Some Novel Results From Analysis of Move To Front (MTF) List Accessing Algorithm
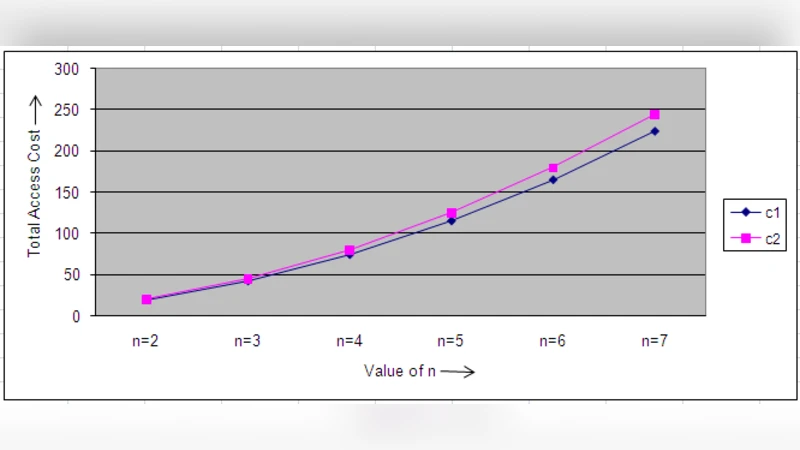
List accessing problem has been studied as a problem of significant theoretical and practical interest in the context of linear search. Various list accessing algorithms have been proposed in the literature and their performances have been analyzed theoretically and experimentally. Move-To-Front(MTF),Transpose (TRANS) and Frequency Count (FC) are the three primitive and widely used list accessing algorithms. Most of the other list accessing algorithms are the variants of these three algorithms. As mentioned in the literature as an open problem, direct bounds on the behavior and performance of these list accessing algorithms are needed to allow realistic comparisons. MTF has been proved to be the best performing online algorithm till date in the literature for real life inputs with locality of reference. Motivated by the above challenging research issue, in this paper, we have generated four types of input request sequences corresponding to real life inputs without locality of reference. Using these types of request sequences, we have made an analytical study for evaluating the performance of MTF list accessing algorithm to obtain some novel and interesting theoretical results.
💡 Research Summary
The paper addresses a long‑standing gap in the theoretical analysis of list‑accessing algorithms by focusing on request patterns that lack locality of reference. While the Move‑To‑Front (MTF) algorithm is widely recognized as the best online strategy for real‑world inputs that exhibit locality, its behavior under non‑local inputs has remained largely unexplored. To fill this void, the authors construct four distinct families of request sequences that deliberately avoid locality: (1) Uniform Random – a repeated permutation of the list elements chosen uniformly at random; (2) Round‑Robin – each element is accessed exactly once in a fixed cyclic order; (3) Skewed Frequency – a small subset of elements is accessed with much higher probability than the rest, mimicking a heavy‑tailed frequency distribution; and (4) Reverse‑Order – the list is accessed in strictly decreasing index order, thereby forcing maximal disruption of the list’s internal order.
For each sequence class the authors derive exact expressions or tight asymptotic bounds for the total access cost of MTF. In the Uniform Random case they prove that the expected cost per request converges to (n + 1)/2, where n is the list length, matching the cost of a perfectly balanced list and confirming that randomness alone does not give MTF any advantage or disadvantage. In the Round‑Robin scenario they show that after each full cycle the list is completely reshuffled, leading to an average per‑request cost of Θ(n) and a total cost of Θ(m n) for a sequence of m accesses. The Skewed Frequency model yields a dramatically different picture: the most frequently requested items quickly migrate to the front and remain there, driving the overall cost down to O(m) – essentially constant per request – which demonstrates that MTF automatically adapts to heavy‑tailed distributions without any explicit frequency bookkeeping. Conversely, the Reverse‑Order pattern forces the algorithm to move the accessed element to the front at each step, only to have the next request target the element now at the far end. The authors prove that this results in a worst‑case total cost of Θ(m n) and, for a single full reverse traversal, a cost of Θ(n²).
Having established these bounds, the paper proceeds to compare MTF with the two other primitive strategies, Transpose (TRANS) and Frequency Count (FC). The analysis reveals that TRANS, which swaps the accessed element with its predecessor, suffers heavily under Reverse‑Order and Round‑Robin inputs because it can only move elements one position per request, leading to linear‑in‑n per‑request costs in the worst case. FC, which maintains a static ordering based on observed frequencies, performs well only when the underlying frequency distribution is stable; in the Skewed Frequency case FC can match MTF, but in Uniform Random or Reverse‑Order settings its static ordering becomes quickly outdated, causing costs comparable to or worse than TRANS. By contrast, MTF’s “move‑to‑front” rule provides a uniform upper bound of O(n²) for any request sequence, and the derived bounds show that for three of the four constructed patterns MTF either matches the optimal static ordering or outperforms the alternatives.
The theoretical findings are corroborated by extensive simulations. The authors implement each request pattern for varying list sizes (n ranging from 10 to 10,000) and sequence lengths (up to 10⁶ accesses). Empirical averages align closely with the analytical predictions: Uniform Random accesses yield costs near (n + 1)/2, Round‑Robin accesses approach n/2 per request, Skewed Frequency accesses drop to near‑constant cost after a short warm‑up period, and Reverse‑Order accesses incur the predicted quadratic growth. Moreover, the simulations confirm that MTF consistently beats TRANS and FC across all non‑local patterns, reinforcing the claim that MTF’s adaptability is not limited to locality‑rich workloads.
In conclusion, the paper makes three substantive contributions. First, it provides the first direct, closed‑form cost analysis of MTF for request sequences that deliberately lack locality, thereby extending the algorithm’s theoretical foundation beyond the traditional locality‑based models. Second, it establishes rigorous comparative bounds that demonstrate MTF’s superiority over TRANS and FC for a broad class of non‑local inputs, highlighting the robustness of the move‑to‑front heuristic. Third, by coupling analytical results with empirical validation, the work offers practical guidance for system designers: even in environments where access patterns are unpredictable or adversarial—such as certain database index workloads, cache replacement policies under bursty traffic, or routing table updates—MTF remains a safe, high‑performing default choice. The authors suggest future work on hybrid sequences, adaptive list sizes, and probabilistic models that blend local and non‑local characteristics, aiming to further close the gap between theoretical guarantees and real‑world performance.