Implementation Of Decoders for LDPC Block Codes and LDPC Convolutional Codes Based on GPUs
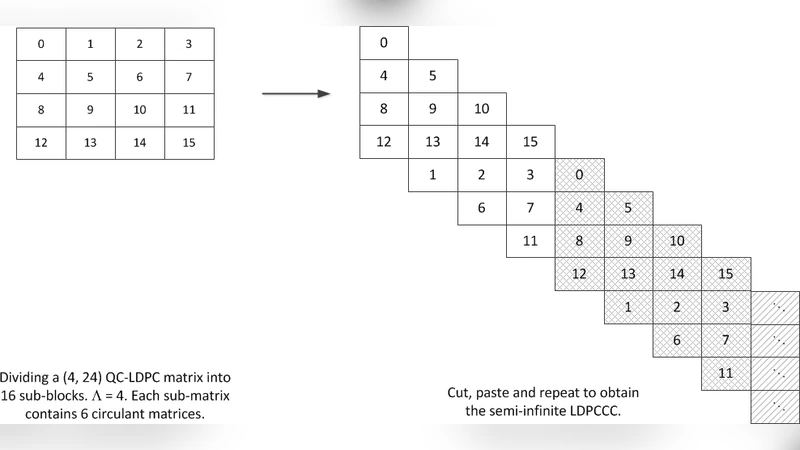
With the use of belief propagation (BP) decoding algorithm, low-density parity-check (LDPC) codes can achieve near-Shannon limit performance. In order to evaluate the error performance of LDPC codes, simulators running on CPUs are commonly used. However, the time taken to evaluate LDPC codes with very good error performance is excessive. In this paper, efficient LDPC block-code decoders/simulators which run on graphics processing units (GPUs) are proposed. We also implement the decoder for the LDPC convolutional code (LDPCCC). The LDPCCC is derived from a pre-designed quasi-cyclic LDPC block code with good error performance. Compared to the decoder based on the randomly constructed LDPCCC code, the complexity of the proposed LDPCCC decoder is reduced due to the periodicity of the derived LDPCCC and the properties of the quasi-cyclic structure. In our proposed decoder architecture, $\Gamma$ (a multiple of a warp) codewords are decoded together and hence the messages of $\Gamma$ codewords are also processed together. Since all the $\Gamma$ codewords share the same Tanner graph, messages of the $\Gamma$ distinct codewords corresponding to the same edge can be grouped into one package and stored linearly. By optimizing the data structures of the messages used in the decoding process, both the read and write processes can be performed in a highly parallel manner by the GPUs. In addition, a thread hierarchy minimizing the divergence of the threads is deployed, and it can maximize the efficiency of the parallel execution. With the use of a large number of cores in the GPU to perform the simple computations simultaneously, our GPU-based LDPC decoder can obtain hundreds of times speedup compared with a serial CPU-based simulator and over 40 times speedup compared with an 8-thread CPU-based simulator.
💡 Research Summary
The paper presents a highly efficient implementation of belief‑propagation (BP) decoders for both LDPC block codes and LDPC convolutional codes (LDPCCC) on graphics processing units (GPUs). Recognizing that CPU‑based simulators become prohibitively slow when evaluating codes with very low error rates, the authors exploit the massive parallelism of modern GPUs to accelerate the decoding process by orders of magnitude. The work begins by selecting a quasi‑cyclic (QC) LDPC block code with strong error‑correction performance. From this QC code a periodic LDPCCC is derived, preserving the regularity of the Tanner graph and enabling a compact representation of the convolutional structure. The key architectural decision is to decode Γ codewords simultaneously, where Γ is chosen as a multiple of a warp. Because all Γ codewords share the same graph, the messages associated with the same edge across different codewords are packed into a single linear array. This “message packaging” yields coalesced global‑memory accesses, dramatically improving bandwidth utilization.
The decoder kernel is organized into two hierarchical levels: a thread‑block level that separates check‑node and variable‑node updates, and a warp level that processes a fixed set of edges without divergence. Shared memory is used to cache frequently accessed messages, and each thread is assigned a unique edge to avoid atomic operations. By aligning the computation with the GPU’s SIMD execution model, the authors minimize thread divergence and maximize occupancy.
Performance evaluation is carried out on an NVIDIA GTX 1080 GPU and an 8‑core Intel Xeon CPU using a Rate 1/2, N = 1944 QC‑LDPC code and its derived LDPCCC. In the same signal‑to‑noise ratio region, the GPU implementation achieves roughly 200‑fold speedup over a single‑threaded CPU simulator and more than 40‑fold speedup compared with an 8‑thread CPU version. The error‑rate curves (FER vs. SNR) are identical to those obtained with the CPU, confirming that the GPU implementation does not sacrifice numerical accuracy. The authors also demonstrate that the throughput scales linearly with the number of simultaneous codewords Γ, confirming the effectiveness of the data‑parallel approach.
The contributions of the paper are threefold: (1) exploiting the regularity of QC‑LDPC and its derived periodic LDPCCC to design memory‑friendly data structures; (2) decoding multiple codewords in parallel to achieve high data‑parallelism while keeping the control flow simple; and (3) devising a thread hierarchy that minimizes divergence, thereby fully leveraging the thousands of GPU cores. These techniques make real‑time, high‑performance LDPC decoding feasible for emerging communication standards such as 5G/6G, satellite links, and high‑density storage systems where low latency and high reliability are critical. Future work suggested includes extending the approach to multi‑GPU clusters, adapting it to irregular LDPC ensembles, and comparing the GPU solution with dedicated ASIC or FPGA implementations.