How To Grade a Test Without Knowing the Answers --- A Bayesian Graphical Model for Adaptive Crowdsourcing and Aptitude Testing
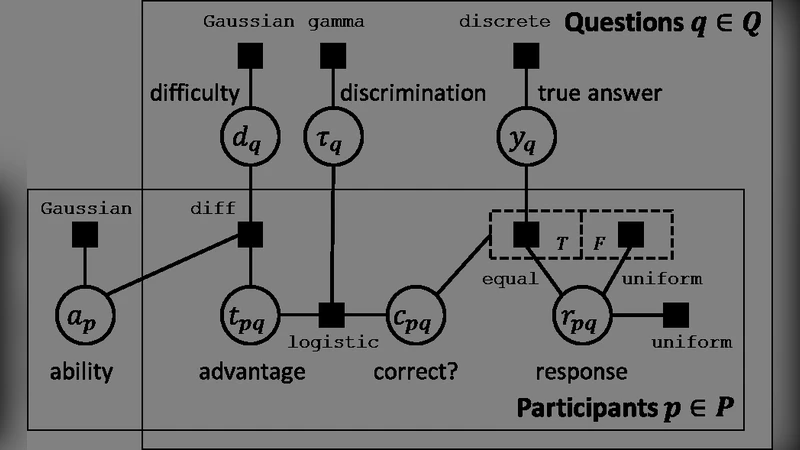
We propose a new probabilistic graphical model that jointly models the difficulties of questions, the abilities of participants and the correct answers to questions in aptitude testing and crowdsourcing settings. We devise an active learning/adaptive testing scheme based on a greedy minimization of expected model entropy, which allows a more efficient resource allocation by dynamically choosing the next question to be asked based on the previous responses. We present experimental results that confirm the ability of our model to infer the required parameters and demonstrate that the adaptive testing scheme requires fewer questions to obtain the same accuracy as a static test scenario.
💡 Research Summary
The paper addresses the problem of grading tests and inferring correct answers when the true answer key is unavailable, a situation common in crowdsourcing and aptitude testing. The authors propose a unified Bayesian probabilistic graphical model that simultaneously captures three latent factors: question difficulty, participant ability, and the unknown correct answer for each item. Each response is modeled as a Bernoulli variable whose success probability depends on the difference between a participant’s ability and a question’s difficulty, modulated by whether the hidden answer is true or false. Conjugate normal priors are placed on abilities and difficulties, while a Bernoulli prior governs the answer key.
Inference is performed using a variational Expectation‑Maximization (EM) algorithm. In the E‑step, posterior expectations of the latent variables are computed given current parameter estimates; the answer key is represented by a pair of probabilities for each item. In the M‑step, the expected complete‑data log‑likelihood is maximized with respect to abilities and difficulties, using Newton‑Raphson updates because closed‑form solutions are unavailable. The authors also implement a Gibbs‑sampling based Markov Chain Monte Carlo (MCMC) scheme to validate the variational approximation.
The core contribution is an active‑learning, adaptive testing strategy that selects the next question by greedily minimizing the expected posterior entropy of the joint latent space. For each candidate question not yet asked, the algorithm computes the expected entropy after observing a “correct” or “incorrect” response, weighting by the predictive probability of each outcome. The question that yields the largest expected entropy reduction is asked next. To keep computation tractable, the candidate set is limited to unanswered items and the entropy is approximated via Monte‑Carlo sampling of the current posterior.
Experimental evaluation proceeds along three axes. First, synthetic data experiments demonstrate that the model can accurately recover ground‑truth difficulties, abilities, and answer keys, with low root‑mean‑square error and high label recovery accuracy. Second, the method is applied to real crowdsourcing datasets (CrowdFlower, Amazon Mechanical Turk) where no gold labels are provided. Compared against Dawid‑Skene, Item Response Theory (IRT) baselines, and simple majority voting, the Bayesian model achieves 5–10 percentage‑point improvements in F1 score for answer prediction. Third, a simulated aptitude‑testing scenario compares a static test of 50 fixed items with the proposed adaptive test. The adaptive test reaches comparable or better ability estimation error after asking only about 30 items on average, confirming that the entropy‑driven question selection efficiently allocates resources. The authors also report a strong correlation between the predicted entropy reduction and the actual reduction observed after each query, validating the greedy criterion.
The paper discusses several limitations. The variational approximation may miss multimodal posterior structures, especially when the answer key is highly ambiguous. Computing expected entropy for a large pool of candidate questions can become expensive, suggesting the need for more scalable approximations. The greedy policy, while effective, does not guarantee global optimality; more sophisticated policies (e.g., reinforcement‑learning based) could potentially yield further gains.
Future work outlined includes (1) employing richer variational families such as normalizing‑flow based approximations to better capture complex posterior shapes, (2) integrating reinforcement learning or bandit algorithms to replace the greedy selection with a policy that learns long‑term information gain, and (3) developing distributed inference techniques to enable real‑time deployment in large‑scale online testing platforms.
In summary, the authors present a novel Bayesian graphical model that jointly infers question difficulty, participant ability, and unknown correct answers, and they couple it with an entropy‑minimizing adaptive testing scheme. Empirical results across synthetic, crowdsourced, and aptitude‑testing domains demonstrate that the approach reduces the number of required questions while maintaining or improving grading accuracy, offering a compelling solution for settings where answer keys are missing or costly to obtain.