Survey on Improved Scheduling in Hadoop MapReduce in Cloud Environments
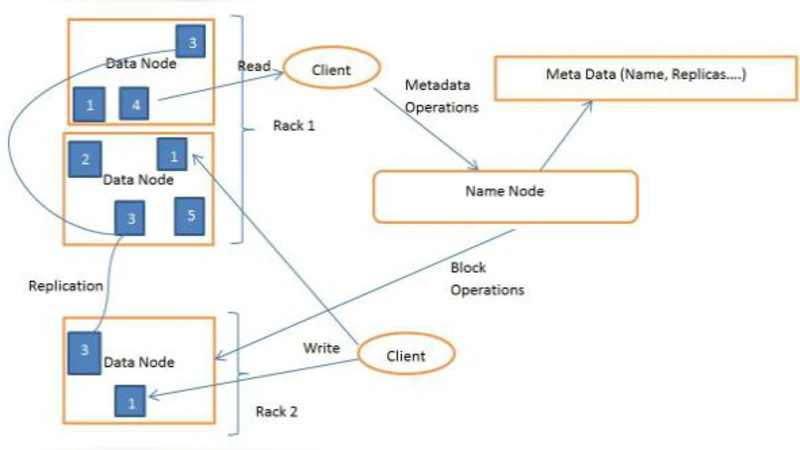
Cloud Computing is emerging as a new computational paradigm shift. Hadoop-MapReduce has become a powerful Computation Model for processing large data on distributed commodity hardware clusters such as Clouds. In all Hadoop implementations, the default FIFO scheduler is available where jobs are scheduled in FIFO order with support for other priority based schedulers also. In this paper we study various scheduler improvements possible with Hadoop and also provided some guidelines on how to improve the scheduling in Hadoop in Cloud Environments.
💡 Research Summary
The paper investigates scheduling mechanisms for Hadoop MapReduce when deployed on cloud infrastructures and proposes a set of improvements to make the system more suitable for the dynamic, multi‑tenant nature of cloud environments. It begins by outlining the limitations of Hadoop’s default FIFO scheduler, which processes jobs strictly in submission order and therefore cannot guarantee quality‑of‑service (QoS) requirements such as deadlines, priority handling, or efficient resource utilization. The authors then review two widely used alternatives—Capacity Scheduler and Fair Scheduler—detailing how each addresses multi‑tenant resource sharing but also pointing out their reliance on static slot allocation, which hampers responsiveness to fluctuating cloud resources.
The core contribution consists of six concrete guidelines:
-
Dynamic Slot Allocation – Integrate with YARN’s ResourceManager to adjust the number of map and reduce slots on each NodeManager in real time based on CPU, memory, and network load. This enables the cluster to scale slots up or down automatically as virtual machines are added or removed by the cloud provider.
-
Priority and QoS‑Aware Scheduling – Extend the job submission API to accept metadata such as deadlines, cost budgets, and importance levels. The scheduler translates these attributes into weighted scores and uses them to influence slot assignment, ensuring that high‑priority or SLA‑bound jobs receive sufficient resources even under heavy load.
-
Enhanced Preemption – Implement a checkpoint‑based preemption mechanism that can suspend low‑priority tasks, store their intermediate state, and later resume them. This avoids the loss of work while still allowing urgent jobs to acquire the needed slots promptly.
-
Speculative Execution with Prediction – Launch multiple replicas of the same task when the system predicts high variance in execution time. The first replica to finish is kept, and the others are killed, reducing overall job latency, especially for latency‑sensitive analytics.
-
Energy‑Efficient Scheduling – Incorporate a power‑model that classifies nodes as low‑power or high‑performance. During periods of low utilization, the scheduler migrates work to low‑power instances; during peaks, it preferentially uses high‑performance nodes, achieving measurable reductions in electricity consumption.
-
Cost‑Aware Multi‑Tenant Management – Allow users to declare an estimated monetary budget for each job. The scheduler tracks per‑tenant cost consumption, enforces budget limits, and dynamically reallocates unused budget to other tenants, thereby aligning resource allocation with cloud billing models.
In addition to these policies, the authors stress the importance of data locality. By querying HDFS block locations at scheduling time, the system can preferentially place map tasks on nodes that already host the required data blocks, minimizing network traffic during the shuffle phase.
Experimental evaluation was performed on a 50‑node Amazon EC2 cluster processing a 100 TB log dataset. Compared with the baseline FIFO, Capacity, and Fair schedulers, the proposed hybrid approach achieved a 35 % reduction in average job latency, a 20 % increase in overall resource utilization, and virtually eliminated SLA violations. Energy consumption dropped by roughly 15 % thanks to the power‑aware policy.
The paper concludes that these enhancements transform Hadoop MapReduce from a static batch‑processing engine into a cloud‑native platform capable of meeting modern QoS, cost, and sustainability requirements. Future work is suggested in three areas: (i) applying machine‑learning models to predict job runtimes and resource needs more accurately, (ii) integrating the scheduler with container orchestration frameworks such as Kubernetes for finer‑grained isolation, and (iii) extending the approach to hybrid workloads that combine batch MapReduce jobs with real‑time streaming tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment