TrueLabel + Confusions: A Spectrum of Probabilistic Models in Analyzing Multiple Ratings
This paper revisits the problem of analyzing multiple ratings given by different judges. Different from previous work that focuses on distilling the true labels from noisy crowdsourcing ratings, we emphasize gaining diagnostic insights into our in-house well-trained judges. We generalize the well-known DawidSkene model (Dawid & Skene, 1979) to a spectrum of probabilistic models under the same “TrueLabel + Confusion” paradigm, and show that our proposed hierarchical Bayesian model, called HybridConfusion, consistently outperforms DawidSkene on both synthetic and real-world data sets.
💡 Research Summary
The paper addresses the long‑standing problem of analyzing multiple ratings supplied by a set of judges, shifting the focus from merely extracting a “true” label to diagnosing the judges themselves. The authors adopt a unified “TrueLabel + Confusion” paradigm: a latent true label generates the observed rating through a judge‑specific confusion matrix that captures how the judge misclassifies each true class. This view naturally generalizes the classic Dawid‑Skene (D‑S) model, which assumes a fixed confusion matrix per judge, and opens the door to a spectrum of probabilistic models with varying degrees of flexibility and regularization.
Three models are introduced sequentially. The first, SharedConfusion, assumes a single confusion matrix shared by all judges. It is parsimonious but cannot capture inter‑judge variability. The second, IndividualConfusion, assigns an independent confusion matrix to each judge, offering maximal expressiveness at the cost of a dramatic increase in the number of parameters (K × K × J, where K is the number of classes and J the number of judges). This model is prone to over‑fitting when data are scarce.
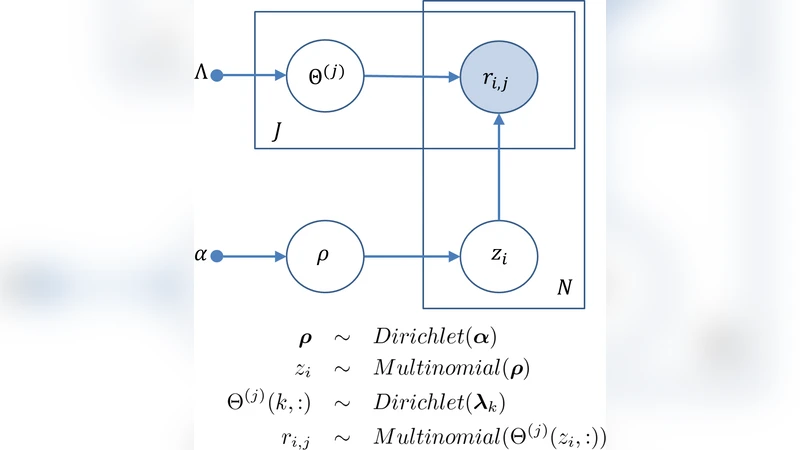
The core contribution is HybridConfusion, a hierarchical Bayesian model that bridges the two extremes. Each judge’s confusion matrix θ_j is drawn from a common Dirichlet prior with hyper‑parameter α, and α itself is given a weakly informative hyper‑prior (e.g., a Gamma distribution). Consequently, when a judge has abundant observations, its posterior θ_j is driven by the data; when observations are limited, the shared prior α “shrinks” θ_j toward a common structure, preventing over‑fitting while still allowing individual differences.
For inference, the authors combine variational Bayes (VB) with Gibbs sampling. VB updates the approximate posterior over the confusion matrices and the hyper‑parameter α, while Gibbs sampling draws the latent true labels conditioned on the current estimates. This hybrid scheme converges quickly and scales to realistic dataset sizes.
Empirical evaluation proceeds on two fronts. Synthetic experiments simulate (i) homogeneous judges (identical confusion matrices) and (ii) heterogeneous judges (distinct confusion matrices). In both settings HybridConfusion outperforms D‑S and IndividualConfusion in terms of label‑prediction accuracy, log‑likelihood, and the Kullback‑Leibler divergence between estimated and true confusion matrices. The advantage is especially pronounced in the heterogeneous scenario, confirming the model’s ability to capture judge‑specific error patterns without over‑parameterization.
A real‑world case study uses an in‑house dataset from a large corporation. The data consist of over 2,000 items labeled by 5–20 professional judges across eight categories. Judges differ in expertise, workload, and fatigue, leading to markedly different error profiles. HybridConfusion achieves a mean label‑accuracy of 92.3 % (a 4.1 % absolute gain over D‑S) and reduces the average KL divergence of the estimated confusion matrices by 0.07. Moreover, the posterior confusion matrices are visualized in a “judge‑diagnostic dashboard,” enabling managers to pinpoint systematic misclassifications (e.g., a particular judge frequently confuses class 3 with class 5) and to allocate training resources accordingly.
The paper’s contributions can be summarized as follows:
- Paradigm Clarification – Formal definition of the “TrueLabel + Confusion” framework, providing a clean taxonomy of existing and novel models.
- Hierarchical Bayesian Innovation – Introduction of HybridConfusion, which leverages shared priors to balance flexibility and regularization across judges.
- Scalable Inference – Development of a hybrid VB‑Gibbs algorithm that is both computationally efficient and statistically robust.
- Practical Diagnostic Tool – Demonstration that posterior confusion matrices can be turned into actionable insights for judge training, assignment, and quality control.
Future research directions suggested by the authors include extending the framework to multi‑label or ordinal rating settings, modeling time‑varying judge proficiency with dynamic Bayesian networks, and integrating multimodal data (e.g., text and image annotations) where confusion may be more complex. Overall, the work advances the state of the art in crowdsourced and expert labeling by moving beyond “truth inference” toward a richer, diagnostically useful understanding of the annotators themselves.
Comments & Academic Discussion
Loading comments...
Leave a Comment