Learning Efficient Structured Sparse Models
We present a comprehensive framework for structured sparse coding and modeling extending the recent ideas of using learnable fast regressors to approximate exact sparse codes. For this purpose, we develop a novel block-coordinate proximal splitting m…
Authors: Alex Bronstein (Tel Aviv University), Pablo Sprechmann (University of Minnesota), Guillermo Sapiro (University of Minnesota)
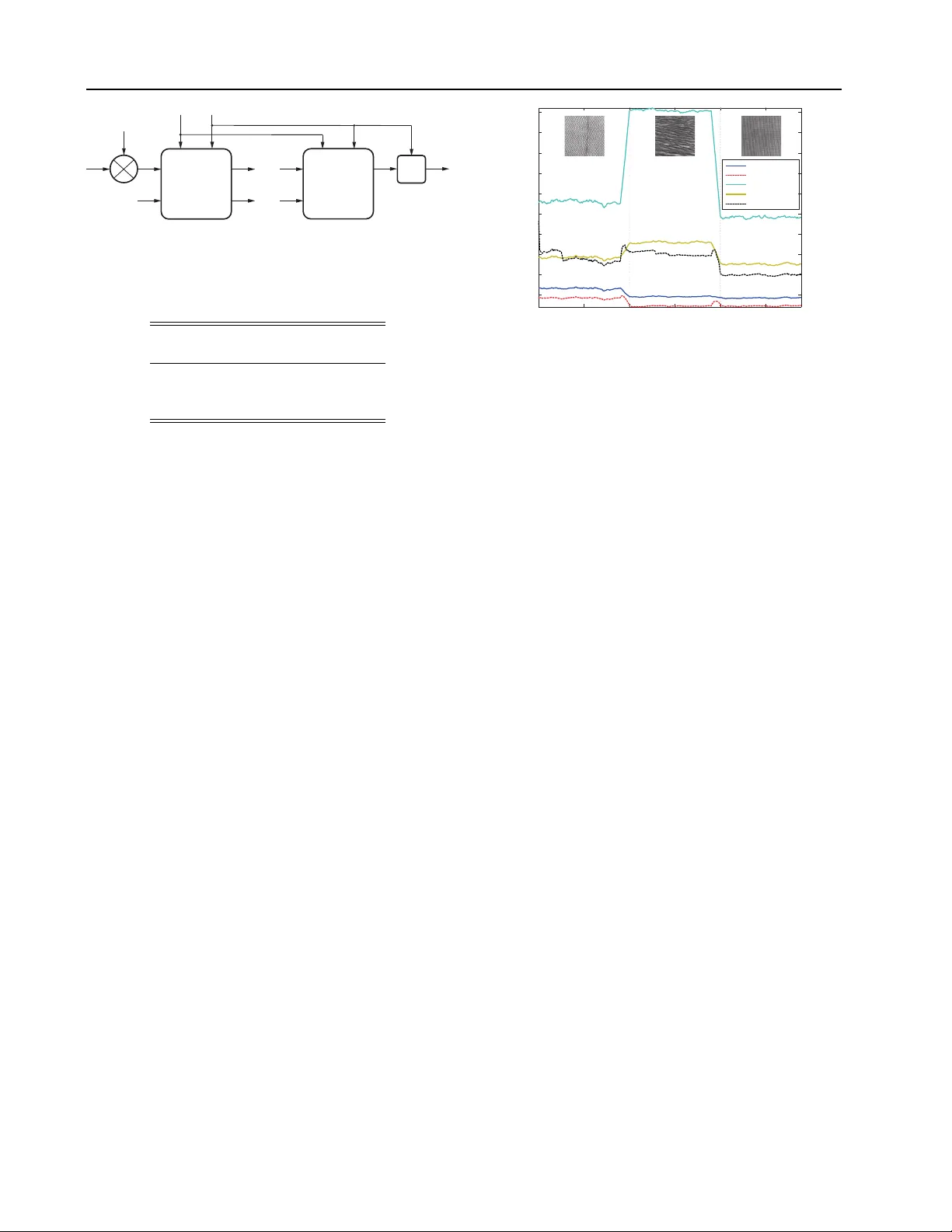
Learning Efficien t Structured Sparse Mo dels P ablo Sprec hmann sprec009@umn.edu Alex Bronstein bron@cs.technion.a c.il F acult y of Engineering, T el Aviv Univ ersity , Ramat Aviv 69978, Israel Guillermo Sapiro guille@umn.edu Univ ersity of Minnesota - Departmen t of Electrical and Computer Engineering, 200 Union Street SE, Minneap olis, USA Abstract W e presen t a comprehensiv e framework for structured sparse coding and mo deling ex- tending the recent ideas of using learnable fast regressors to approximate exact sparse co des. F or this purp ose, we prop ose an effi- cien t feed forward arc hitecture deriv ed from the iteration of the blo ck-coordinate algo- rithm. This architecture appr oximates the exact structured sparse codes with a frac- tion of the complexity of the standard op- timization methods. W e also show that by using different training ob jectiv e functions, the prop osed learnable sparse enco ders are not only restricted to b e approximan ts of the exact sparse co de for a pre-given dictionary , but can be rather used as full-featured sparse enco ders or even modelers. A simple imple- men tation shows several orders of magnitude sp eedup compared to the state-of-the-art ex- act optimization algorithms at minimal per- formance degradation, making the prop osed framew ork suitable for real time and large- scale applications. 1. Introduction Sparse c o ding is the problem of representing signals as a sparse linear combination of elementary atoms of a giv en dictionary . Sparse mo deling aims at learn- ing suc h (non-)parametric dictionaries from the data themselv es. In addition to b eing very attractive at the theoretical lev el, a large class of signals is well de- scrib ed b y this mo del, as demonstrated by numerous state-of-the-art results in diverse applications. App earing in Pr o c e e dings of the 29 th International Confer- enc e on Machine L e arning , Edin burgh, Scotland, UK, 2012. Cop yright 2012 b y the author(s)/owner(s). The main challenge of all optimization-based sparse co ding and modeling approac hes is their relatively high computational complexity . Consequen tly , a significant amoun t of effort has b een devoted to developing ef- ficien t optimization schemes ( Beck & T eb oulle , 2009 ; Li & Osher , 2009 ; Nesterov , 2007 ; Xiang et al. , 2011 ). Despite the permanent progress rep orted in the liter- ature, the state-of-the-art algorithms require tens or h undreds of iterations to conv erge, making them in- feasible for real-time or very large (mo dern size) ap- plications. Recen t works hav e prop osed to trade off precision in the sparse representation for computational speed- up ( Jarrett et al. , 2009 ; Ka vukcuoglu et al. , 2010 ), b y learning non-linear regressors capable of pro duc- ing go o d appro ximations of sparse co des in a fixed amoun t of time. The insigh tful work by ( Gregor & LeCun , 2010 ) introduced a no vel approach in which the regressors are multi-la y er artificial neural netw orks (NN) with a particular architecture inspired b y suc- cessful optimization algorithms for solving sparse cod- ing problems. These regressors are trained to minimize the MSE b etw een the predicted and exact codes o ver a given training set. Unlik e previous predictiv e ap- proac hes, the system introduced in ( Gregor & LeCun , 2010 ) has an architecture capable of pro ducing more accurate approximations of the true sparse co des, since it allows an approximate “explaining aw ay” to take place during inference (see ( Gregor & LeCun , 2010 ) for details). In this paper w e propose sev eral extensions of ( Gregor & LeCun , 2010 ), including the consideration of more general sparse co ding paradigms (hierarchical and non-o verlapping group ed), adding online adapta- tion of the underlying dictionary/model, thereb y ex- tending the applicability of this fast enco ding frame- w ork. The proposed approac h can be used with a pre- defined dictionary or learn it in an online manner on the very same data v ectors fed to it. While differently motiv ated, in the case in which the Learning efficien t structured sparse mo dels dictionary is learned, the framew ork is related to re- cen t efforts in pro ducing NN based sparse represen- tations, see ( Go odfellow et al. , 2009 ; Ranzato et al. , 2007 ) and references therein. It can b e interpreted as an online trainable sparse auto-enco der ( Go odfellow et al. , 2009 ) with a sophisticated enco der and sim- ple linear deco der. The higher complexit y of the pro- p osed arc hitecture in the enco der allows the system to pro duce accurate estimates of true structured sparse co des. In Section 2 we briefly presen t the general problem of hierarc hical structured sparse co ding and in Section 3 discuss the optimization algorithm used to inspire the arc hitecture of the enco ders. In Section 4 we presen t the new sparse enco ders and the new ob jective func- tions used for their training. Exp erimen tal results in real audio and image analysis tasks are presented in Section 5 . Finally , conclusions are dra wn in Section 6 . 2. Structured Sparse Mo dels The underlying assumption of sparse mo dels is that the input v ectors can b e reconstructed accurately as a linear com bination of some (usually learned) basis v ec- tors (factors or dictionary atoms) with a small num b er of non-zero co efficien ts. Structur e d sparse models fur- ther assume that the pattern of non-zero co efficien ts exhibits a sp ecific structure known a priori . Let D ∈ R m × p b e a dictionary with p m -dimensional atoms. W e define groups of atoms through their in- dexes, G ⊆ { 1 , . . . , p } . Then, w e define a group structure, G , as collection of groups of atoms, G = { G 1 , . . . , G |G | } . F or an input vector x ∈ R m , the cor- resp onding structured sparse co de, z ∈ R p , asso ciated to the group structure G , can b e obtained by solving the conv ex program, min z ∈ R p 1 2 k x − Dz k 2 2 + ψ ( z ) , (1) ψ ( z ) = X r ∈G λ r k z r k 2 , (2) where the vector z r ∈ R | G r | con tains the co efficien ts of z b elonging to group r , and λ r are scalar weigh ts con trolling the sparsit y level. The regularizer function ψ in ( 1 ) can b e seen as a gen- eralization of the ` 1 regularizer used in standard sparse co ding, as the latter arises from the sp ecial case of singleton groups G = {{ 1 } , { 2 } , . . . , { p }} and setting λ r = 1. As such, its effect on the groups of z is a nat- ural generalization of the one obtained with standard sparse coding: it “turns on” and “off ” atoms in groups according to the structure imp osed by G . Algorithm 1 F orward-bac kw ard splitting method. input : Data x , dictionary D , regularizer ψ . output : Sparse co de z . Define S = I − 1 α D T D , W = 1 α D T , t = 1 α . Initialize z = 0 and b = Wx . rep eat z = prox tψ ( b ) b = b + Sz un til until c onver genc e ; Sev eral imp ortan t structured sparsity settings can b e cast as particular cases of ( 1 ): sp arse c o ding , as men- tioned ab o ve, which is often referred to as Lasso ( Tib- shirani , 1996 ) or basis pursuit ( Chen et al. , 1999 ; Donoho , 2006 ); gr oup sp arse c o ding , a generalization of the standard sparse co ding to the cases in which the dictionary is sub-divided into groups that are kno wn to b e active or inactive simultaneously ( Y uan & Lin , 2006 ), in this case G is a partition of { 1 , . . . , p } ; hier ar- chic al sp arse c o ding , assuming a hierarc hical structure of the non-zero co efficien ts ( Zhao et al. , 2009 ; Jenatton et al. , 2011 ; Sprechmann et al. , 2011 ). The groups in G form a hierarch y with resp ect to the inclusion rela- tion (a tree structure), that is, if tw o groups o verlap, then one is completely included in the other one; and c ol lab or ative sp arse c o ding generalizing the concept of structured sparse co ding to collections of input vectors b y promoting given patterns of non-zero elements in the coefficient matrix ( Eldar & Rauhut , 2010 ; Sprech- mann et al. , 2011 ). 3. Optimization Algorithms State-of-the-art approaches for solving ( 1 ) rely on the family of pro ximal splitting methods (see ( Bach et al. , 2011 ) and references therein). Next, we briefly in tro- duce proximal metho ds and an algorithm for solving hierarc hical sparse co ding problems ( Tseng , 2001 ) that will b e used to construct trainable sparse encoders. 3.1. F orw ard-Backw ard Splitting The forward-bac kw ard splitting metho d is designed for solving unconstrained optimization problems in which the cost function can b e split as min z ∈ R m f 1 ( z ) + f 2 ( z ) , (3) where f 1 is conv ex and differentiable with a 1 α - Lipsc hitz con tin uous gradient, and f 2 is conv ex ex- tended real v alued and possibly non-smooth. Clearly , problem ( 1 ) falls in this category b y considering f 1 ( z ) = 1 2 k x − Dz k 2 2 and f 2 ( z ) = ψ ( z ). Learning efficien t structured sparse mo dels The forw ard-backw ard splitting metho d with fixed constan t step defines a series of iterates, z k +1 = pro x αf 2 ( z k − 1 α ∇ f 1 ( z k )) , (4) where prox f 2 ( z ) = argmin u ∈ R m || u − z || 2 2 + f 2 ( u ) denotes the proximal operator of f 2 . The pro cedure is given in Algorithm 1 . The forward-bac kward metho d b ecomes particularly in teresting when the proximal op erator of ψ can b e computed exactly and efficiently , e.g., in standard or group-structured sparse co ding. When the groups of G o verlap arbitrarily , there is no efficien t w ay of doing so directly . How ever, there exist imp ortant exceptions suc h as the hierarc hical setting with tree-structured groups which is discussed in the sequel. Accelerated v ersions of pro ximal metho ds ha ve b een largely stud- ied in the literature to improv e their con vergence rate ( Bec k & T eb oulle , 2009 ; Nesterov , 2007 ). While these v ariants are the fastest exact solvers a v ailable (b oth in theory and practice), they still require tens or h un- dreds of iterations to ac hiev e con vergence. In the fol- lo wing sections we will elab orate in the standard ver- sions of the algorithm since we are only interested in constructing an architecture for the prop osed sparse enco ders. 3.2. Proximal Op erators T o simplify the notation, w e will henceforth formu- late all the deriv ations for the case of tw o-level hier- arc hical sparse co ding, referred as HiLasso ( F riedman et al. , 2010 ; Sprechmann et al. , 2011 ). This captures the essence of hierarc hical sparse mo dels and the gen- eralization to more lay ers ( Jenatton et al. , 2011 ) or to a collaborative scheme ( Sprechmann et al. , 2011 ) is straigh tforward. The HiLasso mo del was introduced for sim ultaneously promoting sparsity at both, group and coefficient level. Giv en a partition P = { G 1 , . . . , G |P | } , the group struc- ture G can b e expressed as the union of t wo partitions: P and the set of singletons. Th us, the regularizer ψ b ecomes ψ ( z ) = p X j =1 λ j k z j k 1 + |P | X r =1 µ r k z r k 2 . (5) The proximal op erator of ψ can then b e computed in closed form. Giv en a partition of the group of indexes, P , and a vector of thresholding parameters λ ∈ R |P | , w e define the group separable operator π λ : R p → R p Algorithm 2 BCoFB algorithm. input : Data x , structured dictionary D , λ , µ . output : Structured sparse co de z . Bound Lipschitz constant α ≤ max r k D r k 2 2 Define S = I − 1 α D T D , W = 1 α D T , s = 1 α µ , and t = 1 α λ . Initialize z = 0 and b = Wx . rep eat y = π s , t ( b ) e = y − z g = arg max r k e r k 2 b = b + S g e g z g = y g un til until c onver genc e ; Output z = π s , t ( b ) for r = 1 , . . . , |P | as π λ ( z ) r = max { 0 , k z r k 2 − λ r } k z r k 2 z r (6) if k z r k 2 > 0, and 0 otherwise. Note that π λ applies a vector soft-thresholding to each group in P . The pro ximal operator of ( 5 ) can b e expressed as ( Jenatton et al. , 2011 ; Sprechmann et al. , 2011 ), π λ , µ ( z ) = π µ ( π λ ( z )) , (7) a comp osition of the proximal operators asso ciated to eac h of the partitions in G : P and the set of singletons. The Lasso problem is a particular case of HiLasso with µ = 0 and λ = λ 1 , in whic h the proximal op erator in ( 7 ) reduces to the scalar soft-thresholding op erator and Algorithm 1 corresp onds then to the p opular iterative shrink age and thresholding algorithm (IST A) ( Bec k & T eb oulle , 2009 ). 3.3. Blo c k-Co ordinate F orw ard-Backw ard Algorithm In Algorithm 1 , every iteration requires the update of all the groups of co efficien ts in the partition P , ac- cording to ( 7 ). One can choose a blo c k co ordinate strategy where only one blo c k is up dated at a time ( Tseng , 2001 ). In this pap er we will refer to this al- gorithm as Blo c k-Co ordinate F orward-Bac kw ard algo- rithm (BCoFB) (see ( Bach et al. , 2011 ) for a review on similar algorithms). The iterates of BCoFB are, p = π λ , µ ( z k ) , z k +1 = z k , z k +1 g = p g − 1 α D T g ( D g p k g − x g ) , (8) where again here 1 /α is the Lipshitz constant of the fitting term and g is the index of the group in P to Learning efficien t structured sparse mo dels b e up dated at the k -th iteration, according to some selection rule. Inspired by the co ordinate descent al- gorithm (CoD) introduced for standard sparse co ding in ( Li & Osher , 2009 ), we prop ose an heuristic v ariant of BCoFB algorithm, that up dates the group g = argmax j || z k +1 j − z k j || 2 2 . It can b e shown that this quan tity provides a low er b ound in the decrease of the cost function for each p ossible group up date. The pro cedure is summarized in Algorithm 2 . In the case of standard sparsity , Algorithm 2 with α = 1 is identical to CoD ( Li & Osher , 2009 ). This al- gorithm was used in ( Gregor & LeCun , 2010 ) to build trainable sparse enco ders. 4. F ast Structured Sparse Enco ders In order to make sparse co ding feasible in real time set- tings, it has b een recen tly proposed to learn non-linear regressors capable of pro ducing go od approximations of sparse co des in a fixed amount of time ( Jarrett et al. , 2009 ; Ka vukcuoglu et al. , 2010 ). The main idea is to construct a parametric regressor h ( x , Θ ), with some set of parameters, collectiv ely denoted as Θ , that min- imizes the loss function L ( Θ ) = 1 N X n L ( Θ , x n ) (9) on a training set { x 1 , . . . , x N } . Here, L ( Θ , x n ) = 1 2 k z ∗ n − z n k 2 2 , z ∗ n is the exact sparse co de of x n obtained b y solving the Lasso problem, and z n = h ( x n , Θ ) is its appro ximation. While this setting is very generic, the application of off-the-shelf regressors has b een later sho wn to pro duce relativ ely low-qualit y approxima- tions ( Gregor & LeCun , 2010 ). ( Gregor & LeCun , 2010 ) prop osed then tw o particular regressors implemented as a truncated form of IST A and CoD algorithms. Essentially , these regressors are m ulti-lay er artificial NN’s where eac h la yer implements a single iteration of IST A or CoD. F or example, in the CoD arc hitecture, the learned parameters of the net work are the matrices S and W , and the set of elemen t-wise thresholds t . Naturally , as an alternativ e to learning, one could sim- ply set the parameters S , W , and t as prescrib ed by the CoD algorithm (a particular case of Algorithm 2 ), terminating it after a small num b er of iterations. Ho w- ev er, it is by no means guaran teed that such a trun- cated CoD algorithm will pro duce the b est sparse co de appro ximation with the same (small) n umber of la y- ers; in practice, without the learning, such truncated appro ximations are typically useless. Still, ev en when learning the parameters, it is hop eless to exp ect the NN regressor to pro duce go o d sparse co des for any in- put data. Y et, ( Gregor & LeCun , 2010 ) show ed that the net work do es appro ximate w ell sparse co des for in- put vectors coming from the same distribution as the one used in training. Another remark able prop erty of the IST A and CoD sparse encoder architectures is that they are con tin u- ous and almost ev erywhere C 1 with resp ect to the pa- rameters and the inputs. Differentiabilit y with respect to the parameters allo ws the use of (sub)gradien t de- scen t metho ds for training, while differentiabilit y with resp ect to the inputs allows backpropagation of the gradien ts and the use of the sparse enco ders as mo d- ules in bigger globally-trained systems. The minimization of a loss function L ( Θ ) with resp ect to Θ requires the computation of the (sub)gradients d L ( Θ , x n ) /d Θ , which is achiev ed by the backpropa- gation pro cedure. Backpropagation starts with differ- en tiating L ( Θ , x n ) with resp ect to the output of the last net work lay er, and propagating the (sub)gradients do wn to the input la yer, multiplying them b y the Ja- cobian matrices of the trav ersed lay ers. 4.1. Hierarchical Sparse Enco ders W e now extend Gregor&LeCun’s idea to hierarchical (structured) sparse co de regressors. W e consider a feed-forw ard arc hitecture based on the BCoFB, where eac h lay er implements a single iteration of the BCoFB pro ximal metho d (Algorithm 2 ). The enco der archi- tecture is depicted in Figure 1 . Each la yer essentially consists of the nonlinear pro ximal op erator π s , t fol- lo wed by a group selector and a linear op eration S g corresp onding to that group. The netw ork parameters are initialized as in Algorithm 2 . In the particular case of α = 1 and s = 0 , the CoD architecture is obtained. 4.2. Alternative T raining Ob jective F unctions So far, w e hav e follow ed Gregor&LeCun in considering NN enco ders as regressors whose only role is to repro- duce as faithfully as p ossible the ideal sparse co des z ∗ n pro duced b y an iterative sparse co ding algorithm (e.g., Lasso or HiLasso). This is ac hieved by training the net works to minimize the ` 2 discrepancy betw een the outputs of the net work and the corresp onding z ∗ n . W e propose to consider the neural netw ork sparse co ders (both structured and unstructured) not as re- gressors appro ximating an iterativ e algorithm, but as full-featured sparse enco ders (ev en mo delers) in their o wn righ t. T o achiev e this paradigm shift, we aban- don the ideal sparse co des and introduce alternative Learning efficien t structured sparse mo dels training ob jectives as detailed in the sequel. A general sparse co ding problem can b e viewed as a mapping b et ween a data vector x and the corre- sp onding sparse co de z minimizing an aggregate of a fitting term and a (p ossibly , structured) regularizer, f ( x , z ) = 1 2 k x − Dz k 2 2 + ψ ( z ). Since the latter ob jec- tiv e is trusted as an indication of the co de qualit y , we can train the netw ork to minimize the ensemble av- erage of f on a training set with z = arg min f ( x , z ) replaced by z = h ( x , Θ ), obtaining the ob jective L ( Θ ) = 1 N X n f ( x n , h ( x n , Θ )) . (10) Giv en an application, one therefore has to select an ob- jectiv e with an appropriate regularizer ψ corresp ond- ing to the problem structure, and a sparse enco der arc hitecture consistent with that structure, and train the latter to minimize the ob jectiv e on a representativ e set of data vectors. W e found that selecting the sparse enco der with the structure consistent with the training ob jective and the inherent structure of the problem is crucial for the pro duction of high-qualit y sparse codes. While sparse enco ders based on NN’s are trained by minimizing a non-conv ex function on a training set, and are therefore prone to lo cal conv ergence and o ver- fitting, we can argue that in most practical problems, the dictionary D is also found by solving a non-con vex dictionary learning problem based on a representativ e data distribution. Consequently , unless the dictionary is constructed using some domain knowledge, the use of NN sparse enco ders is not conceptually different from using iterative sparse modeling algorithms. F urthermore, one can consider the dictionary as an- other optimization v ariable in the training, and min- imize L with resp ect to b oth D and the netw ork pa- rameters Θ , alternating b et ween net work training and dictionary update iterations. This essen tially extends the prop osed efficien t sparse co ding framework into full-featured sparse mo deling, as detailed next. 4.3. Online Learning In terpreting the NN’s as standalone sparse enco ders and remo ving the reference exact sparse co des mak es the training problem completely unsup ervised. Con- sequen tly , one ma y train the netw ork (and p ossibly adapt the dictionary as well) on the very same data v ectors fed to it for sparse coding. This allows us- ing the proposed framew ork in online learning applica- tions. A full online sparse mo deling scenario consists of (a) initializing the dictionary (e.g., b y a random sample of the initially observed training data vectors); (b) fixing the dictionary in the training ob jective and adapting the net w ork parameters to the newly arriving data using an online learning algorithm (w e use an on- line v ersion of sto c hastic gradien t in small batc hes as detailed in Section 5 ); and (c) fixing the sparse codes and adapting the dictionary using an online dictionary learning algorithm (e.g., ( Mairal et al. , 2009 )). Note that all the ab o v e stages are completely free of itera- tiv e sparse co ding, whic h translates in to low latency computational complexity allowing real time applica- tions. 4.4. Sup ervised and Discriminativ e Learning The prop osed sparse mo deling framework allo ws to naturally incorporate side information about training data vectors, making the learning supervised. Space limitations preven t us from elaborating on this setting; in what follo ws, w e outline several examples leaving the details to the extended v ersion of this pap er. In the group or hierarchical Lasso case, one may kno w for eac h data vector the desired active groups. Incor- p orating this information in to the training ob jective is p ossible b y using ψ as in ( 5 ) with µ r set separately for eac h training vector x n to low v alues to promote the activ ation of a knowingly activ e group r , or to high v alues to discourage the activ ation of a kno wingly in- activ e group. In other applications, data vectors can come in pairs of knowingly similar or dissimilar vectors, and one ma y wan t to minimize some natural distance betw een sparse co des of the similar vectors, while maximizing the distance on the dissimilar ones. This scenario is of particular interest in retriev al applications, where sparse data represen tations are desirable due to their amenabilit y to efficient indexing. Incorp orating suc h a similarity pr eservation term into the training ob jective is common practice in metric learning (see, e.g., ( W ein- b erger & Saul , 2009 )), but is challenging in sparse co d- ing due to the fact that when the sparse co des are pro- duced b y an iterativ e algorithm, one faces the problem of minimizing a training ob jectiv e L depending on the minimizers of another ob jective f . When using the NN sparse mo delers instead, the training is handled using standard metho ds. Finally , in many applications the data do not hav e Euclidean structure and sup ervised learning can b e used to construct an optimal discriminative metric. This can b e achiev ed, for example, by replacing the Euclidean fitting term with the Mahalanobis counter- part, k x − Dx k 2 Q T Q = k Q ( x − Dx ) k 2 2 , where Q is a discriminativ e pro jection matrix. In such scenarios, it is desirable to com bine sparse mo deling with metric learning. This problem has not been considered b efore Learning efficien t structured sparse mo dels W x S s , t b in z in 0 b out z out b in z in b out z π s , t y = π s , t ( b in ) e = y − z in g = arg max k e g k 2 b out = b in + S g e g z out = z in ( z out ) g = y g y = π s , t ( b in ) e = y − z in g = arg max k e g k 2 b out = b in + S g e g · · · · · · Figure 1. BCoFB structured sparse enco der architecture with tw o lev els of hierarch y (a “HiLasso” netw ork). T able 1. Misclassification rates on MNIST digits. Co de Dictionary size 100 289 NN G-L 3.76% 5.98% NN Lasso 2.65% 2.51% Exact Lasso 1.99% 1.47% as it is impractical when the sparse co des are obtained b y minimization of f . It do es b ecome practical, ho w- ev er, when NN encoders are used instead. 5. Exp erimen tal Results All NN’s w ere implemen ted in Matlab with built-in GPU acceleration and executed on state-of-the-art In- tel Xeon E5620 CPU and NVIDIA T esla C2070 GPU. Ev en with this by no means optimized co de, the prop- agation of 10 5 100-dimensional vector through a 10- la yer structured net work with the prop osed BCoFB arc hitecture tak es only 3 . 6 seconds, whic h is equiv alent to 3 . 6 µsec sp en t p er v ector p er lay er. This is sev eral orders of magnitude faster than the exceptionally opti- mized m ultithreaded SP AMS HiLasso code ( Jenatton et al. , 2011 ) executed on the CPU. Such b enefits of parallelization are p ossible due to the fixed datapath and complexity of the NN enco der compared to the iterativ e solver. In all exp erimen ts, training w as performed using gra- dien t descen t safeguarded b y Armijo rule. W e refer as NN G-L to the NN sparse encoders obtained by mini- mizing Gregor&LeCun’s ob jectiv e function, this is, the ` 2 error with the output of the exact enco der. It will b e explicitly stated when NN sparse enco ders are trained using a sp ecific ob jective function (e.g., NN L asso ). 5.1. Classification In this exp erimen t, we ev aluate the p erformance of unstructured NN sparse enco ders in the MNIST digit classification task. The MNIST images were resampled to 17 × 17 (289-dimensional) patches. A set of ten dictionaries was trained for eac h class. Classification w as p erformed by encoding a test vector in eac h of the 0.5 1 1.5 2 2.5 x 10 4 0.11 0.12 0.13 0.14 0.15 0.16 0.17 0.18 0.19 0.2 Exact oine Exact online NN G-L oine NN Lasso oine NN Lasso online Lasso objective Sample Figure 2. P erformance of different sparse enco ders mea- sured using the Lasso ob jectiv e as the function of sample n umber in the online learning experiment. Shown are the three groups of patc hes corresp onding to differen t texture images from the Bro datz dataset. dictionaries and assigning the lab el corresp onding to the smallest v alue of the full Lasso ob jectiv e. The following sparse co ders were compared: exact sparse co des ( Exact L asso ), unstructured NN G-L , and unstructured NN L asso (a CoD net work trained using the Lasso ob jectiv e). T en net works were trained, one p er each class; all contained T = 5 CoD lay ers. λ = 0 . 1 w as used in the Lasso ob jective. Dictionaries with 100 (under-complete) and 289 (complete) atoms were used. F urther increase in the dictionary size did not exhibit significan t p erformance improv emen t. T able 1 summarizes the misclassification rates of eac h of the sparse enco ders. P erformance of the NN G- L sparse enco der decreases with the increase of the dictionary size, while the discrepancy with the exact co des drops. On the other hand, b etter p erformance in terms of the Lasso ob jectiv e consisten tly correlates with better classification rates, whic h mak es NN L asso a more fa vorable choice. Dictionary adaptation in the training of the NN L asso enco der brings only a small impro vemen t in p erformance, diminishing with the dictionary size. W e attribute this to the relativ e lo w complexity of the data. 5.2. Online Learning In this exp erimen t, w e ev aluate the online learning ca- pabilities of unstructured NN sparse enco ders. As the input data we used 30 × 10 4 randomly lo cated 8 × 8 patc hes from three images from the Bro datz texture dataset ( Randen & Husoy , 1999 ). The patches w ere or- dered in three consecutiv e blo c ks of 10 4 patc hes from eac h image. Dictionary size was fixed to 64 atoms. λ = 1 w as used in the Lasso ob jectiv e. Online learning w as performed in ov erlapping windo ws of 1 , 000 vectors with a step of 100 v ectors. W e com- Learning efficien t structured sparse mo dels T able 2. Misclassification rates on the audio dataset. Co de Error rate NN G-L unstructured 6.08% NN G-L structured 3.53% NN discriminative structured 3.44% Exact 2.35% pared standard online dictionary learning ( Exact L asso online ) with unstructured NN L asso with dictionary adaptation in a given windo w ( NN L asso online ), ini- tialized b y the netw ork parameters from the previous windo ws. In the latter case, the dictionary was initial- ized by a random subset of 64 out of the first 1 , 000 data vectors (therefore, no iterative sparse coding). As the reference, we also compared the following three offline algorithms trained on a distinct set of 6 , 000 patc hes extracted from the same images: standard dic- tionary learning ( Exact L asso offline ); unstructured NN G-L ( NN G-L offline ), and unstructured NN L asso ( NN L asso offline ). All NN’s used T = 4 CoD lay ers. P erformance measured in terms of the Lasso ob jective is rep orted in Figure 2 . Exact offline sparse enco der ac hieved the b est results among all offline enco ders. It is, how ever, outp erformed by the exact online enco der due to its ability to adapt the dictionary to a sp ecific class of data. The performance of the NN L asso online enco der is sligh tly inferior to the Exact L asso offline ; the online version p erforms b etter after the net work parameters and the dictionary adapt to the current class of data. Finally , the NN G-L offline enco der has the low est, significan tly inferior performance. This experiment sho ws that, while the drop in p erfor- mance compared to the exact enco der is relatively low, the computational complexit y of the NN L asso online enco der is tremendously lo wer and fixed. 5.3. Structured Co ding W e first ev aluate the p erformance of the structured sparse enco ders in a sp eak er identification task repro- duced from ( Sprec hmann et al. , 2011 ). In this appli- cation the authors use HiLasso to automatically de- tect the presen t sp eak ers in a given mixed signal. W e rep eat this exp erimen ts using the prop osed efficien t structured sparse enco ders instead. The dataset consists of recordings of fiv e differen t ra- dio sp eak ers, t wo females and three males. 25% of the samples was used for training, and the rest for testing. Within the testing data, tw o sets of w av eforms were created: one containing isolated speakers, and another con taining all p ossible combinations of mixtures of tw o sp eak ers. Signals are decomp osed in to a set of ov erlap- ping lo cal time frames of 512 samples with 75% o ver- lap, such that the prop erties of the signal remain stable within each frame. An 80-dimensional feature vector is obtained for each audio frame as its short-time pow er sp ectrum env elop e (refer to ( Sprechmann et al. , 2011 ) for details). Fiv e undercomplete dictionaries with 50 atoms w ere trained on the single sp eak er set minimiz- ing the Lasso ob jective with λ = 0 . 2 (one dictionary p er sp eaker), and then com bined into a single struc- tured dictionary containing 250 atoms. Increasing the dictionary size exhibited negligible p erformance b ene- fits. Sp eak er iden tification w as p erformed b y first en- co ding a test v ector in the structured dictionary and measuring the ` 2 energy of each of the fiv e groups. En- ergies were sum-p o oled ov er 500 time samples selecting the lab els of the highest tw o. The following structured sparse enco ders w ere com- pared: exact HiLasso co des with µ = 0 . 05 ( Exact ), un- structured NN G-L trained on the exact HiLasso codes ( NN G-L unstructur e d ), structured NN G-L trained on the same codes ( NN G-L structur e d ), and a structured net work with a discriminativ e cost function with regu- larization term in whic h the weigh ts µ r w ere set inde- p enden tly for each data vector to − 1 or 1 to promote or discourage the activ ation of groups corresponding to kno wingly activ e or silen t sp eakers resp ectiv ely , ( NN discriminative structur e d ). All NN’s used the same single structured dictionary and con tained T = 2 la y- ers with the BCoFB architecture. T able 2 summarizes the obtained misclassification rates. It is remark able that using a structured archi- tecture instead of its unstructured counterpart with the same num b er of lay ers and the same dictionary in- creases performance b y nearly a factor of t wo. The use of the discriminative ob jective further impro v es p erfor- mance. Surprisingly , using NN’s with only t wo lay ers cedes just ab out 1% of correct classification rate. The structured architecture show ed a crucial roll in pro ducing accurate structured sparse co des. W e now sho w that this observ ation is also v alid in a more gen- eral setting. W e rep eated the same experiment as b e- fore but with randomly generated synthetic data that truly has a structure sparse representation under a giv en dictionary (unkno wn for the NN’s). Results are summarized in Figure 3 . 6. Conclusion Marrying ideas from con vex optimization with multi- la yer neural netw orks, w e ha ve developed in this w ork a comprehensive framework for mo dern sparse mo d- Learning efficien t structured sparse mo dels Figure 3. P erformance ( ` 2 error) of structured and unstruc- tured NN on structured sparse synthetic data. eling for real time and large scale applications. The framew ork includes differen t ob jective functions, from reconstruction to classification, allo ws different sparse co ding structures from hierarc hical to group similarit y , and addresses online learning scenarios. A simple im- plemen tation already ac hieves sev eral order of magni- tude sp eedups when compared to the state-of-the-art, at minimal cost in p erformance, opening the door for practical algorithms following the demonstrated suc- cess of sparse mo deling in v arious applications. An extension of the prop osed approach to other structured sparse mo deling problems such as ro- bust PCA and non-negativ e matrix factorization is av ailable at http://www.eng.tau.ac.il/ ~ bron/ publications_conference.html and will be pub- lished elsewhere due to lack of space. Ac kno wledgement This researc h was supp orted in part by ONR, NGA, AR O, NSF, NSSEFF, and BSF. References Bac h, F., Jenatton, R., Mairal, J., and Ob ozinski, G. Con- v ex optimization with sparsit y-inducing norms. In Op- timization for Machine L e arning . MIT Press, 2011. Bec k, A. and T eb oulle, M. A fast iterative shrink age- thresholding algorithm for linear inv erse problems. SIAM J. Img. Sci. , 2:183–202, March 2009. Chen, S., Donoho, D., and Saunders, M. Atomic decompo- sition by basis pursuit. SIAM J. Scientific Computing , 20(1):33–61, 1999. Donoho, D. Compressed sensing. IEEE T r ans. on Inf. The ory , 52(4):1289–1306, Apr. 2006. Eldar, Y. C. and Rauhut, H. Average case analysis of mul- tic hannel sparse recov ery using conv ex relaxation. IEEE T r ans. on Inf. The ory , 56(1):505–519, 2010. F riedman, J., Hastie, T., and Tibshirani, R. A note on the group lasso and a sparse group lasso. Preprint, 2010. Go odfellow, I., Le, Q., Saxe, A., Lee, H., and Ng, A. Y. Measuring inv ariances in deep netw orks. In In NIPS , pp. 646–654. 2009. Gregor, K. and LeCun, Y. Learning fast approximations of sparse co ding. In ICML , pp. 399–406, 2010. Jarrett, K., Ka vukcuoglu, K., Ranzato, M.A., and LeCun, Y. What is the b est m ulti-stage architecture for ob ject recognition? In CVPR , pp. 2146–2153, 2009. Jenatton, R., Mairal, J., Ob ozinski, G., and Bach, F. Pro x- imal metho ds for hierarchical sparse co ding. JMLR , 12: 2297–2334, 2011. Ka vukcuoglu, K., Ranzato, M.A., and LeCun, Y. F ast inference in sparse coding algorithms with applications to ob ject recognition. , 2010. Li, Y. and Osher, S. Co ordinate descent optimization for ` 1 minimization with application to compressed sensing; a greedy algorithm. Inverse Problems and Imaging , 3: 487–503, 2009. Mairal, J., Bach, F., Ponce, J., and Sapiro, G. Online dictionary learning for sparse coding. In ICML , pp. 689– 696, 2009. Nestero v, Y. Gradient methods for minimizing comp os- ite ob jective function. In CORE . Catholic Universit y of Louv ain, Louv ain-la-Neuve, Belgium, 2007. Randen, T. and Huso y , J. H. Filtering for texture classifi- cation: a comparativ e study . IEEE T r ans. Pattern Anal. Mach. Intel l. , 21(4):291–310, 1999. Ranzato, M., Huang, F. J., Boureau, Y-L., and LeCun, Y. Unsupervised learning of in v ariant feature hierarc hies with applications to ob ject recognition. In CVPR , 2007. Sprec hmann, P ., Ram ´ ırez, I., Sapiro, G., and Eldar, Y. C. C-hilasso: A collaborative hierarchical sparse modeling framew ork. IEEE T r ans. Signal Pr o c ess. , 59(9):4183– 4198, 2011. Tibshirani, R. Regression shrink age and selection via the LASSO. J. R oyal Stat. So ciety: Series B , 58(1):267–288, 1996. Tseng, P . Con vergence of a blo c k co ordinate descent metho d for nondifferen tiable minimization. J. Optim. The ory Appl. , 109(3):475–494, June 2001. W ein b erger, K.Q. and Saul, L.K. Distance metric learning for large margin nearest neighbor classification. JMLR , 10:207–244, 2009. Xiang, Z. J., Xu, H., and Ramadge, P . J. Learning sparse represen tations of high dimensional data on large scale dictionaries. In NIPS , 24:900–908, 2011. Y uan, M. and Lin, Y. Mo del selection and estimation in regression with group ed v ariables. J. R oyal Stat. So ciety, Series B , 68:49–67, 2006. Zhao, P ., Ro c ha, G., and Y u, B. The composite absolute p enalties family for group ed and hierarchical v ariable selection. Annals of Statistics , 37(6A):3468, 2009.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment