0 . (22) The pro of of this theorem is pro vided in Section 8 in the supplementary material [ 4 ]. Remarks . (1) Consistency g u ar ante e : The CVDT algorithm consisten tly reco v ers the str u cture of th e graphical m o dels, with probabilit y tend ing to one, where the probabilit y measure is with r esp ect to b oth the graph and the samples. W e extend our resu lts and provi de finite samp le guaran tees f or sp ecific graph families in S ection 3.2.2 . Moreo ver, if we requ ire a p ar ameter-fr e e thr eshold, that is, we do not kn o w the exact v alue of J min but only its scaling with p , then w e need to c h o ose ξ n,p = o ( J min ) rather th an ξ n,p = O ( J min ). In th is case, the sample complexit y scales as n = ω ( J − 2 min log p ) . (2) Other tests for c onditional indep endenc e : W e consider a test b ased on v ariation distances. Alternativ ely other distance measures can b e employ ed. F or instance, it can b e pro ve n that the Hellinger distance and the K ullbac k– Leibler distance h av e similar sample complexit y resu lts, while a test based on m utual information has a worse s amp le complexit y of Ω( J − 4 min log p ) under the assum p tions (A1)–(A4). W e term the test based on mutual information as CMIT and compare its exp erimenta l p erform an ce with CVDT in Sec- tion 5 . (3) Extension to other mo dels : Th e CVDT algorithm can b e extended to general discrete mo dels b y considering pairwise v ariation d istance b etw een differen t confi gurations. F or in stance, w e can set ν i | j ; S := X λ 1 6 = λ 2 λ 1 ,λ 2 ∈X min x S ∈X | S | ν ( P ( X i | X j = λ 1 , X S = x S ) , P ( X i | X j = λ 2 , X S = x S )) . (23) In [ 3 ], we d eriv e analogous cond itions for Gaussian graphical m o dels. Our approac h is also app licable to mo dels with higher order p otentia ls since it do es not dep en d on the pairwise nature of Isin g mod els. T he conditions for reco v ery are b ased on th e notion of c onditional uniqueness and can b e imp osed on any mo d el. In deed the regime of parameters wh ere conditional uniqueness holds d ep end s on the mo del and is h arder to c haracterize for more co mplex mo dels. Not ice that our algorithm requires o nly lo w-order statistics [up to O ( η + 2)] for an y class of graph ical mo dels which is relev ant when we are d ealing with mo dels with h igher order p oten tials. 14 ANAND KUMAR, T AN, HU ANG AND WILLSKY Pr oof outline. W e fir st analyze the scenario when exact statistics are a v ailable. (i) W e establish that for any t wo nonn eigh b ors ( i, j ) / ∈ G , the con- ditional v ariation distance in ( 21 ) (based on exact statistics) d o es not exceed the thr esh old ξ n,p . (ii) Similarly , we also establish that th e conditional v ari- ation distance in ( 21 ) exceeds the th reshold ξ n,p for all neigh b ors ( i, j ) ∈ G . (iii) W e then extend these results to emp irical v ersions usin g concen tration b ound s. 3.2.2. P AC Guar ante es for CVDT . W e n o w provide stronger r esults for CVDT metho d in terms of the probably appro ximately correct (P A C) mo del of learning [ 28 ]. Th is pro vides additional insight in to the task of graph esti- mation. Giv en an Ising mo del P on graph G p , recall the d efinition of condi- tional v ariation distance ν i | j ; S := min x S ∈{− 1 , +1 } | S | ν ( P ( X i | X j = + , X S = x S ) , P ( X i | X j = − , X S = x S )) . Giv en a graph G p and λ, η > 0, d efine G ′ p ( V ; λ ) := n ( i, j ) ∈ G p : min | S |≤ η S ⊂ V \{ i,j } ν i | j ; S > λ o , (24) ν max ( p ; η ) := max ( i,j ) / ∈ G p min | S |≤ η S ⊂ V \{ i,j } ν i | j ; S . (25 ) F or any δ > 0, choose the thresh old ξ n,p as ξ n,p ( δ ) = ν max ( p ; η ) + δ. (26) Define P min := min S ⊂ V , | S |≤ η + 1 x = {± 1 } | S | P ( X S = x S ) . (27) Theorem 2 (P A C guaran tees for CVDT ). Given an Ising mo del Markov on gr aph G and thr eshold ξ n,p ( δ ) ac c or ding to ( 26 ), CVDT ( { x n } ; ξ n,p ( δ ) , η ) r e c overs G ′ p ( V ; ν max ( p ; η ) + 2 δ ) for any δ > 0 , define d in ( 24 ), with pr ob ability at le ast 1 − ε , when the numb er of samples is n > 2( δ + 2) 2 δ 2 P 2 min log 1 ε + ( η + 2) log p + ( η + 4) log 2 , (28) and the c omputationa l c omplexity sc ales as O ( p η +2 ) . Pr oof . The pro of is provided in Section 9 in the s u pplementa ry mate- rial [ 4 ]. Th us, the ab o v e result charac terizes the r elationship b et w een the sepa- ration b et ween edges and nonedges (in terms of cond itional v ariation dis- STRUCTURE LEAR NING OF ISIN G MOD ELS 15 tances) and th e num b er of samples required to distinguish th em. A critical parameter in the ab o v e resu lt is ν max ( p ; η ) , the maximum conditional v aria- tion distance b et ween nonneighbors . W e no w pro vid e n onasymptotic b ounds on ν max ( p ; η ) for sp ecific graph families satisfying the ( η , γ )-lo cal separation condition. A d etailed description of the grap h families considered b elo w is pro vided in Section 3.3 . On lines of assumption (A2) in Section 3.1 , d efine α := tanh J max tanh J ∗ . (29) As w e noted earlier, the thresh old J ∗ dep end s on the graph family . W e c haracterize b oth J ∗ and ν max ( p ; η ) for v arious graph families b elo w. Lemma 1 [Nonasymptotic b ound s on ν max ( p ; η ) for graph families]. The fol lowing statements hold for α in ( 29 ): (1) F or the de gr e e- b ounde d ensemble G Deg ( p ; ∆) , J ∗ Deg = ∞ , ν max ( p ; ∆) = 0 . (30) (2) F or the girth-b ounde d ensemble G Girth ( p ; g , ∆) , J ∗ Girth = atanh 1 ∆ , ν max ( p ; 1) ≤ α g / 2 , (31) wher e ∆ is the maximum de gr e e and g is the girth. (3) F or the ensemble of ∆ -r andom r e gu lar gr aphs G Reg ( p ; ∆) , J ∗ Reg = atanh 1 ∆ . (32) Cho ose any l ∈ N such that l < 0 . 25(0 . 25 p ∆ + 0 . 5 − ∆ 2 ) . Then, with pr ob a- bility at le ast 1 − ∆ 16 l − 2 ( p ∆ − 4∆ 2 − 16 l ) − (8 l − 1) , ν max ( p ; 2) ≤ α l , (33) wher e ∆ is the de gr e e. (4) F or the Er d˝ os– R´ enyi ensemble G ER ( p, c/p ) , J ∗ ER = atanh 1 c . (34) Cho ose any l ∈ N such that l < log p 4 log c . W hen c > 1 , then with pr ob ability at le ast 1 − le √ 125 p − 2 . 5 − l ! c 4 l +1 p − 1 , ν max ( p ; 2) ≤ 2 l 3 α l log p , (35) wher e c is the aver age de gr e e. 16 ANAND KUMAR, T AN, HU ANG AND WILLSKY (5) F or the smal l-world g r aph ensemble G W atts ( p, d, c/p ) , similar r esults apply. J ∗ W atts = atanh 1 c , (36) Cho ose any l ∈ N such that l < log p 4 log c . W hen c > 1 , with pr ob ability at le ast 1 − le √ 125 p − 2 . 5 − l ! c 4 l − 1 p − 1 , ν max ( p ; d + 2) ≤ 4 l 3 α l log p , (37) wher e c is the aver age de gr e e of the E r d˝ os– R´ enyi sub gr aph. Pr oof . See Corollaries 1 and 2 in Section 8.1 in the s u pplementa ry material [ 4 ]. Th us, w e note that the conditional v ariation distance is small for non- neigh b ors when the m axim um edge p oten tial J max is suitably b oun d ed. Com bining the results ab ov e on ν max ( p ; η ) and the P AC guarante es in The- orem 2 , we note th at a ma j ority of edges in the Ising mo d el can b e learned efficien tly u nder a logarithmic sample complexit y . 3.3. Examples of tr actable gr aph f amilies. W e now sh o w that the lo cal- separation p rop erty in Defin ition 2 and the assum ptions in S ection 3.1 h old for a rich class of graphs. Example 1 (Bounded-d egree). An y (deterministic or random) ensem ble of degree-b oun ded graph s G Deg ( p, ∆) satisfies ( η, γ )-lo cal separation prop- ert y with η = ∆ and arbitrary γ ∈ N . This is b ecause for any no de i ∈ V , its neigh b orho o d N ( i ) exactly separates it from nonneighbors. S in ce there is exact separation, w e can establish that the thr eshold in ( 18 ) is infin ite ( J ∗ Deg = ∞ ); that is, there is n o constrain t on the maximum edge p oten- tial J max . How ev er, the computatio nal complexit y of our p rop osed algorithm scales as O ( p ∆+2 ); see also [ 10 ]. Thus, when ∆ is large, our p rop osed algo- rithm, as we ll as th e algorithm in [ 10 ], are computationally intensiv e. Our goal in this pap er is to relax the b ounded -degree assu mption and to con- sider sequences of ensembles of graph G ( p ) whose maxim um degrees ma y gro w with the num b er of n o des p . T o this end , we discuss other str uctural constrain ts whic h can lead to graphs with sparse lo cal separators. Example 2 (Bounded lo cal paths). Another su fficien t cond ition 14 for the ( η , γ ) -lo cal separation prop erty in Defin ition 2 to hold is that there are 14 F or any graph satisfying ( η , γ )-lo cal separatio n prop erty , the num b er of vertex-disjoint paths of length at most γ betw een any tw o n onneighbors is b oun ded ab ov e by η , by STRUCTURE LEAR NING OF ISIN G MOD ELS 17 at most η p aths of length at most γ in G b et wee n any t w o no des [henceforth, termed as the ( η , γ )- lo c al p aths pr op e rty ]. In other wo rd s , there are at m ost η − 1 num b er of o ve rlapp in g 15 cycles of length smaller than 2 γ . W e denote this ensemble of graphs as G LP ( p ; η , γ ). In particular, a sp ecial case of the lo cal-paths pr op erty describ ed ab o ve is the so-cal led girth prop ert y . Th e girth of a graph is the length of the shortest cycle. Thus, a graph with girth g sati sfies ( η , γ )-lo cal separation p rop erty with η = 1 and γ = g / 2. Let G Girth ( p ; g ) den ote the ensemble of graph s with girth at most g . There are man y graph constru ctions whic h lead to large girth. F or example, the bip artite Raman ujan graph [ 17 ], p age 107 and the random C a yley graph s [ 24 ] h a v e large girths. Recen tly , efficient algorithms ha v e b een prop osed to generate large girth graphs efficien tly [ 5 ]. The girth condition can b e wea ke ned to allo w for a small num b er of short cycles, while not allo w ing for typica l no de neighborho o ds to contai n short cycles. Suc h graphs are termed as lo c al ly tr e e- lik e . F or instance, the ensem ble of Erd ˝ os–R ´ en yi graph s G ER ( p, c/p ), wh er e an edge b et ween an y no de pair app ears with a pr ob ab ility c/p , indep end en t of other n o de pairs, is lo cally tree-lik e. T he p arameter c m a y gro w w ith p , alb eit at a con trolled rate for tractable structure learning, made precise later. In S ection 11 in the supp lementary mat erial [ 4 ], w e establish that there are at most t wo paths of length smaller than γ < log p 4 log c b et wee n any t w o nodes in Erd˝ os– R ´ enyi graphs a.a .s., or equiv alen tly , there are no ov erlapping cycles of length smaller than 2 γ a.a.s. Similar observ ations apply for the more general sc ale- fr e e or p ower-law graph s [ 18 , 20 ], and w e derive the precise r elationships in Section 11 in the supplementary material [ 4 ]. Along similar lines, the ensem ble of ∆-rand om regular graphs , denoted b y G Reg ( p, ∆), wh ic h is the uniform ensemble of regular graphs with degree ∆ h as no o ve rlappin g cycles of length at most Θ(log ∆ − 1 p ) a.a.s. [ 36 ], Lemma 1. W e n o w discus s the conditions un d er whic h a general lo cal-paths grap h ensem ble G LP ( p ; η , γ ) s atisfies assump tion 16 (A3) in Section 3.1 , required for our graph estimation algorithm CVDT to su cceed. Denote the maxim um de- gree f or the G LP ( p ; η , γ ) ens em ble as ∆ (p ossibly growing with p ). Note that w e can n o w implement the CVDT algorithm with parameter η . I n Section 8.1 in the su p plemen tary material [ 4 ], we establish that the threshold J ∗ in ( 18 ) is giv en by J ∗ LP = Θ(1 / ∆). When the minimum edge p oten tial J min ac h iev es app ealing to Menger’s theorem for b ounded p ath lengths [ 35 ]. How ever, the prop erty of local paths th at w e describ e abov e is a stronger notion than h a ving sp arse local separators, and we consider all distinct paths of length at most γ and not just vertex disjoint path s in the form ulation. 15 Tw o cy cles are said t o o verlap if they hav e common vertices. 16 In fact, a wea ker versi on of (A3) as J min α − γ = ω ( 1) suffices for degree-b ound ed en - sem bles G Deg (∆). 18 ANAND KUMAR, T AN, HU ANG AND WILLSKY the b ound, that is, J min = Θ(1 / ∆), the assumption (A3) simp lifies as ∆ α γ = o (1) . (38) Note that α < 1 under (A2). W e obtain a natural trade-o ff b et w een the maxim um degree ∆ and the path thresh old γ . When ∆ = O (1), we can allo w the path thresh old in ( 38 ) to scale as γ = O (log log p ) . This imp lies that graphs with fairly s mall path th reshold γ can b e incorp orated u nder our framew ork. In p articular, this includes the class of girth-b ou n ded graph with fairly small girth [i.e., the girth g s caling as O (log log p ) ]. W e can also incorp orate graph families with gro wing maxim um degrees in ( 38 ). F or instance, wh en ∆ = O (p oly log p ), we require the p ath thresh- old to scale as γ = O (log p ). In particular, the ∆-random-regular ensemble satisfies ( 38 ) when ∆ = O (p oly log p ). Th us, ( 38 ) repr esen ts a natural trade-off b et ween no de degrees and path threshold for consistent structur e estimation; graphs with large d egrees can b e learned efficient ly if their path thresholds are large. Indeed, in th e extreme case of trees which ha ve infinite thresh old (since they ha v e infin ite girth), in accordance w ith ( 38 ), ther e is no constrain t on n o de d egrees for successful reco very , and recall that the Ch ow–Liu algorithm [ 16 ] is an efficient metho d for mo del selection on tree distributions. Moreo ver, the constraint in ( 38 ) can b e wea ke ned for random graph en - sem bles by replacing the maximum degree with the a verage d egree. Recall that in the E r d˝ os–R ´ enyi e nsemble G ER ( p, c/p ), an edge b et w een an y t wo no des o ccurs with p robabilit y c/p and that this ensemble s atisfies the ( η , γ ) prop erty w ith path thresh old γ = O ( log p log c ) and η = 2 . In Section 8.1 in th e supplementary material [ 4 ], we establish that the thr eshold in ( 18 ) is given b y J ∗ ER = Θ (1 /c ). Comp aring with the threshold for ∆ -d egree b oun ded graphs J ∗ = Θ(1 / ∆) discussed ab o v e, we see that we can obtain b etter b ounds for random-graph ensembles. When the minimum edge p oten tials ac hiev es the th r eshold ( J min = Θ(1 /c )), the requir emen t in assumption (A3) in S ection 3.1 s im p lifies to cα γ = e o (1) , (39) whic h is true w h en c = O (p oly log p ) . Th us, we ca n guarantee consisten t structure estimation for the Erd ˝ os–R´ en yi ensem ble when th e a v erage degree scales as c = O (p oly log p ). This r egime is t ypically known as the “sp arse” regime and is relev an t, since in practice, our goal is to fi t the measur emen ts to a sp arse graphical mo d el. Example 3 (Small-w orld graph s). The p revious t w o examples show ed that lo cal separation holds und er t wo d ifferen t conditions: b ounded maxi- m um d egree and b ounded n umb er of lo cal paths. The former class of graphs STRUCTURE LEAR NING OF ISIN G MOD ELS 19 can hav e short cycles, b ut the maxim um degree needs to b e constan t, while the latter class of graphs can ha v e a large maxim um degree bu t the n um- b er of o ve rlappin g short cycles needs to b e small. W e no w p ro vide instances whic h in corp orate b oth these f eatures, large d egrees and sh ort cycles, and y et satisfy the lo cal separation pr op erty . The class of hybrid graph s or augmented graphs ([ 18 ], C hapter 12) con- sists of graphs which are the union of t wo graphs: a “lo cal” graph , ha ving short cycles, and a “global” graph , having small av erage distances. Sin ce the h ybrid graph is the union of these lo cal and global graphs, it simultaneously has large degrees and short cycles. The simplest mo d el G W atts ( p, d, c/p ), first studied by W atts and Strogatz [ 51 ], consists of th e un ion of a d -dimens ional grid and an Erd˝ os–R ´ enyi rand om graph with parameter c . It is easily seen that a.e. graph G ∼ G W atts ( p, d, c/p ) satisfies ( η , γ ) -lo cal separation prop erty in ( 16 ), w ith η = d + 2 , γ ≤ log p 4 log c . Similar ob s erv ations app ly f or more general hybrid graphs studied in [ 18 ], Chapter 12. In Section 8.1 in the su pplementa ry material, we establish that th e thresh- old in ( 18 ) for the s m all-w orld ens em ble G W atts ( p, d, c/p ) is giv en b y J ∗ W atts = Θ(1 /c ) and is ind ep endent of d , the degree of the grid graph. Comparin g with the thresh old J ∗ ER for Erd˝ os–R ´ en yi ensemble G ER ( p, c/p ), w e n ote th at the t w o thresholds are identi cal. This furth er implies that ( 39 ) holds for the small-w orld graph ensem ble as well . 3.4. Explicit b ounds on sample c omplexity of CV DT . Recall that the sample complexit y of the CVDT is required to scale as n = Ω( J − 2 min log p ) for structural consistency in high dimensions. Thus, the sample complex- it y is small wh en the minimum ed ge p oten tial J min is large. On the other hand, J min cannot b e arb itrarily large d u e to assumption (A2) in S ection 3.1 , whic h entails that J min < J ∗ . T he minimum samp le complexit y is th us at- tained when J min ac h iev es th e thresh old J ∗ . W e no w provide explicit resu lts for the minim um sample complexit y for v arious graph ensem bles, based on the threshold J ∗ . Recall that in Sec- tion 3.3 , we discu ssed th at for the graph ensemble G LP ( p, η , γ , ∆) satisfying the ( η , γ )-lo cal paths p rop erty an d h a ving maxim um degree ∆ , the thresh- old is J ∗ LP = 1 / ∆. Thus, the minimum sample complexit y for this graph ensem ble is n = Ω(∆ 2 log p ) , that is, wh en J min = Θ(1 / ∆). F or the E r d˝ os–R ´ enyi random graph ens em ble G ER ( p, c/p ) and the small- w orld graph ensemble G W atts ( p, d, c/p ), recall th at th e th r esholds are giv en b y J ∗ ER = J ∗ W atts = 1 /c , where c is the mean degree of the Erd˝ os–R ´ en yi graph. Th us, the minimum sample complexit y can b e impr o v ed to n = Ω( c 2 log p ) , 20 ANAND KUMAR, T AN, HU ANG AND WILLSKY b y setting J min = Θ(1 /c ). This implies th at wh en the Erd˝ os–R ´ en yi random graphs and sm all-wo rld graphs h a v e a b ound ed av erage degree [ c = O (1)], the minimum sample complexit y is n = Ω(log p ). Recall that the sample complexit y of learning tree mo dels is Ω(log p ) [ 47 ]. Thus, we observ e that the complexit y of learning sp arse Erd˝ os–R ´ en yi rand om graphs and small- w orld graphs using our algorithm CVDT is akin to learning tree structures in certain parameter regimes. 3.5. Comp arison with pr evi ous r esults. W e now compare the p erformance of our algorithm CVDT w ith ℓ 1 -p enalized logistic regression prop osed in [ 41 ]. W e fi rst compare the computational complexities. Th e metho d in [ 41 ] has a computational complexit y of O ( p 4 ) for any inpu t (assuming p > n ). O n the other h an d , the complexit y of our metho d d ep ends on the graph family under consideration. It can b e as lo w as O ( p 3 ) for girth -b ounded ensembles, O ( p 4 ) for rand om graph f amilies and as high as O ( p ∆ ) for degree-b oun ded ensem bles (without any additional c haracterization of the lo cal separation prop erty). C learly our metho d is not efficien t for general d egree-b ounded ensem bles since it is tailored to exploit th e spars e lo cal-separation p rop erty in the u nderlying graph. W e n o w compare th e sample complexities u nder the t w o metho ds. It was established that the metho d in [ 41 ] has a m inim um sample complexit y of n = Ω (∆ 3 log p ) for a d egree-b ounded ensemble G Deg ( p, ∆) satisfying certain “incoherence” conditions. Th e sample complexit y of our CVDT algorithm is b etter at n = Ω(∆ 2 log p ) . Moreo ver, we can guarantee impro ved sample com- plexit y of n = Ω( c 2 log p ) for Er d˝ os–R ´ enyi rand om graphs G ER ( p, c/p ) and small-w orld graphs G W atts ( p, d, c/p ) u nder the mod ified CVDT alg orithm. Note that these rand om graph ensembles ha ve maxim um d egrees (∆ ) muc h larger than the av erage d egrees ( c ), and th us, we can provide stronger sample complexit y results. Moreo ver, ou r algorithm is lo cal and requires only low- order statisti cs for an y class of graphical mo dels of arbitrary order, while the metho d in [ 41 ] requires full-order statistics since it undertak es neigh b orho o d selection through regularized logistic regression. Th is is relev an t in p ractice, since our algorithm is b etter equipp ed to handle missing samp les. The incoherence cond itions required for the su ccess of ℓ 1 p enalized lo- gistic regression in [ 41 ] are NP-hard to establish for general mo dels since they inv olv e the partition function of the mo del [ 6 ]. I n con trast, our con- ditions are transparent and r elate to the phase transitions in the mo del. It is an op en question as to whether the incoherence conditions are implied b y our a ssum ptions or vice-v ersa for general mo dels. It app ears that our conditions are wea ker than the incoherence conditions for r andom-graph mo dels. F or instance, for th e Erd˝ os–R ´ en yi mo del G ER ( p, c/p ), w e require that J max = O (1 /c ), where c is the a ve rage degree, while a su fficien t con- dition for incoherence is J max = O (1 / ∆), where ∆ is the maxim um degree. Note that ∆ = O (log p log c ) a.a.s. for the E r d˝ os–R ´ enyi mo d el. Similar obser- STRUCTURE LEAR NING OF ISIN G MOD ELS 21 v ations also hold for the p o we r-la w and small-w orld graph ensem bles. This implies that we can guaran tee consisten t structure estimation u nder we ak er conditions (i.e., a wider range of p arameters) and b etter samp le complexit y for the Er d˝ os–R ´ enyi, p o wer-la w and small-wo rld mo d els. 4. Necessary conditions for graph estimation. W e ha v e so far p rop osed algorithms and pro vided p erformance guarant ees f or graph estimation giv en samples fr om an Ising mo dels. W e no w analyze necessary conditions for graph estimation. 4.1. Er d˝ os– R´ enyi r andom gr aphs. Necessary conditions for graph esti- mation ha ve b een previously c haracterized for degree-b ounded graph en - sem bles G Deg ( p, ∆) [ 43 ]. Ho wev er, th ese conditions are to o lo ose to b e useful for the ensemble of Erd˝ os–R ´ en yi graphs G ER ( p, c/p ), where the av erage d e- gree 17 ( c ) is m uch smaller than the maxim um degree. W e no w pro vide a lo wer b ound on samp le complexit y for graph estimat ion of Erd˝ os–R ´ en yi graphs using an y deterministic estimator. Recall that p is the num b er of no d es in the mo del, and n is th e num b er of samples. I n the follo win g r esu lt, c is allo wed to dep end on p and is thus more general than the pr evious results. Theorem 3 (Necessary cond itions for mo del selectio n). A ssu me that c ≤ 0 . 5 p and G p ∼ G ER ( p, c/p ) . Then if n ≤ εc log p for sufficiently smal l ε > 0 , we have lim p →∞ P [ b G n p ( X n p ) 6 = G p ] = 1 (40) for any deterministic estimator b G p . Th us, wh en n ≤ εc log p for sufficient ly small ε > 0, the probabilit y of error for str ucture estimation tends to one, where the probability measure is with resp ect to b oth the Erd˝ os–R ´ en yi r andom graph and the samples. T he pro of of th is theorem can b e foun d in Section 10 in the sup plemen tary material, and is along the lines of [ 10 ], Theorem 1. The result in Th eorem 3 provides an asymptotic necessary cond ition for structure learnin g and inv olve s an ad d itional auxiliary parameter ε . In th e follo win g r esult, w e remo ve th e requirement f or the auxiliary parameter ε and pro vide a nonasymptotic necessary condition, but at the exp ense of ha ving a w eak (instead of a strong) con v erse. Theorem 4 (Nonasymptotic necessary conditions for mo d el selection). Assume tha t G ∼ G ER ( p, c/p ) , wher e c may dep end on p . L et P ( p ) e := 17 The techniques in th is section is applicable when the av erage sparsit y parameter c of G ER ( p, c/p ) ensemble is a fun ction of p and satisfies c ≤ p/ 2 . 22 ANAND KUMAR, T AN, HU ANG AND WILLSKY P ( ˆ G p 6 = G p ) b e the pr ob ability of err or. If P ( p ) e → 0 , the numb er of samples n must satisfy n ≥ 1 p log 2 |X | p 2 H b c p . ( 41) By expand ing the b inary entrop y fun ction H b ( · ), it is easy to see that th e statemen t in ( 41 ) can b e w eak ened to the more easily int erpr etable (alb eit w eak er) necessary condition n ≥ c log 2 p 2 log 2 |X | . (42) The ab o ve r esu lt differs from Theorem 3 in tw o asp ects: the b oun d in ( 41 ) do es not inv olv e an y asymptotic notation and is a w eak con v erse result (instead of a strong conv erse). The p ro of is provided in Section 10.3 in the supplementary material [ 4 ]. Remarks . (1) Thus, n = Ω( c log p ) num b er of samples are ne c essary for structure reco very . Hence, the larger the a v erage degree, the higher is the required sam- ple complexit y . Intuiti vel y this is b ecause as c gro ws, th e graph is denser, and hence we r equire more samples for learning. In in f ormation-theoretic terms, Theorem 3 is a s trong con v erse [ 19 ], since we sh o w that the error probabilit y of structure learnin g tends to one (instead of b eing merely b ounded aw a y from zero). On the other hand, the result in Th eorem 4 is a w eak conv erse result. (2) In [ 43 ], it is sh o wn that for graph s uniform ly drawn from the class of graphs with maximum degree ∆ , when n < ε ∆ k log p for some k ∈ N , there exists a graph for whic h an y estimator fails with probabilit y at least 0 . 5. These results cannot b e applied here since the probability mass function is non unif orm for the class of Erd˝ os–R´ en yi rand om graphs. (3) The result is not dep end en t on the Ising mo del assumption, an d holds for any pairwise discrete Marko v random fi eld (i.e., X is a fi nite set). W e no w p ro vide an outline for the pr o of of Theorem 4 . A na ¨ ıv e application of F ano’s inequalit y for this problem d o es n ot yield an y meaningful result since the set of all graphs (whic h can b e realized b y G ER ) is “to o large.” W e emplo y another information-theoretic idea kno wn as typic ality . W e identify a set of grap h s with p no des whose av erage degree is ε -close to c (whic h is the exp ected degree for G ER ( p, c/p ). Th e set of t ypical graphs has a small cardinalit y b u t h igh pr obabilit y when p is large. The no ve lt y of our pr o of lies in our use of b oth typica lit y as wel l as F ano’s inequalit y to derive necessary STRUCTURE LEAR NING OF ISIN G MOD ELS 23 conditions for structur e learning. W e can sho w that (i) the p robabilit y of the t ypical set tends to one as p → ∞ ; (ii) the graph s in the t ypical set are almost un iformly distributed (the asymptotic equipartition prop ert y); (iii) the cardinalit y of the t ypical set is small relativ e to the set of all graph s. A detailed d iscussion of th ese techniques is given in [ 3 ]. 4.2. Other gr aph families. W e no w p ro vide necessary conditions f or r e- co very of graphs b elonging to v arious graph ensembles considered in this pap er. W e first recap the results of [ 10 ], Theorem 1, whic h is applicable for an y u niform ensem ble of graphs . Theorem 5 (Lo wer b ound on sample complexit y). Assume tha t a gr aph G p on p no des is uniformly dr awn fr om an ensemble G . Given n i. i.d. samples fr om an Ising mo del Markov on G , we have P [ b G n p ( X n p ) 6 = G p ] ≥ 1 − 2 np |G | (43) for any deterministic estimator b G p . W e pro vid e b ounds on the n umb er of graph s in sp ecific graph families considered earlier in the pap er wh ic h gives us necessary cond itions for their reco very . Lemma 2 (Bounds on size of graph families). The f ol lowing b ounds hold: (1) F or girth-b ounde d ensembles G Girth ( p ; g , ∆ min , ∆ max , k ) with girth g , minimum de gr e e ∆ min , maximum de gr e e ∆ max and numb er of e dges k , we have p k ( p − g ∆ g max ) k ≤ |G Girth ( p ; g , ∆ min , ∆ max , k ) | ≤ p k ( p − ∆ g min ) k . (44) (2) F or lo c al-p ath ensembles G LP ( p ; η , γ , ∆ min , ∆ max , k ) having η p aths of length less than γ > 0 b etwe en a ny two no des, minimum de gr e e ∆ min > 0 , maximum de gr e e ∆ max and numb er of e dges k , m 1 p k 1 ( p − γ ∆ γ max ) k 1 ∆ γ min 2 η − 1 ≤ |G LP ( p ; η , γ , ∆ min , ∆ max , k ) | ≤ m 2 p k 2 ( p − ∆ γ min ) k 2 γ ∆ γ max 2 η − 1 , (45) wher e k 1 := k − m 2 ( η − 1) , k 2 := k − m 1 ( η − 1) , m 1 := p γ ∆ γ max and m 2 := p ∆ γ min . (3) F or augmente d ensembles G Aug ( p ; d, η , γ , ∆ min , ∆ max , k ) c onsisting of a lo c al gr aph with (r e gular) de gr e e d and a glob al gr aph G LP ( p ; η , γ , ∆ min , 24 ANAND KUMAR, T AN, HU ANG AND WILLSKY ∆ max , k ) , we have m 1 p k ′ 1 ( p − γ ∆ γ max ) k ′ 1 ∆ γ min 2 η − 1 p − 1 d ≤ |G Aug ( p ; d, η , γ , ∆ min , ∆ max , k ) | (46) ≤ m 2 p k ′ 2 ( p − ∆ γ min ) k ′ 2 γ ∆ γ max 2 η − 1 p − 1 d , wher e k ′ 1 := k 1 + 1 − pd 2 and k ′ 2 := k 2 + 1 − pd 2 , for k 1 , k 2 , m 1 , m 2 define d pr e v iously. The pro of of the ab ov e result is giv en in Section 10 .2 in the supplemen tary material [ 4 ]. Remarks . Using the ab ov e results on lo wer b ounds on the num b er of graphs in a giv en family , in conjunction with Th eorem 5 , we can obtain necessary conditions for d ifferen t graph families. F or instance, for girth- constrained families, when the girth g and maxim um d egree ∆ max scale as O (p oly log p ), we hav e that n = Ω k p log p (47) n umb er of samples is necessary for stru cture estimation, where k is the n um- b er of edges. Similarly , f or lo cal path ensembles, wh en the path threshold γ and m axim um degree ∆ max scale as O (p oly log p ) , the ab o v e b ound in ( 47 ) c hanges only sligh tly , and we hav e n = Ω k p − η − 1 ∆ γ min log p as the necessary condition, b y substituting for k 1 , and noting that the other terms scale slo w er than log p u n der the ab ov e sp ecified regime. Similarly , f or augmen ted graph s, w e ha v e n = Ω k p − η − 1 ∆ γ min − d 2 log p as the necessary condition. Thus, for a w ide class of graphs, w e can c harac- terize necessary conditions for s tructure estimation. 5. Exp eriments. In this secti on exp erimental results are pr esen ted on syn thetic d ata. W e imp lemen t the p rop osed CV DT (based on c onditional v ariation d istances) and CMIT (based on cond itional mutual inf ormation) metho ds u nder different thresholds, as w ell the ℓ 1 regularized logistic re- STRUCTURE LEAR NING OF ISIN G MOD ELS 25 gression [ 41 ] under differen t r egularization parameters. 18 The p erformance of the metho ds is compared usin g the n otion of the edit distance b et w een the estimated and the tru e graphs. W e implement the prop osed CVDT and CMIT method s in MA TLAB and the ℓ 1 regularized logistic regression is ev al- uated us ing L1General p ac k age. 19 CONTEST 20 pac k age is used to generate the syntheti c graph s, and UGM 21 pac k age is u sed for implement ing Gibbs sampling from the Is ing Mo del. Th e datasets, softw are co de and r esu lts are a v ailable at http: //newpor t.eecs.u ci.edu/anandkumar . 5.1. Data sets. In order to ev aluate the CVDT p erforman ce in terms of quantit y of errors in r eco vering the graph structure, w e generate samples from Isin g mod el for th r ee t ypical graph s, namely , a single cycle graph whose η cycle = 2, Er d˝ os–R ´ enyi rand om graph G ER ( p, c/p ) with av erage degree c = 1 and the W atts and Strogatz mo del G WS ( p, d, c/p ) with degree of lo cal graph d = 2 and a v erage degree of th e glo bal graph c = 1. Graphs of size p = 80 and sample size n ∈ { 10 2 , 5 × 10 2 , 10 3 , 5 × 10 3 , 10 4 , 10 5 } are consid er ed . Based on th e generated graph top ologies, we generate the p otent ial ma- trix J G whose sparsity pattern corresp onds to th at of th e graph G . By con v en tion, diagonal elemen ts J ( i, i ) = 0 for all i ∈ V . W e consider b oth at- tractiv e and general mo dels. F or attractiv e mo dels, w e consider the nonzero off-diagonal entries of J as uniform ly distributed in [0 . 1 , 0 . 2]. F or the gen- eral mo del, w e consider the nonzero off-diagonal entries of J as u niformly distributed in [0 . 1 , 0 . 2] ∪ [ − 0 . 1 , − 0 . 2]. P oten tial ve ctor is set to 0 resulting in a symmetric Ising mo del. Gi bb s samp ling met ho d is used to generate samples. T h e knowle dge of the b ound on lo cal separators η is assu m ed to b e a v ailable in our exp eriments. W e emplo y n ormalized edit distances as the p erforman ce criterion. Sin ce we kno w the ground truth for synthetic data, it is p ossible to ev aluate this measure. The thr esholds ξ n,p for CVDT / CM IT and the r egularizatio n parameter λ n for the ℓ 1 regularized logistic regression are selected based on the b est edit distances for eac h metho d. 5.2. Exp erimental r esults. T able 1 presents the exp eriment al outcomes, and an explicit comparison of th e thr ee graph estimation metho ds is illus- trated in Figure 2 for attractiv e mo dels, and in Figure 3 for mixed mo dels (with b oth p ositiv e and negativ e edge p oten tials). Sim ilar trends are ob- serv ed for b oth attractiv e and mixed mo dels. W e note that the edit distance 18 F or the conve x relaxation meth od in [ 41 ], the regularization parameter d enotes the w eight associated with the ℓ 1 term. 19 L1General is av ailable at http://www .di.ens.fr/~ms chmidt/Software/L1General. html . 20 CONTEST is at http://www .mathstat.stra th.ac.uk/research/groups/numerical analysis/c ontest . 21 UGM is at http://www .di.ens.fr/ ~ mschmidt/S oftware/UGM.ht ml . 26 ANAND KUMAR, T AN, HU ANG AND WILLSKY T able 1 Normalize d e dit distanc e under CVDT (b ase d on c onditional variation distanc es), CMIT (b ase d on c onditional mutual information) and ℓ 1 p enalize d neighb orho o d sele ction on synthetic data fr om gr aphs l iste d ab ove for attr active and mixe d Ising mo dels, wher e n denotes the numb er of samples Graph n CVDT CMIT ℓ 1 p enalty CVDT CMIT ℓ 1 p enalty (attractiv e) (attractiv e) (attractiv e) (mixed) (mixed) (mixed) Cycle 1 × 10 2 1.0000 1.0000 1.0000 1.0000 1.000 0 1.0 000 ER 1 × 10 2 1.0000 1.0000 1.0000 1.0000 1.000 0 1.0 000 WS 1 × 10 2 1.0000 1.0000 1.0000 1.0000 1.000 0 1.0 000 Cycle 5 × 10 2 1.0000 0.5000 1.0000 0.975 0.47 5 1.0000 ER 5 × 10 2 1.0000 0.5300 1.0000 0.9189 0.594 6 1.0 000 WS 5 × 10 2 1.0000 0.3313 1.0000 1.0000 0.331 3 1.0 000 Cycle 1 × 10 3 0.7125 0.1750 0.4000 0.7250 0.150 0 0.3 063 ER 1 × 10 3 0.7428 0.1020 0.3378 0.6757 0.135 1 0.4 342 WS 1 × 10 3 0.9937 0.1438 0.1625 0.9938 0.143 8 0.4 255 Cycle 5 × 10 3 0.0125 0.0000 0.1937 0.0125 0.000 0 0.1 500 ER 5 × 10 3 0.0000 0.0204 0.2031 0.0000 0.105 3 0.0 000 WS 5 × 10 3 0.3827 0.0000 0.0312 0.5688 0.000 0 0.2 671 Cycle 1 × 10 4 0.0000 0.0000 0.0000 0.3063 0.000 0 0.0 000 ER 1 × 10 4 0.0000 0.0000 0.0000 0.0000 0.000 0 0.0 000 WS 1 × 10 4 0.0000 0.0000 0.0000 0.0000 0.000 0 0.0 000 deca ys as th e n umb er of samples increases, as exp ected. As long as there are enough num b er of samples (larger than 10,000), all the metho ds r eco ver the graph stru ctur e accurately , that is, w ith zero error. In terms of the d eca yin g rate of errors, the ℓ 1 logistic r egression metho d has a faster rate than CVDT for the W atts–Strogatz graph in all r egimes, w hile for the cycle graph and the Erd˝ os–R ´ enyi graph , the rates for CVDT and the ℓ 1 metho d are alternativ ely b etter dep ending on n . Ho we ve r, CMIT has the fastest rate of d eca y of edit distance for all the three graphs, although theoretically , CV DT has b etter sample complexit y guarante es compared to CMIT ; see Theorem 1 and r e- lated remarks. With regard to the run ning time, CVDT and CMIT are faster for the graphs under consideration, since there is one global threshold to b e selected for finding all the edges, while for logistic regression, selectio n of the regularization parameter needs to b e carried out for eac h neigh b orh o o d in the graph . This is esp ecially exp ensiv e for large graphs. 6. Conclusion. In this pap er, w e adopted a n o v el and a unified parad igm for Ising mo d el selectio n. W e p resen ted a simple local alg orithm for structure estimation w ith lo w computational and samp le complexities under a set of mild and transparent conditions. This algorithm su cceeds on a wid e r ange STRUCTURE LEAR NING OF ISIN G MOD ELS 27 (a) Cycle (b) Erd ˝ os-R ´ en yi (c) W atts-Strogat z Fig. 2. CVDT , CMIT and ℓ 1 p enalize d lo gistic r e gr ession on synthetic data fr om an attr active I si ng mo del. of graph ens em bles suc h as the Erd˝ os–R ´ enyi ens emble, small-wo rld n etw orks etc. based on a lo cal separation criterion. SUPPLEMENT AR Y MA TERIAL Supp lemen t to “High-dimensional structure estimation in Ising mo d els: Lo cal separation criterion” (DOI: 10.1214/12 -A OS1009SUPP ; .p df ). De- tailed analysis and pr o ofs. Ac kno wledgment s. Th e authors thank Suja y Sangha vi (U.T. Austin), Elc hanan Mossel (UC Berke ley), Martin W ain wright (UC Berk eley), Se- bastien Ro ch (UCLA), Ru i W u (UIUC) and Divyansh u V ats (U. Minn .) for extensiv e comment s, and B´ ela Bollob´ as (Cam br id ge) for discu ssions on ran- dom graph s. The auth ors thank the anonymous r eview ers and th e co-editor P eter B ¨ uhlmann (ETH) f or v aluable commen ts that significan tly impro ved this manuscript. 28 ANAND KUMAR, T AN, HU ANG AND WILLSKY (a) Cycle (b) Erd ˝ os-R ´ en yi (c) W atts-Strogat z Fig. 3. CVDT , CMIT and ℓ 1 p enalize d lo gistic r e gr ession on synthetic data fr om a mixe d Ising mo del (wi th b oth p ositive and ne gative e dge p otentials). REFERENCES [1] Abbeel, P. , Koller, D. and Ng, A. Y. (2006). Learning factor graphs in p olynomial time and sample complexity. J. M ach. L e arn. R es. 7 1743–178 8. MR2274423 [2] Alber t, R. and Barab ´ asi, A.-L. (2002). S t atistical mechanics of complex n etw orks. R ev. M o dern Phys. 74 47–97. MR1895096 [3] Ana n dkumar, A. , T an, V. Y. F. , Huang, F. and Willsky, A. S. (2011). High-dimensional Gaussian graphical mod el selection: T ractable graph families. Preprint. A v ailable at arXiv: 1107.12 70 . [4] Ana n dkumar, A. , T an, V. Y. F. , Huang, F. and W i llsky, A. S . (2012 ). Supp le- ment to “High-dimensional structure learning of Ising mo dels: Lo cal separation criterion.” DOI : 10.121 4/12-AOS1009SUPP . [5] Ba y a ti , M. , Mont anari, A. and Saberi, A. (2009). Generating random graphs with large girth. I n Pr o c e e dings of the Twentieth Annual ACM-SIAM Symp osium on Discr ete Al gorithms 566–575. SIAM, Philadelphia, P A . MR2809261 [6] Be nto, J. and Mont anari , A. (2009). Which graphical mo dels are difficult to learn? In Pr o c. of Neur al I nformation Pr o c essing Systems (NIPS) . STRUCTURE LEAR NING OF ISIN G MOD ELS 29 [7] Bogdanov, A. , Mossel, E. and V a d han, S. (2008). The complexit y of d istinguish- ing Mark ov rand om fields. In Appr oximation, R andomization and Combinato- rial Optimization . L e ctur e Notes in Comput. Sci. 5171 331–342. Sp ringer, Berlin. MR2538798 [8] Bollob ´ as, B. (1985). R andom Gr aphs . Academic Press, Lond on. MR0809996 [9] Br ´ emaud, P. (1999). Markov Chains: Gibbs Fiel ds, Monte Carlo Simulation, and Queues . T exts in Applie d Mathematics 31 . Springer, N ew Y ork. MR1689633 [10] Bresler, G . , Mossel, E. and Sl y, A. (2008). Reconstruction of Marko v random fields from samples : Some observa tions and algorithms. In Appr oximation, R an- domization and Combinatorial Optimization . L e ctur e Notes in Computer Scienc e 5171 343–356 . Springer, Berlin. MR2538799 [11] Chandrasekaran, V . , P arri lo, P. A. and Willsky, A. S. (2010). Latent v ari- able graphical model selection via con vex optimization. Ann. Statist. T o app ear. Preprint. A v ailable on ArXiv. [12] Chechetka, A. and G uestrin, C. (2007). Efficien t principled learning of thin junc- tion trees. In A dvanc es in Neur al I nformation Pr o c essing Systems (NIPS) . [13] Cheng, J. , Greiner, R. , Kell y, J. , Bell, D. and Liu, W . (2002). Learning Ba yesian netw orks from data: An information-theory based approac h. A rtificial Intel l igenc e 137 43–90. MR1906473 [14] Choi, M. J. , Lim, J. J. , Torralba, A. and Willsky, A. S. (2010). Exploiting hierarc hical context on a large database of ob ject categories. In IEEE Conf. on Computer Vision and Pattern R e c o gnition (CVPR) . [15] Choi, M. J. , T a n, V. Y . F. , Anan dkumar, A. and Willsky, A . S. (2011). Learning laten t tree graphical mo dels. J. Mach. L e arn. R es. 12 1771–181 2. MR2813153 [16] Chow , C. and Liu , C. (1968). App ro ximating Discrete Probabilit y Distributions with Dep endence T rees. IEEE T r an. on Inf ormation The ory 14 462–467 . [17] Chung, F. R. K. (1997). Sp e ctr al Gr aph The ory . CBMS R e gional Confer enc e Series in Mathematics 92 . Pub lished for the Conference Board of the Mathematical Sciences, W ashington, DC. MR1421568 [18] Chung, F. R. K. and Lu, L. (2006). Complex Gr aphs and Network . Amer. Math. Soc., Providence, RI. [19] Co ver, T. M. and T h omas, J. A. (2006). Elements of Information The ory , 2nd ed. Wiley , H ob oken, NJ. MR2239987 [20] Dommers, S. , Giardin ` a, C. and v an der Hofst ad, R. (2010). Ising mo dels on p ow er-law random graphs. J. Stat. Phys. 141 1–23. [21] Durbin, R. , Eddy, S . R. , Krogh, A. and Mitchison, G. (1999). Biol o gic al Se- quenc e Analysis: Pr ob abili stic Mo dels of Pr oteins and Nucleic A cids . Cambridge Univ. Press, Cambridge. [22] Eppstein, D. (2000). Diameter and treewidth in minor-closed graph families. Algo- rithmic a 27 275–291. MR1759751 [23] Galam, S. (1997). Rational group decision making: A random field Ising mo del at T = 0. Physic a A: Statistic al and The or etic al Physics 238 66–80. [24] Gamburd, A. , Hoor y , S. , Shahshahani , M. , Shalev, A. and Vir ´ ag, B. (2009). On the girth of random Ca yley graphs. R andom Structur es Algorithms 35 100– 117. MR2532876 [25] Grabo wski, A. and Kosinski, R . ( 2006). Ising-based mo del of opinion formation in a complex netw ork of interpersonal in teractions. Physic a A: Statistic al Me chan- ics and Its Applic ations 361 651–664. [26] Kalisch, M. and B ¨ uhlmann, P. (2007). Estimating h igh-dimensional directed acyclic graphs with th e PC-algori thm. J. Mach. L e arn. R es. 8 613–636. 30 ANAND KUMAR, T AN, HU ANG AND WILLSKY [27] Karger, D. and Srebro, N. (2001). Learnin g Mark ov net works: Maximum boun ded tree-width graphs. In Pr o c e e dings of the Twel f th Annual ACM-SIAM Symp osium on Discr ete Algorithms (Washington, DC, 2001) 392–401. S I AM, Philadelphia, P A. MR1958431 [28] Kearns, M. J. and V azira n i, U. V. (1994). A n Intr o duction to Computational L e arning The ory . MIT Press, Cambridge, MA. MR1292868 [29] Kloks, T. (1994). Only few graphs hav e b ounded treewidth. Springer L e ctur e Notes in C om puter Scienc e 842 51–60. [30] Laciana, C. E. and Ro vere, S. L. (2010). Ising-like agent-based technology dif- fusion mod el: Adoption patterns vs. seeding strategies. Physic a A: Statistic al Me chanics and Its Applic ations 390 1139–114 9. [31] Lauritzen, S. L. (1996). Gr aphic al Mo dels . Oxfor d Statistic al Scienc e Series 17 . Oxford Univ. Press, New Y ork . MR1419991 [32] Levin, D. A. , Peres, Y. and Wilme r, E. L. (2008). Markov Chains and M ixing Times. Amer. Math. So c., Pro vidence, R I. [33] Liu, H. , Xu, M. , Gu, H. , Gup t a, A. , Laffer ty, J. an d W asserman, L. (2011). F orest den sit y estimation. J. Mach. L e arn. R es. 12 907–951. MR2786914 [34] Liu, S. , Ying, L. and Sha kk ott ai, S. (2010). Influence maximization in so cial netw orks: An ising-mo del-based approach. In Pr o c. 48th Annual Al lerton Con- fer enc e on Comm uni c ation, Contr ol, and Computing . [35] Lo v ´ asz, L. , Neumann Lara, V. and Plumme r , M. (1978). Mengerian theorems for paths of b oun ded length. Perio d. M ath. Hungar. 9 269–276. MR0509677 [36] McKa y, B . D. , Wormald, N. C. and Wysocka, B. (2004). S hort cy cles in random regular graphs. Ele ctr on. J. Combin. 11 Research P ap er 66, 12 pp. (electronic). MR2097332 [37] Meinshausen, N . and B ¨ uhlmann, P. (2006). High-dimensional graphs and vari able selection with the lasso. Ann. Statist. 34 1436–14 62. MR2278363 [38] Mitliagkas, I. and Vishw ana th, S. ( 2010). St rong information-theoretic limits for source/model reco very . In Pr o c. 48th Annua l Al lerton Confer enc e on Commu- nic ation, Contr ol and Computing . [39] Netrap alli, P. , Banerjee , S. , Sangha vi , S. and Shakk ott ai, S. (2010). Greedy learning of Marko v netw ork structu re. In Pr o c. 48th Annual Al lerton Confer enc e on Communic ation, Contr ol and Computing . [40] Newman, M. E. J. , W a tts, D. J. and Stroga tz, S. H. (2002). Rand om graph mod els of social netw orks. Pr oc . Natl. A c ad. Sci. USA 99 2566–2572. [41] Ra vikumar, P. , W ainwrig h t, M. J. and Laffer ty, J. (2010). High-dimensional Ising mo del selection using ℓ 1 -regularized logistic regression. Ann. Statist. 38 1287–13 19. MR2662343 [42] Ra vikumar, P. , W ainwright, M. J. , R a skutti, G. and Yu, B. (2011). High- dimensional cov ariance estimation by minimizing ℓ 1 -p enalized log-determinant divergence. El e ctr on. J. Stat. 5 935–980. MR2836766 [43] Santhanam, N. P. and W ai nwright, M. J. (2008). Information-theoretic limits of high-dimensional mo del selection. In International Symp osium on Information The ory . [44] Spir tes, P. and Meek, C. (1995). Learning Ba yesian netw orks with discrete v ariables from data. In Pr o c. of Intl. C onf . on Know le dge Disc overy and Data Mining 294–299 . [45] T an, V. Y. F. , Ana ndkumar, A. , Tong, L. and Willsky, A. S. (2011). A large- deviation analysis of the maximum-lik elihoo d learning of Mark ov tree structures. IEEE T r ans. Inform. The ory 57 1714–1735. MR2815845 STRUCTURE LEAR NING OF ISIN G MOD ELS 31 [46] T an, V. Y. F. , A nandkumar, A. and W i llsky, A. S. (2010). Learning Gaussian tree mo d els: A nalysis of error exp onents and extremal struct u res. IEEE T r ans. Signal Pr o c ess. 58 2701–2714. MR2789417 [47] T an, V. Y. F. , Anandkumar, A. and Willsky, A. S. (2011). Learning high- dimensional Marko v forest distributions: Analysis of error rates. J. Mach. L e arn. R es. 12 1617–1 653. MR2813149 [48] Vega-Redondo, F. (2007). Complex So cial Networks . Ec onometric So ci ety Mono- gr aphs 44 . Cam bridge Univ. Press, Cambridge. MR2361122 [49] W ai nwright, M. J. and Jordan, M. I. (2008). Graphical mo dels, exp onentia l fam- ilies, and vari ational inference. F oundations and T r ends in Machine L e arning 1 1–305. [50] W ang , W. , W ainwright, M. J. and Ramchandran, K. (2010). Information- theoretic bound s on model selection for Gaussian Marko v random fields. I n IEEE I nternational Symp osium on Information The ory Pr o c e e dings (ISIT) . [51] W a tts, D. J. and S troga tz, S. H. (1998). Collective dynamics of ‘small-wo rld’ netw orks. Natur e 393 440–44 2. [52] Graphical M o del of S enate V oting. http://w ww.eecs.berkeley .edu/˜elghaoui/ StatNews/ex senate.h tml . A. Anandkumar F. Huang Center for Per v asive Communica tions & Computing Electrical Engineering & Computer Science Dep ar tment 4408 Engineering Hall Ir vin e, California 926 97 USA E-mail: a.anandkumar@uci.edu furongh@uci.edu V. Y. F. T an Institute for Infocomm Research A*ST AR Singapore and Dep ar tment of Electrical and Computer Engineering Na tional University of Singa pore Singapore E-mail: tan yfv@i2r.a-s tar. edu.sg A. S. Willsky Labora tor y of In forma tion & Decision Systems St at a Center, 77 M assachusetts A ve. Cambridge, Massachusetts 02 139 USA E-mail: willsky@mit.edu
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment