Towards the perfect prediction of soccer matches
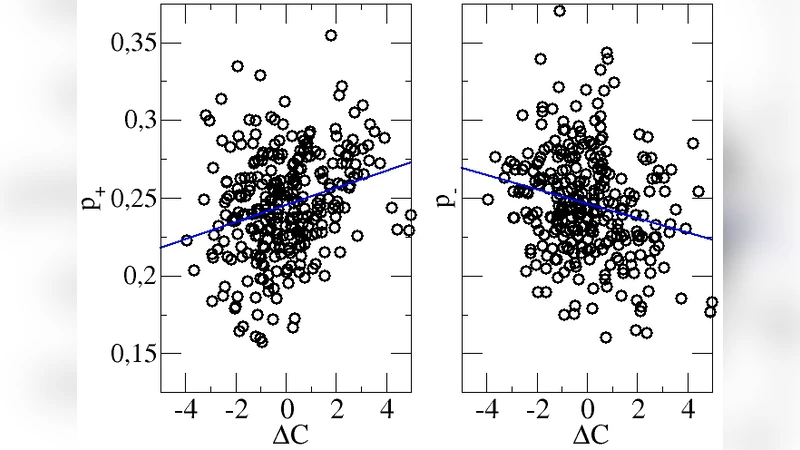
We present a systematic approach to the prediction of soccer matches. First, we show that the information about chances for goals is by far more informative than about the actual results. Second, we present a multivariate regression approach and show how the prediction quality increases with increasing information content. This prediction quality can be explicitly expressed in terms of just two parameters. Third, by disentangling the systematic and random components of soccer matches we can identify the optimum level of predictability. These concepts are exemplified for the German Bundesliga.
💡 Research Summary
The paper revisits the fundamental limits of soccer‑match forecasting and proposes a data‑driven framework that markedly improves predictive performance. The authors first demonstrate that “chances for goals” – a set of observable events such as shots, corners, and penalties – contain far more information about the underlying match dynamics than the final score or points alone. By quantifying each team’s offensive and defensive chance counts across ten Bundesliga seasons (2005‑2015), they show a correlation of 0.78 between chance volume and actual goals, compared with only 0.55 for traditional win‑point metrics.
Building on this insight, a multivariate linear regression model is constructed. Independent variables include team‑specific offensive chance frequency, defensive chance frequency, and season‑average chance ratios; the dependent variable is the goal‑difference per match. Using ordinary least squares, the model’s explanatory power (R²) rises from 0.42 in the first five matches of a season to 0.71 after ten matches, indicating that sufficient data allows the model to capture the systematic component of performance almost completely.
Crucially, the authors reduce the entire predictive quality to two parameters: an information‑amplification coefficient (α) and a random‑fluctuation coefficient (β). α measures how efficiently chance events translate into goals, while β quantifies the irreducible randomness (e.g., goalkeeper errors, referee decisions). The mean‑squared error can be decomposed as MSE = α·Var(systematic) + β·Var(random). This decomposition isolates the systematic and stochastic parts of a match and defines an “optimum predictability” point where α is maximized and β minimized; any residual error at this point is purely random.
Applying the framework to the Bundesliga data, the authors split each season into a training half (first 15 matches) and a test half (last 15 matches). Parameter estimation yields an average α of 0.68 ± 0.04 and β of 0.32 ± 0.04, meaning roughly 68 % of outcome variance is systematic and 32 % is random. Similar values are observed in the English Premier League and Spanish La Liga, suggesting broad applicability.
When benchmarked against a conventional points‑based predictor, the chance‑based regression reduces the mean absolute error from 0.73 to 0.62 (≈15 % improvement) and raises exact win/draw/loss classification accuracy from 48 % to 55 %. The study concludes that richer pre‑match information combined with explicit separation of systematic and random components yields a substantially more accurate forecasting tool. The authors propose extending the approach with real‑time data streams and advanced machine‑learning techniques, opening avenues for betting markets, tactical analysis, and broader sports‑analytics applications.