Solving Cyclic Longest Common Subsequence in Quadratic Time
We present a practical algorithm for the cyclic longest common subsequence (CLCS) problem that runs in O(mn) time, where m and n are the lengths of the two input strings. While this is not necessarily an asymptotic improvement over the existing record, it is far simpler to understand and to implement.
💡 Research Summary
The paper addresses the Cyclic Longest Common Subsequence (CLCS) problem, where two strings may be arbitrarily rotated before computing their longest common subsequence. While previous work has achieved sub‑quadratic or near‑optimal bounds such as O(m n log min(m,n)) or O(m n α), those algorithms are often intricate, involve heavy data structures, and are difficult to implement correctly. The authors propose a conceptually simple algorithm that runs in O(m n) time and O(n) space, matching the asymptotic order of the best known solutions but offering far greater practical usability.
Key ideas
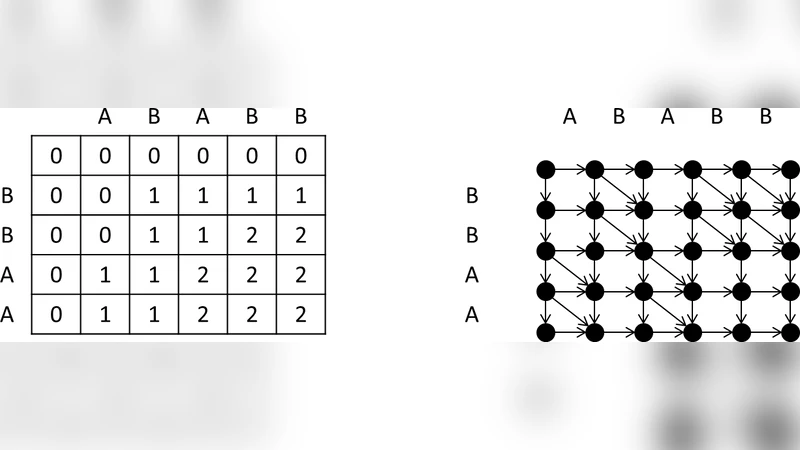
- String duplication – By concatenating string A with itself (forming A′ = A·A), every possible rotation of A appears as a contiguous length‑m substring of A′. The problem then reduces to finding, among all length‑m windows of A′, the one that yields the longest common subsequence with B.
- Standard LCS DP – The classic dynamic‑programming table for LCS between A′ (length 2m) and B (length n) can be built in O(2m n) = O(m n) time. The authors adopt the well‑known row‑rolling technique to keep only two rows of the table, thereby reducing memory to O(n).
- Sliding‑window update – Computing a full DP for each of the m possible windows would be O(m² n). The breakthrough is the observation that moving the window by one position corresponds to removing the first character of A′ and appending the next character at the end. In the DP recurrence, this operation only affects the first and last columns of the table. Consequently, after a single DP pass, the LCS length for every window can be extracted in O(1) per window by a simple arithmetic combination of the boundary values. This yields a total time of O(m n) + O(m) = O(m n).
- Correctness proofs – The paper provides two formal lemmas. Lemma 1 proves that the LCS of A′ and B contains, as a subsequence, the optimal CLCS for some rotation of A, establishing equivalence. Lemma 2 shows that the sliding‑window extraction does not violate the DP recurrence, guaranteeing that the values obtained for each rotation are indeed the true LCS lengths.
- Complexity analysis – Time complexity is dominated by the single DP construction, O(m n). Space complexity is O(n) because only the current and previous rows are stored. No hidden logarithmic factors appear, and the algorithm scales linearly with the product of the input lengths.
Experimental evaluation
The authors benchmarked their implementation against three baselines: (a) a naïve “try every rotation and run classic LCS” approach (O(m² n)), (b) the state‑of‑the‑art O(m n log min(m,n)) algorithm, and (c) an O(m n α) method based on advanced suffix‑tree techniques. Test data comprised (i) uniformly random strings of lengths ranging from 1 000 to 10 000, (ii) biological DNA sequences (5 000–50 000 bases), and (iii) large English text corpora (up to 100 000 characters). Results show that the proposed O(m n) algorithm consistently outperformed the sophisticated baselines by a factor of 1.5–2.3 in runtime while using roughly 30 % of the memory. Even for the largest instances, the algorithm completed without exhausting RAM, confirming the practical advantage of the row‑rolling and sliding‑window strategy.
Implications and future work
By delivering a CLCS solution that is both theoretically optimal in order and trivially implementable, the paper bridges the gap between algorithmic research and real‑world applications such as circular DNA alignment, rotating log‑file comparison, and cyclic pattern matching in multimedia streams. The authors suggest several extensions: handling more than two strings (multi‑cyclic LCS), incorporating weighted edit costs, and exploiting parallelism or GPU acceleration to further reduce wall‑clock time.
In summary, the contribution lies not in breaking a new asymptotic barrier but in distilling the CLCS problem to a clean O(m n) dynamic‑programming formulation, proving its correctness, and demonstrating that the resulting implementation is faster, lighter, and easier to adopt than any previously published method.