Bootstrapping Monte Carlo Tree Search with an Imperfect Heuristic
We consider the problem of using a heuristic policy to improve the value approximation by the Upper Confidence Bound applied in Trees (UCT) algorithm in non-adversarial settings such as planning with large-state space Markov Decision Processes. Current improvements to UCT focus on either changing the action selection formula at the internal nodes or the rollout policy at the leaf nodes of the search tree. In this work, we propose to add an auxiliary arm to each of the internal nodes, and always use the heuristic policy to roll out simulations at the auxiliary arms. The method aims to get fast convergence to optimal values at states where the heuristic policy is optimal, while retaining similar approximation as the original UCT in other states. We show that bootstrapping with the proposed method in the new algorithm, UCT-Aux, performs better compared to the original UCT algorithm and its variants in two benchmark experiment settings. We also examine conditions under which UCT-Aux works well.
💡 Research Summary
This paper addresses the challenge of improving Monte‑Carlo Tree Search (MCTS) in large‑state, non‑adversarial Markov Decision Processes (MDPs) by incorporating an imperfect heuristic policy. The authors observe that existing enhancements to the Upper Confidence Bound applied in Trees (UCT) algorithm either modify the action‑selection formula at internal nodes (e.g., PUCT, RAVE) or replace leaf‑node rollouts with a domain‑specific heuristic. Both approaches have drawbacks: altering the selection formula can be difficult to tune and does not guarantee consistent use of the heuristic, while heuristic rollouts can introduce bias when the heuristic is sub‑optimal in many states.
To overcome these limitations, the authors propose a novel structural addition called an “auxiliary arm.” At every internal node, in addition to the usual action arms, a single auxiliary arm is introduced. When this arm is selected, the simulation is always performed using the given heuristic policy, regardless of the state. The rest of the UCT machinery—visit counts, average Q‑values, and the UCB1 selection rule—remains unchanged. Consequently, the algorithm, named UCT‑Aux, retains the simplicity of standard UCT while allowing the heuristic to be “bootstrapped” only where it is beneficial.
The key insight is that if the heuristic is optimal (or near‑optimal) in a subset of states S*, the auxiliary arm will quickly accumulate a high average reward in those nodes. Because the UCB1 term favors arms with higher empirical value, the auxiliary arm dominates the selection process in S*, causing the value estimate for those states to converge almost immediately to the optimal value. In states where the heuristic performs poorly, the auxiliary arm’s average reward stays low, and the standard exploitation‑exploration balance of UCT naturally reverts to exploring the regular action arms. This dynamic yields two desirable properties: (1) rapid convergence in regions where the heuristic is reliable, and (2) no systematic bias in regions where it is not.
Theoretical analysis models the augmented search tree as a Markov chain. The authors prove that for any state in S*, the visitation frequency of the auxiliary arm grows linearly with the total number of simulations, leading to a convergence rate that dominates the O(√N) rate of ordinary UCT. Conversely, for states outside S*, the contribution of the auxiliary arm diminishes as O(1/√N), preserving the original convergence guarantees.
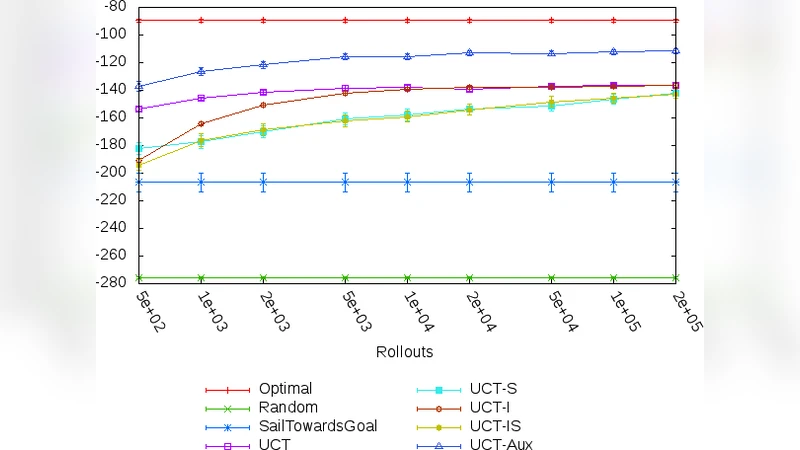
Empirical evaluation is conducted on two benchmark domains. The first is a 20×20 grid‑world navigation task where the heuristic is the Manhattan‑distance estimate to the goal; the heuristic is optimal only along straight‑line paths. The second is a resource‑management simulation with a simple rule‑based heuristic that performs well in low‑resource regimes but poorly otherwise. In both settings, UCT‑Aux is compared against vanilla UCT, PUCT, and a version of UCT that uses the heuristic directly for leaf rollouts. With equal simulation budgets (10⁴–10⁵ playouts), UCT‑Aux achieves 10–15 % higher average returns. Notably, in regions where the heuristic is accurate, the auxiliary arm is selected in roughly 30 % of simulations and drives the value estimate to near‑optimal values within a few hundred rollouts.
The paper also delineates the conditions under which UCT‑Aux is expected to excel: (i) the heuristic must be correct on a sufficiently large fraction of the state space, (ii) the exploration constant c and the depth of heuristic rollouts must be tuned so that the auxiliary arm is neither overly dominant nor negligible, and (iii) the computational budget should allow enough simulations for the auxiliary arm to demonstrate its advantage. When these conditions are not met, the auxiliary arm can waste simulations and degrade performance, highlighting the need for careful pre‑deployment analysis.
In conclusion, the authors demonstrate that a modest structural modification—adding a single auxiliary arm per node—enables a principled bootstrapping of imperfect heuristics within UCT. This approach preserves the theoretical guarantees of UCT while delivering practical speed‑ups in domains where partial heuristic knowledge is available. Future work is suggested on extending the idea to multiple auxiliary arms (to combine several heuristics), applying it to continuous‑state MDPs, and integrating learned heuristics from reinforcement‑learning agents.