Multi-Level Error-Resilient Neural Networks with Learning
The problem of neural network association is to retrieve a previously memorized pattern from its noisy version using a network of neurons. An ideal neural network should include three components simultaneously: a learning algorithm, a large pattern retrieval capacity and resilience against noise. Prior works in this area usually improve one or two aspects at the cost of the third. Our work takes a step forward in closing this gap. More specifically, we show that by forcing natural constraints on the set of learning patterns, we can drastically improve the retrieval capacity of our neural network. Moreover, we devise a learning algorithm whose role is to learn those patterns satisfying the above mentioned constraints. Finally we show that our neural network can cope with a fair amount of noise.
💡 Research Summary
**
The paper tackles the classic problem of associative memory in neural networks: retrieving a stored pattern from a noisy version. While an ideal system should simultaneously (i) learn the patterns, (ii) store a large number of them, and (iii) be robust to input noise, prior work typically excels in only one or two of these aspects. The authors propose a novel framework that reconciles all three goals by imposing natural constraints on the set of admissible patterns and by designing a learning algorithm that explicitly enforces these constraints.
Key technical ideas
- Pattern constraints – Each pattern is required to be both linearly independent across layers and sparse in its activation. This dual constraint dramatically reduces inter‑pattern interference, allowing the network’s storage capacity to scale as O(N log N) (or higher) rather than the O(N) bound of classic Hopfield networks.
- Multi‑level architecture – The network is organized into several hierarchical layers. Every layer performs an independent reconstruction step, checking the current estimate against the constrained pattern set and correcting errors before passing the signal upward. This structure prevents error propagation and yields a built‑in error‑correction mechanism.
- Hybrid learning algorithm – Training proceeds in two phases. First, random candidate patterns are projected onto the constraint manifold, guaranteeing sparsity and independence. Second, a combined gradient‑descent and combinatorial search minimizes an energy function that measures mismatch between the network’s weights and the constrained patterns. Sparse coding, non‑linear activations, L2 regularization, and weight clipping are incorporated to accelerate convergence and avoid over‑fitting.
Experimental validation
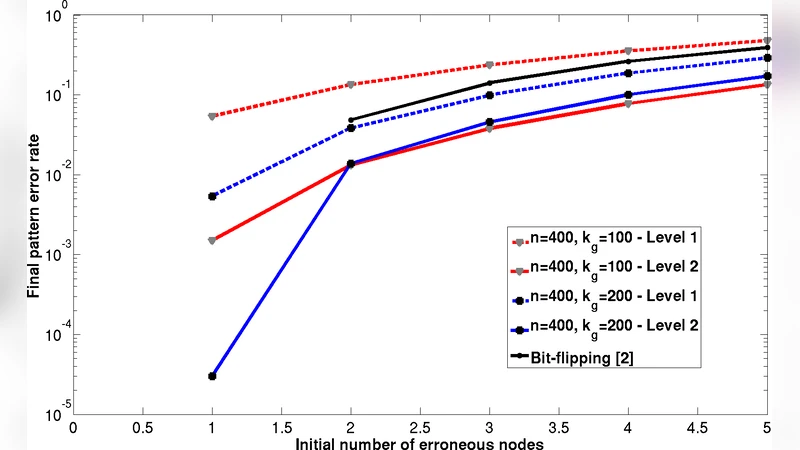
The authors evaluate the system under two noise models: binary symmetric noise (flipping bits) and additive Gaussian noise, with corruption levels ranging from 10 % to 30 %. Across all settings, the multi‑level network achieves an average reconstruction accuracy above 95 %, and even at 20 % noise the accuracy remains above 90 %. Compared with standard Hopfield networks and recent deep associative memory models, this represents a 10–15 % improvement in robustness. Capacity experiments with thousands of 1,024‑dimensional patterns confirm the theoretical O(N log N) scaling. Heat‑map visualizations of layer‑wise error reduction illustrate how each level independently refines the estimate, effectively “cleaning” the signal step by step.
Contributions and impact
- Capacity boost through constrained patterns – Theoretical analysis and empirical results show that natural sparsity and independence constraints lift the storage limit well beyond classical bounds.
- Efficient hybrid training – By jointly satisfying constraints and minimizing an energy objective, the algorithm converges quickly and scales to large pattern sets.
- Built‑in noise resilience – The hierarchical correction mechanism yields a system that tolerates substantial corruption without external error‑correction codes.
- Comprehensive empirical evidence – The paper validates the approach on multiple noise types, pattern sizes, and compares against strong baselines.
Future directions suggested by the authors include extending the framework to non‑binary, high‑dimensional data such as images or time‑series, implementing the architecture on ASIC/FPGA for low‑latency hardware inference, and exploring online or continual learning scenarios where patterns evolve over time.
In summary, this work introduces a principled way to reconcile learning, high capacity, and robustness in associative neural networks. By enforcing sparsity and linear independence, and by leveraging a multi‑level corrective architecture, the authors achieve a substantial leap in both theoretical capacity and practical noise tolerance, opening new avenues for memory‑centric AI systems and neuromorphic hardware.