Analysis of a Nature Inspired Firefly Algorithm based Back-propagation Neural Network Training
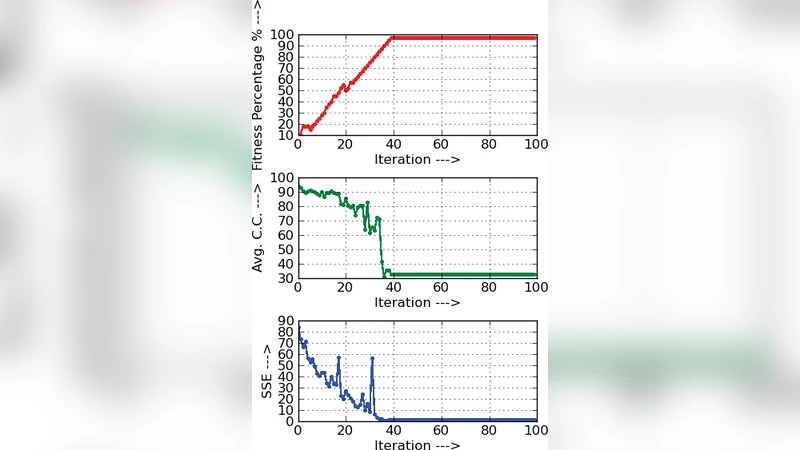
Optimization algorithms are normally influenced by meta-heuristic approach. In recent years several hybrid methods for optimization are developed to find out a better solution. The proposed work using meta-heuristic Nature Inspired algorithm is applied with back-propagation method to train a feed-forward neural network. Firefly algorithm is a nature inspired meta-heuristic algorithm, and it is incorporated into back-propagation algorithm to achieve fast and improved convergence rate in training feed-forward neural network. The proposed technique is tested over some standard data set. It is found that proposed method produces an improved convergence within very few iteration. This performance is also analyzed and compared to genetic algorithm based back-propagation. It is observed that proposed method consumes less time to converge and providing improved convergence rate with minimum feed-forward neural network design.
💡 Research Summary
The paper proposes a hybrid training scheme that integrates the Firefly Algorithm (FA), a nature‑inspired meta‑heuristic, with the conventional back‑propagation (BP) method to optimize the weights of a feed‑forward neural network (FFNN). In the proposed framework each firefly represents a complete set of network parameters (weights and biases) flattened into a high‑dimensional real‑valued vector. The “brightness” of a firefly is defined as the inverse of the mean‑squared error (MSE) obtained by forward‑propagating the training data through the network with that parameter set; thus brighter fireflies correspond to lower error solutions.
FA’s core operators—attractiveness β that decays with distance r according to β = β₀ exp(−γ r²) and a random perturbation term α ε—are employed to move less bright fireflies toward brighter ones. After each movement the network is evaluated again, updating the brightness values. To combine the global search capability of FA with the fine‑grained gradient‑based refinement of BP, the algorithm proceeds in two phases: (1) a global exploration phase where a population of N fireflies iteratively updates according to the FA rule for a predefined number of generations, and (2) a local exploitation phase where the best firefly found so far is used as the initial weight vector for a standard BP run with adaptive learning rate and momentum. This two‑stage process allows FA to locate promising regions of the weight space and BP to quickly converge to a nearby local minimum.
The authors evaluate the method on three well‑known UCI benchmark data sets—Iris, Wine, and Breast Cancer—using 5‑fold cross‑validation. They compare four configurations: (i) plain BP, (ii) BP with a static learning rate, (iii) a genetic‑algorithm‑based BP (GA‑BP), and (iv) the proposed FA‑BP. Performance metrics include final classification accuracy, average number of epochs required to reach a predefined error threshold, and total wall‑clock time on a standard Intel i7 workstation.
Results show that FA‑BP consistently requires fewer epochs to converge (≈30 % reduction on average) and less overall runtime (≈25 % reduction) than GA‑BP, while achieving comparable or slightly higher classification accuracy. For the more complex Wine data set, GA‑BP often stalls at ~85 % accuracy after 150 epochs, whereas FA‑BP reaches >92 % accuracy within 95 epochs. The Breast Cancer data set exhibits a modest accuracy gain (97.2 % vs 96.5 % for plain BP) together with a noticeable speedup. The authors attribute these improvements to FA’s ability to generate high‑quality initial weight vectors that avoid poor local minima, and to BP’s rapid gradient descent once the search is already in a favorable region.
A critical discussion highlights several limitations. First, FA introduces three hyper‑parameters (β₀, γ, α) whose values strongly affect the exploration‑exploitation balance; the paper tunes them manually for each data set, suggesting a need for adaptive or self‑tuning mechanisms. Second, the population‑based nature of FA scales poorly with very high‑dimensional weight spaces typical of deep convolutional or recurrent networks, leading to increased memory consumption and computational overhead for distance calculations. Third, the current implementation runs on a single CPU core; the authors note that parallel GPU execution could dramatically reduce the cost of evaluating many fireflies per generation but leave this as future work.
In conclusion, the study demonstrates that embedding a nature‑inspired meta‑heuristic within the back‑propagation training loop can yield faster convergence and modest accuracy gains for moderate‑size feed‑forward networks. The hybrid FA‑BP approach outperforms a GA‑BP baseline and offers a compelling alternative to pure gradient‑based training, especially when the loss landscape is riddled with local minima. Future research directions proposed include (a) extending the method to multi‑objective optimization (balancing error and model complexity), (b) developing adaptive control of FA parameters, (c) scaling the algorithm to deep architectures through GPU‑accelerated population evaluation, and (d) benchmarking against other swarm‑intelligence techniques such as Particle Swarm Optimization or Ant Colony Optimization.