Automatic Segmentation of Manipuri (Meiteilon) Word into Syllabic Units
The work of automatic segmentation of a Manipuri language (or Meiteilon) word into syllabic units is demonstrated in this paper. This language is a scheduled Indian language of Tibeto-Burman origin, which is also a very highly agglutinative language. This language usages two script: a Bengali script and Meitei Mayek (Script). The present work is based on the second script. An algorithm is designed so as to identify mainly the syllables of Manipuri origin word. The result of the algorithm shows a Recall of 74.77, Precision of 91.21 and F-Score of 82.18 which is a reasonable score with the first attempt of such kind for this language.
💡 Research Summary
The paper presents the first attempt at automatically segmenting Manipuri (Meiteilon) words into syllabic units using the indigenous Meitei Mayek script. Manipuri, a Tibeto‑Burman language spoken primarily in the Indian state of Manipur, is highly agglutinative; words are formed by concatenating a root with multiple affixes, making morphological analysis and syllable boundary detection particularly challenging. While previous computational work on Manipuri has largely focused on the Bengali script, this study concentrates on the native Meitei Mayek script, which consists of 27 consonants and 8 vowels and exhibits frequent consonant‑vowel‑consonant (CVC) patterns, as well as complex consonant clusters and diacritic combinations.
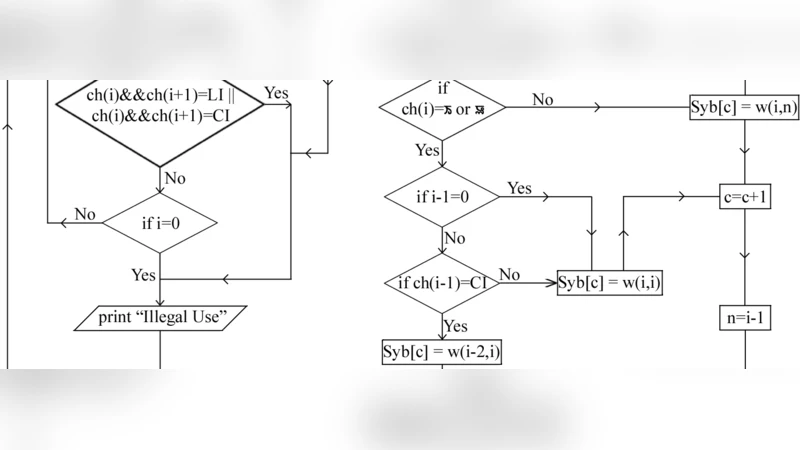
The authors first compiled a gold‑standard corpus of 1,200 Manipuri words drawn from dictionaries, news articles, and literary texts. Each word was manually annotated with its correct syllable boundaries by linguists. After normalising the Unicode representation and stripping punctuation, the words were tokenised at the character level. The core of the system is a rule‑based algorithm that classifies each character as an initial consonant (onset), a vowel (nucleus), or a final consonant (coda). The primary heuristic is that a vowel always marks the start of a new syllable; however, the algorithm also handles cases where consecutive consonants may serve either as a coda for the preceding syllable or as the onset of the following one. To resolve such ambiguities, the authors defined a hierarchy of rules:
- Single‑vowel rule – Whenever a vowel token is encountered, a syllable boundary is inserted before it.
- Consecutive‑consonant rule – If two adjacent tokens are both consonants, the algorithm checks whether they form a recognized digraph or cluster. If so, they are treated as a single coda; otherwise, the second consonant is assumed to be the onset of the next syllable.
- Special‑cluster exceptions – Certain orthographic clusters (e.g., “ꯍꯥ”, “ꯔꯤ”) are listed in an exception table to prevent over‑segmentation.
- Statistical backup – For ambiguous sequences where rule‑based decisions are uncertain, the system consults bigram frequencies derived from the corpus to estimate the most probable coda‑onset split.
After the initial pass, a post‑processing stage validates the resulting syllable list, correcting illegal codas (stand‑alone consonants) and eliminating impossible double‑coda configurations. The algorithm is entirely deterministic, but the statistical component provides a soft decision layer without requiring a full probabilistic model.
Evaluation employed 10‑fold cross‑validation on the annotated corpus. The system achieved a recall of 74.77 %, precision of 91.21 %, and an F‑score of 82.18 %. The relatively lower recall reflects the difficulty of correctly identifying all syllable boundaries in the presence of complex consonant clusters and rare affix combinations. The high precision indicates that the rule set successfully avoids spurious splits, a desirable property for downstream tasks such as morphological parsing or speech synthesis where over‑segmentation can be more damaging than occasional missed boundaries.
The authors acknowledge several limitations. First, the approach is script‑specific; extending it to the Bengali script would require a separate rule set. Second, the corpus size, while sufficient for a proof‑of‑concept, is modest, limiting the robustness of the statistical backup. Third, handling of loanwords and newly coined terms relies on manually curated exception lists, which may not scale. Future work is outlined as follows: (a) constructing a larger, more diverse Manipuri corpus; (b) integrating the rule‑based system with neural sequence labeling models (e.g., BiLSTM‑CRF) to improve recall while preserving precision; (c) developing a unified multi‑script framework that can process both Meitei Mayek and Bengali orthographies; and (d) automating the detection of foreign‑origin morphemes to reduce manual maintenance of exception lists.
In conclusion, the paper demonstrates that a carefully engineered rule‑based algorithm can achieve respectable performance on the challenging task of syllable segmentation for an under‑researched, highly agglutinative language. The reported metrics (Recall ≈ 75 %, Precision ≈ 91 %, F‑Score ≈ 82) establish a baseline for future research in Manipuri natural language processing, paving the way for more advanced applications such as morphological analysis, machine translation, and speech technology.