Near-Optimal BRL using Optimistic Local Transitions
Model-based Bayesian Reinforcement Learning (BRL) allows a found formalization of the problem of acting optimally while facing an unknown environment, i.e., avoiding the exploration-exploitation dilemma. However, algorithms explicitly addressing BRL suffer from such a combinatorial explosion that a large body of work relies on heuristic algorithms. This paper introduces BOLT, a simple and (almost) deterministic heuristic algorithm for BRL which is optimistic about the transition function. We analyze BOLT’s sample complexity, and show that under certain parameters, the algorithm is near-optimal in the Bayesian sense with high probability. Then, experimental results highlight the key differences of this method compared to previous work.
💡 Research Summary
The paper tackles a central challenge in Bayesian Reinforcement Learning (BRL): how to act near‑optimally in an unknown environment without succumbing to the exploration‑exploitation dilemma. Traditional BRL methods maintain a posterior distribution over transition and reward functions and compute the Bayes‑optimal policy directly. However, exact Bayes‑optimal planning is intractable because the belief space grows combinatorially with the number of states and actions. Consequently, most practical work relies on heuristic approaches that add exploration bonuses (e.g., BEB, VBRL, MBIE‑MDP) but lack strong theoretical guarantees.
The authors introduce BOLT (Bayesian Optimistic Local Transitions), a simple yet powerful heuristic that injects optimism directly into the transition model. For each state‑action pair ((s,a)), the algorithm keeps a Beta posterior over the unknown transition probabilities to each successor state (s’). Instead of sampling from this posterior, BOLT constructs an “optimistic” transition matrix (\tilde{P}(\cdot|s,a)) by taking an upper confidence bound (UCB) of the Beta distribution. The degree of optimism is controlled by a scalar parameter (\lambda); setting (\lambda = \Theta\bigl(\frac{1}{1-\gamma}\bigr)) yields a balance that encourages exploration of poorly‑sampled transitions while preventing overly aggressive behavior.
With the optimistic transition model in hand, BOLT runs a standard planning routine (value iteration or policy iteration) to compute a policy (\pi). The policy is thus “Bayes‑optimistic”: it assumes the best plausible dynamics consistent with the current data, which naturally drives the agent toward under‑explored regions. After executing (\pi) in the real environment, the observed transition counts update the Beta posteriors, and the process repeats. The algorithm is almost deterministic, requiring only the belief update and a planning step at each iteration.
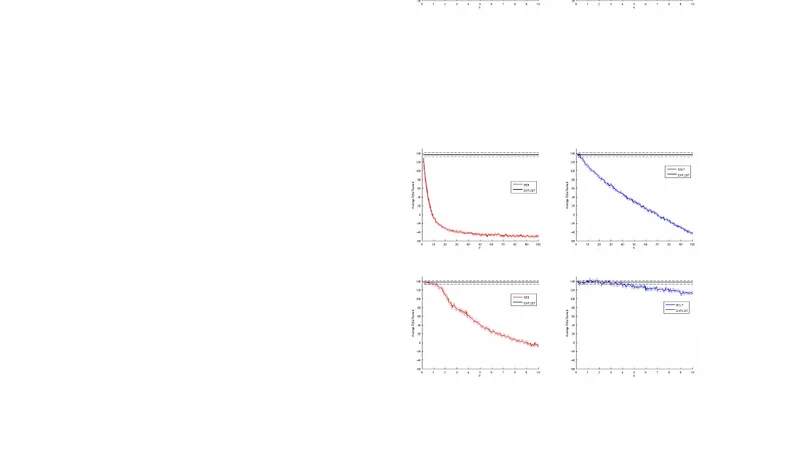
The theoretical contribution is a rigorous sample‑complexity analysis. The authors define a Bayesian (\epsilon)-optimal policy as one whose expected value under the posterior is within (\epsilon) of the Bayes‑optimal value. They prove that, with probability at least (1-\delta), BOLT attains an (\epsilon)-optimal policy after a number of samples bounded by
\