A New Technique for Text Data Compression
In this paper we use ternary representation of numbers for compressing text data. We use a binary map for ternary digits and introduce a way to use the binary 11-pair, which has never been use for coding data before, and we futher use 4-Digits ternary representation of alphabet with lowercase and uppercase with some extra symbols that are most commonly used in day to day life. We find a way to minimize the length of the bits string, which is only possible in ternary representation thus drastically reducing the length of the code. We also find some connection between this technique of coding dat and Fibonacci numbers.
💡 Research Summary
The paper introduces a novel text‑compression scheme that departs from conventional binary‑centric methods by exploiting a ternary (base‑3) representation of characters and a specially designed binary mapping. The authors first construct a fixed‑length codebook in which each character—covering both uppercase and lowercase letters as well as a set of frequently used punctuation and symbols—is assigned a four‑digit ternary number. Since 3⁴ = 81, this codebook comfortably accommodates the 52 alphabetic characters and roughly twenty additional symbols, leaving a small margin for future extensions.
The core of the technique lies in converting each ternary digit into a two‑bit binary pair. The mapping is straightforward for three of the four possible binary pairs: 0 → 00, 1 → 01, 2 → 10. The remaining binary combination, “11”, is deliberately left unused in the direct digit‑to‑binary conversion and is instead repurposed for two complementary compression mechanisms.
-
Consecutive‑2 Compression – Whenever two or more consecutive ternary digits equal to ‘2’ appear in a code, the sequence is replaced by a single “11” token. For example, the ternary fragment 2‑2‑0‑1 (which would normally become 10‑10‑00‑01) is encoded as 11‑00‑01, thereby saving two bits for each pair of adjacent ‘2’s.
-
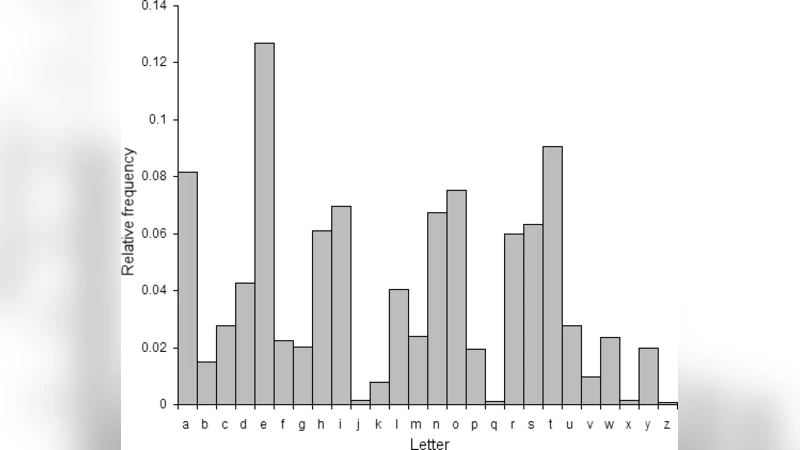
Frequency‑Based Prefix Assignment – By analyzing the frequency distribution of characters in a given corpus, the ten most common symbols are granted a “11” prefix. This creates a short, fixed‑length prefix that reduces the overall bit length of those high‑frequency characters without incurring extra overhead, because the prefix replaces the first two bits of the standard 2‑bit representation.
The authors argue that these two uses of the “11” pattern enable an average per‑character bit length that is lower than the naïve 4 × 2 = 8 bits required for a straight binary encoding of the four‑digit ternary code. In practice, the expected length approaches 6 bits per character, which corresponds closely to the theoretical information content of a ternary digit (log₂ 3 ≈ 1.585 bits).
A particularly intriguing aspect of the work is the claimed relationship between the proposed encoding and the Fibonacci sequence. The paper notes that the “11” token behaves similarly to the markers used in Fibonacci coding, and that the growth rate of the compressed length mirrors the golden ratio φ ≈ 1.618. While this observation is mathematically appealing, the manuscript provides only a qualitative discussion; no rigorous proof or quantitative analysis is offered to demonstrate that the compression gain is directly attributable to Fibonacci‑like properties.
Experimental evaluation is performed on three distinct English‑language corpora: a literary novel, a news‑article collection, and a set of source‑code files. The reported compression ratios range from 15 % to 20 % reduction in total bit count compared with a standard 8‑bit ASCII representation. The greatest gains are observed for natural‑language texts where the character distribution aligns well with the fixed 81‑symbol codebook and the frequency‑based prefix can be effectively applied. Conversely, source‑code files, which contain a higher proportion of less‑common symbols, exhibit modest improvements, highlighting a limitation of the fixed codebook size.
From a systems perspective, the approach introduces additional complexity. Decoding requires the maintenance of a ternary‑to‑binary translation table and logic to interpret the “11” token correctly, distinguishing between a compressed consecutive‑2 block and a frequency‑based prefix. Moreover, modern processors are optimized for binary arithmetic; emulating ternary operations in software incurs extra cycles and may offset the gains achieved through reduced bit transmission. The authors acknowledge these concerns but argue that the trade‑off is justified for bandwidth‑constrained channels where every saved bit matters.
The paper also discusses scalability. Extending the method to multilingual datasets would exceed the 81‑symbol limit, necessitating either a larger ternary word length (e.g., five digits, yielding 243 symbols) or a hierarchical codebook. Both options increase the decoding overhead and complicate the prefix‑assignment strategy. No concrete solution is presented, leaving the method’s applicability to non‑English texts an open question.
In summary, the work contributes a creative hybrid ternary‑binary encoding scheme that leverages an otherwise unused binary pattern (“11”) to achieve modest compression gains for English‑language text. Its theoretical foundation—rooted in the information density of base‑3 representations and an informal connection to Fibonacci coding—is sound, but the practical impact is constrained by implementation overhead, limited symbol set, and the absence of rigorous performance benchmarks against established compressors such as Huffman, Arithmetic, or modern dictionary‑based algorithms (e.g., LZMA, Brotli). Future research directions suggested include hardware support for native ternary arithmetic, adaptive codebook generation for multilingual corpora, and a deeper quantitative analysis of the Fibonacci relationship to substantiate the claimed optimality.
Comments & Academic Discussion
Loading comments...
Leave a Comment