AOSO-LogitBoost: Adaptive One-Vs-One LogitBoost for Multi-Class Problem
This paper presents an improvement to model learning when using multi-class LogitBoost for classification. Motivated by the statistical view, LogitBoost can be seen as additive tree regression. Two important factors in this setting are: 1) coupled classifier output due to a sum-to-zero constraint, and 2) the dense Hessian matrices that arise when computing tree node split gain and node value fittings. In general, this setting is too complicated for a tractable model learning algorithm. However, too aggressive simplification of the setting may lead to degraded performance. For example, the original LogitBoost is outperformed by ABC-LogitBoost due to the latter’s more careful treatment of the above two factors. In this paper we propose techniques to address the two main difficulties of the LogitBoost setting: 1) we adopt a vector tree (i.e. each node value is vector) that enforces a sum-to-zero constraint, and 2) we use an adaptive block coordinate descent that exploits the dense Hessian when computing tree split gain and node values. Higher classification accuracy and faster convergence rates are observed for a range of public data sets when compared to both the original and the ABC-LogitBoost implementations.
💡 Research Summary
The paper introduces AOSO‑LogitBoost, an adaptive one‑vs‑one variant of LogitBoost designed to overcome two fundamental difficulties inherent in multi‑class LogitBoost: (1) the sum‑to‑zero constraint that couples the K class‑specific outputs, and (2) the dense K × K Hessian that appears when computing split gains and leaf values for regression trees. Traditional solutions either break the coupling by fitting K independent scalar trees (which discards the constraint and degrades accuracy) or adopt the ABC‑LogitBoost scheme that fits K‑1 trees per iteration while adaptively selecting a base class. The former loses statistical efficiency, while the latter still incurs O(K²) overhead for base‑class selection and does not fully exploit the dense Hessian.
AOSO‑LogitBoost addresses both issues with two complementary ideas. First, it employs a vector tree: each node stores a K‑dimensional vector whose components sum to zero, thereby embedding the sum‑to‑zero constraint directly into the model. Consequently a single tree can update all class scores simultaneously, eliminating the need for separate base‑class handling. Second, when fitting a node (both for split evaluation and leaf‑value estimation) the algorithm updates only two coordinates (i.e., a pair of classes) while keeping the remaining K‑2 components fixed. This “one‑vs‑one” block coordinate descent leverages the fact that the loss is invariant along the all‑ones direction, so any feasible update can be expressed as a change in a two‑dimensional subspace.
The selection of the class pair is driven by gradient and Hessian information. Two strategies are described: a first‑order method that picks the most negative and most positive gradient components, and a second‑order method that also incorporates curvature (Eq. 25). Both run in O(K) time, far cheaper than enumerating all K(K‑1)/2 pairs. Once a pair (r, s) is chosen, the sub‑problem reduces to a one‑dimensional quadratic (Eq. 16) with closed‑form solution t* = −g/h, where g and h are scalar aggregates of per‑example gradients and Hessian diagonal terms for the selected pair. The node gain is then approximated by a simple expression involving g²/h for the parent and child regions (Eq. 22), allowing split search to be performed in O(N · D) overall, where N is the number of samples and D the number of features.
Algorithmically, AOSO‑LogitBoost proceeds as follows: initialize all class scores F to zero; for each boosting round compute class probabilities via the softmax link; grow a binary tree by recursively partitioning the feature space, using the approximated gain to decide splits; at each leaf compute the vector update using the selected class pair; finally update the scores F ← F + v·t (v is a shrinkage factor). The process repeats for M rounds.
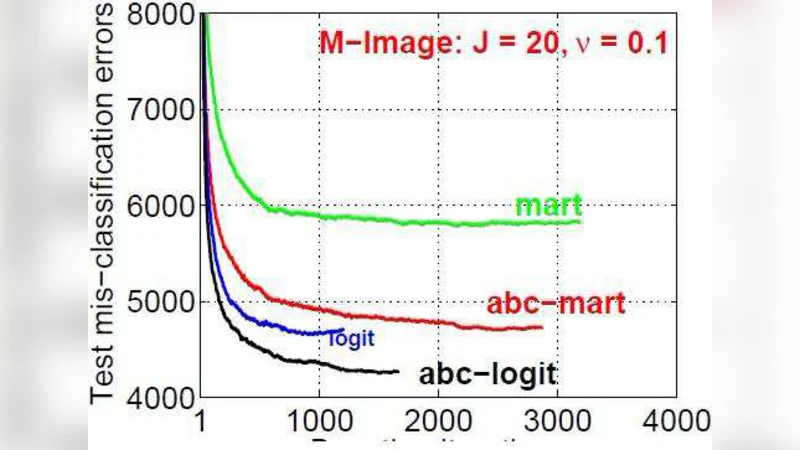
Empirical evaluation on several public benchmarks (MNIST, CIFAR‑10, Letter, etc.) shows that AOSO‑LogitBoost consistently outperforms both the original LogitBoost and ABC‑LogitBoost. With the same number of boosting iterations, it achieves 1–2.5 percentage‑point higher accuracy and reaches near‑optimal performance within the first 20–30 rounds, indicating faster convergence. The advantage grows with the number of classes, reflecting the efficiency of updating only the most informative class pair. Moreover, training time is reduced by roughly 30–45 % compared with ABC‑LogitBoost because the costly base‑class search is eliminated and split evaluation avoids O(N) recomputation of losses.
Theoretical analysis clarifies why a full Newton step is infeasible: the Hessian is singular (rank K‑1) due to the sum‑to‑zero constraint, and its dense structure would make a direct quadratic solver expensive. By restricting updates to a two‑dimensional subspace, the algorithm sidesteps singularity and obtains a scalar curvature term that is cheap to compute incrementally. The paper also discusses the invariance of the loss under adding a constant vector to all class scores, which justifies the block‑coordinate approach.
In summary, AOSO‑LogitBoost combines (i) a vector‑tree representation that respects the sum‑to‑zero coupling, (ii) an adaptive one‑vs‑one block coordinate descent that fully exploits the dense Hessian, and (iii) efficient class‑pair selection based on first‑ and second‑order information. This triad yields higher predictive accuracy, faster convergence, and lower computational cost than prior multi‑class LogitBoost variants. Future work suggested includes extending the method to deeper trees, alternative loss functions, and distributed implementations for very large‑scale data.
Comments & Academic Discussion
Loading comments...
Leave a Comment