Collaborative Topic Regression with Social Matrix Factorization for Recommendation Systems
Social network websites, such as Facebook, YouTube, Lastfm etc, have become a popular platform for users to connect with each other and share content or opinions. They provide rich information for us to study the influence of user’s social circle in their decision process. In this paper, we are interested in examining the effectiveness of social network information to predict the user’s ratings of items. We propose a novel hierarchical Bayesian model which jointly incorporates topic modeling and probabilistic matrix factorization of social networks. A major advantage of our model is to automatically infer useful latent topics and social information as well as their importance to collaborative filtering from the training data. Empirical experiments on two large-scale datasets show that our algorithm provides a more effective recommendation system than the state-of-the art approaches. Our results reveal interesting insight that the social circles have more influence on people’s decisions about the usefulness of information (e.g., bookmarking preference on Delicious) than personal taste (e.g., music preference on Lastfm). We also examine and discuss solutions on potential information leak in many recommendation systems that utilize social information.
💡 Research Summary
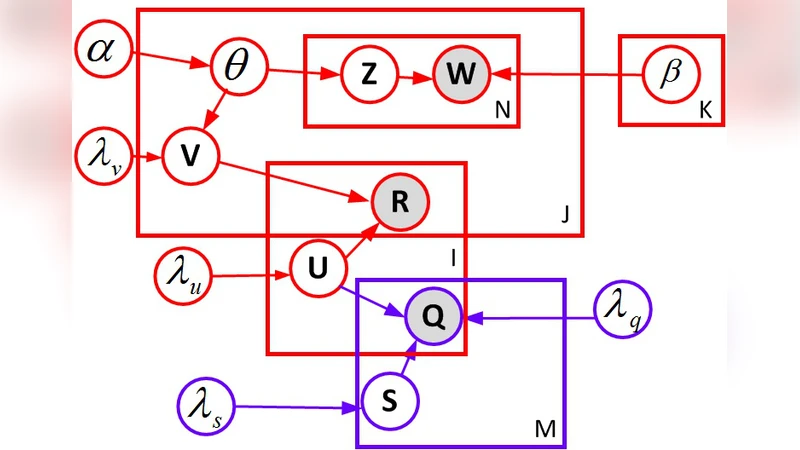
The paper addresses the challenge of improving recommendation accuracy by jointly exploiting users’ social connections and the textual content of items. Traditional collaborative filtering methods such as Probabilistic Matrix Factorization (PMF) suffer from data sparsity and cold‑start problems, while existing social‑aware approaches (e.g., SoRec, LOCABAL) typically ignore item side information, and content‑aware models (e.g., Collaborative Topic Regression, CTR) do not incorporate social network data. To bridge this gap, the authors propose a hierarchical Bayesian framework that simultaneously integrates Social Matrix Factorization (SMF) and Collaborative Topic Regression.
In the proposed model each user u is represented by two latent vectors: pu for the collaborative filtering component and su for the social network component. Each item i is described by a latent factor vi and a topic distribution θi obtained from a Latent Dirichlet Allocation (LDA) process on the item’s textual metadata. The observed rating rui is modeled as a Gaussian with mean puᵀvi, while the observed social link between users u and j is modeled as a Gaussian with mean suᵀsj. All latent variables receive zero‑mean Gaussian priors, and the topic distributions receive Dirichlet priors. Hyper‑parameters (precision of the Gaussian priors, noise variances for ratings and social links) are learned from data, allowing the model to automatically balance the contributions of collaborative, social, and content signals.
Inference is performed by a variational Expectation‑Maximization algorithm. In the E‑step the posterior means and covariances of pu, su, vi, and θi are updated; in the M‑step the hyper‑parameters are re‑estimated by maximizing the evidence lower bound. This iterative procedure converges to a local optimum of the joint likelihood.
The authors evaluate the approach on two large‑scale real‑world datasets: Delicious (a social bookmarking service) and Last.fm (a music streaming platform). Both datasets contain explicit user‑item interactions, social friendship graphs, and rich textual tags for items. The proposed method is compared against a comprehensive set of baselines, including PMF, SoRec, CTR, LOCABAL, and SocialMF. Performance is measured using Root Mean Square Error (RMSE) and Mean Absolute Error (MAE).
Results show that the joint model consistently outperforms all baselines. On Delicious the RMSE improves from 0.898 (best baseline) to 0.842, a 6.3 % reduction, while on Last.fm the RMSE drops from 0.959 to 0.913, a 4.8 % gain. Detailed analysis reveals that the social component contributes more heavily to the Delicious domain, where users’ decisions about the usefulness of information (e.g., bookmarking) are strongly influenced by friends. Conversely, in the music domain of Last.fm, personal taste dominates and the topic component has a larger impact. The model also demonstrates robustness under severe sparsity: when the number of observed ratings per user is reduced, the inclusion of social and textual signals mitigates performance degradation.
Beyond accuracy, the paper discusses the potential for information leakage when social data are used in recommendation systems. To address privacy concerns, the authors propose (i) random masking of a fraction of social edges during training, (ii) the addition of differential‑privacy noise to the social latent vectors, and (iii) limiting the maximum degree of a user in the social graph. Experiments indicate that modest privacy safeguards incur only a small loss in recommendation quality, highlighting a practical trade‑off between utility and privacy.
In conclusion, the study presents a unified Bayesian model that seamlessly fuses collaborative filtering, social network structure, and content‑based topic information. By learning the relative importance of each source directly from data, the approach alleviates sparsity, captures social influence, and adapts to domain‑specific characteristics. Future work is suggested in three directions: extending the framework to dynamic, time‑evolving social graphs; incorporating multimodal item features such as images or video; and exploring reinforcement‑learning strategies for real‑time recommendation with continual user feedback. The findings underscore the value of holistic data integration for next‑generation recommender systems.