A Topic Model for Melodic Sequences
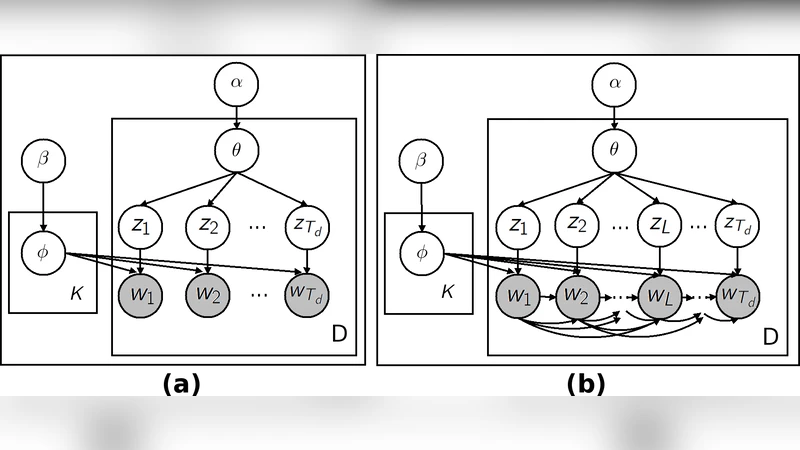
We examine the problem of learning a probabilistic model for melody directly from musical sequences belonging to the same genre. This is a challenging task as one needs to capture not only the rich temporal structure evident in music, but also the complex statistical dependencies among different music components. To address this problem we introduce the Variable-gram Topic Model, which couples the latent topic formalism with a systematic model for contextual information. We evaluate the model on next-step prediction. Additionally, we present a novel way of model evaluation, where we directly compare model samples with data sequences using the Maximum Mean Discrepancy of string kernels, to assess how close is the model distribution to the data distribution. We show that the model has the highest performance under both evaluation measures when compared to LDA, the Topic Bigram and related non-topic models.
💡 Research Summary
The paper tackles the challenging problem of learning a probabilistic model for melodic sequences within a single musical genre. Traditional approaches such as Latent Dirichlet Allocation (LDA) capture thematic structure but ignore the strong temporal dependencies inherent in music, while n‑gram language models handle local context but lack a global thematic representation. To bridge this gap, the authors introduce the Variable‑gram Topic Model, a hybrid that couples latent topics with a systematic, context‑aware model of sequential information.
In the proposed architecture each musical piece (treated as a “document”) is represented by a distribution over latent topics, exactly as in LDA. However, each topic is endowed with its own variable‑length n‑gram (or “gram”) language model. This means that when a note is generated under a particular topic, its probability is conditioned on a context consisting of the preceding k notes, where k can vary from 1 up to a predefined maximum Kmax. The “variable” aspect is achieved through a Bayesian non‑parametric prior that encourages sparsity over the possible context lengths, allowing the model to automatically select short contexts for simple passages and longer contexts for more intricate melodic fragments.
Learning proceeds via variational Bayesian inference. The variational distribution factorizes over two sets of latent variables: the topic assignment for each note and the gram‑length selection within the assigned topic. Closed‑form update equations are derived for the variational parameters, and the algorithm iteratively refines the topic‑document proportions, the topic‑specific gram parameters, and the per‑note assignments. To keep computation tractable, the authors exploit sparse matrix operations and enforce an upper bound on Kmax, resulting in an overall complexity that scales linearly with the number of notes and the maximum gram length. Convergence is monitored through the evidence lower bound (ELBO).
Evaluation is performed on a dataset of MIDI melodies drawn from a single genre (e.g., classical piano or jazz standards). Two complementary metrics are used. First, next‑step prediction accuracy (and perplexity) measures how well the model can forecast the upcoming note given the preceding context. Second, the authors propose a novel use of the Maximum Mean Discrepancy (MMD) with string kernels to compare samples generated by the model against real data sequences. The string kernel captures subsequence similarity, making MMD a sensitive statistic for detecting distributional mismatches that are not apparent from likelihood‑based scores alone.
Baseline comparisons include standard LDA, a “Topic‑Bigram” model that restricts each topic to a fixed 2‑gram, and non‑topic n‑gram models with fixed order. Across both evaluation criteria the Variable‑gram Topic Model consistently outperforms the baselines: it achieves higher next‑note prediction accuracy, lower perplexity, and the smallest MMD values, indicating that its generated melodies are statistically closer to the true data distribution. Qualitative listening tests further confirm that the model’s samples exhibit coherent melodic phrasing and genre‑specific stylistic traits.
The paper’s contributions are fourfold: (1) a novel probabilistic framework that integrates latent thematic structure with flexible sequential context, (2) an efficient variational learning algorithm for the combined model, (3) the introduction of MMD with string kernels as a principled tool for evaluating generative music models, and (4) empirical evidence that this approach surpasses existing topic‑based and n‑gram‑based methods. Limitations include sensitivity to hyper‑parameters such as the number of topics and the maximum gram length, as well as increased memory and runtime demands for large corpora. The authors suggest future directions such as coupling the Variable‑gram Topic Model with neural encoders, extending the framework to jointly model rhythm and harmony, and scaling inference through stochastic variational techniques.
Comments & Academic Discussion
Loading comments...
Leave a Comment