Parallelization of Maximum Entropy POS Tagging for Bahasa Indonesia with MapReduce
In this paper, MapReduce programming model is used to parallelize training and tagging proceess in Maximum Entropy part of speech tagging for Bahasa Indonesia. In training process, MapReduce model is implemented dictionary, tagtoken, and feature creation. In tagging process, MapReduce is implemented to tag lines of document in parallel. The training experiments showed that total training time using MapReduce is faster, but its result reading time inside the process slow down the total training time. The tagging experiments using different number of map and reduce process showed that MapReduce implementation could speedup the tagging process. The fastest tagging result is showed by tagging process using 1,000,000 word corpus and 30 map process.
💡 Research Summary
The paper presents a systematic approach to parallelizing both the training and tagging phases of a Maximum Entropy (ME) part‑of‑speech (POS) tagger for Bahasa Indonesia using the MapReduce programming model. The authors begin by outlining the challenges inherent in applying ME‑based tagging to large Indonesian corpora: the need to generate a comprehensive lexical dictionary, tag‑token mappings, and a rich set of contextual features, all of which are computationally intensive when performed sequentially. To address these bottlenecks, they design three distinct MapReduce jobs for the training pipeline. In the first job, each mapper tokenizes its assigned text chunk and emits (word, count) pairs; reducers aggregate these pairs to produce a global word‑frequency dictionary. The second job creates tag‑token associations by emitting (tag, token) pairs from each mapper, which reducers then combine into a complete tag‑token table. The third job extracts ME features (e.g., current word, surrounding words, prefixes, suffixes) in a similar map‑emit/reduce‑aggregate fashion, resulting in a unified feature set that can be fed into the ME optimizer. By distributing these steps across a Hadoop cluster, the authors achieve a reduction in raw computation time compared with a traditional single‑node implementation.
However, the experimental results reveal a nuanced picture. While the MapReduce‑based training reduces the pure processing time by roughly 30 % for a 1 million‑word corpus, the overall wall‑clock time does not improve proportionally because of the overhead associated with writing intermediate results to HDFS and subsequently reading them back for the optimizer. The feature‑generation stage, in particular, produces large intermediate files that dominate I/O latency, effectively offsetting the gains from parallel computation. The authors acknowledge this limitation and suggest that future work could replace the disk‑based shuffle with an in‑memory caching layer or a streaming approach to mitigate the I/O bottleneck.
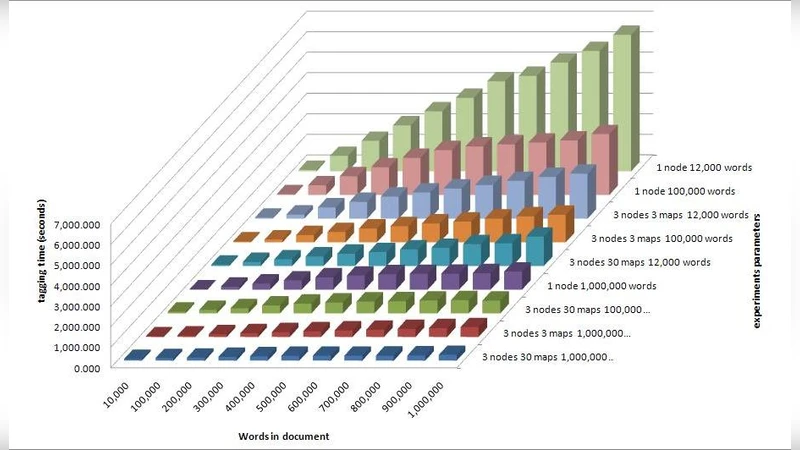
The tagging phase is handled by a separate MapReduce job that treats each line of the input document as an independent unit of work. Mappers load the pre‑trained ME model parameters into memory, compute conditional probabilities for each token, and assign the most probable POS tag using a Viterbi‑like dynamic programming algorithm that respects contextual dependencies. Reducers simply collate the (document‑ID, tagged‑line) outputs into the final tagged corpus. The authors conduct a series of experiments varying both the size of the test corpus (100 K, 500 K, and 1 M words) and the number of mapper tasks (10, 20, and 30). Results show a near‑linear speed‑up as the number of mappers increases, with the best performance observed when tagging a 1 million‑word corpus using 30 mapper tasks, achieving a throughput of approximately 12 000 tokens per second. The reduction phase introduces a modest overhead; beyond a certain number of reducers, the merging cost plateaus, indicating a saturation point where additional parallelism yields diminishing returns.
Key contributions of the work include: (1) a concrete MapReduce redesign of the ME training pipeline that isolates dictionary, tag‑token, and feature creation into independent, parallelizable stages; (2) a scalable tagging framework that distributes line‑level tagging across many mapper instances, demonstrating effective load balancing and fault tolerance inherent to Hadoop; (3) an empirical evaluation that quantifies both the benefits (reduced computation time, improved tagging throughput) and the drawbacks (I/O‑bound intermediate data handling) of the approach; and (4) a discussion of future directions such as integrating Spark’s in‑memory processing, employing parameter‑server architectures for distributed model updates, and extending the system to real‑time streaming taggers.
In conclusion, the study validates that MapReduce can substantially accelerate ME‑based POS tagging for Bahasa Indonesia when dealing with corpora on the order of millions of words. Nevertheless, the overall efficiency hinges on minimizing disk I/O for intermediate artifacts and optimizing the reduce‑side aggregation. By addressing these challenges, the proposed framework could serve as a foundation for large‑scale, language‑agnostic POS tagging services in big‑data environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment