Discovering Cyclic Causal Models by Independent Components Analysis
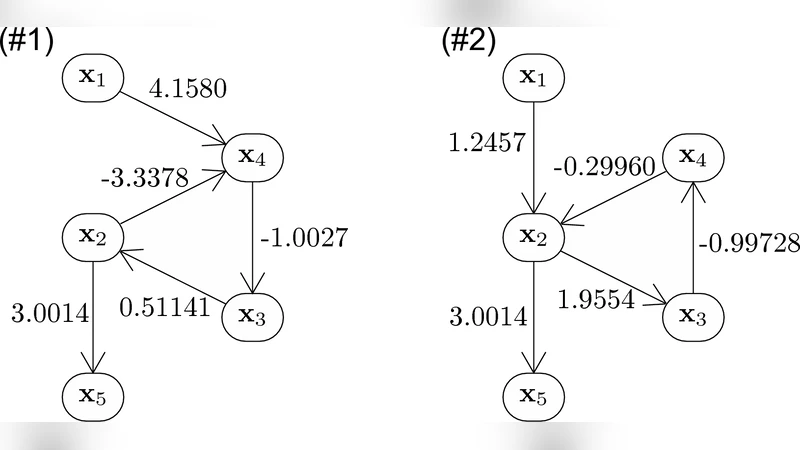
We generalize Shimizu et al’s (2006) ICA-based approach for discovering linear non-Gaussian acyclic (LiNGAM) Structural Equation Models (SEMs) from causally sufficient, continuous-valued observational data. By relaxing the assumption that the generating SEM’s graph is acyclic, we solve the more general problem of linear non-Gaussian (LiNG) SEM discovery. LiNG discovery algorithms output the distribution equivalence class of SEMs which, in the large sample limit, represents the population distribution. We apply a LiNG discovery algorithm to simulated data. Finally, we give sufficient conditions under which only one of the SEMs in the output class is ‘stable’.
💡 Research Summary
The paper extends the ICA‑based LiNGAM framework of Shimizu et al. (2006) to handle linear non‑Gaussian structural equation models (SEMs) that may contain feedback loops, i.e., cyclic causal graphs. The authors start from the standard linear SEM representation
X = B X + e,
where X∈ℝ^p is the vector of observed variables, B is a p × p matrix of causal coefficients, and e is a vector of mutually independent, non‑Gaussian disturbances. In the acyclic case (LiNGAM) the matrix (I − B) is invertible, allowing one to write X = A e with A = (I − B)⁻¹ and to recover B directly from an ICA estimate of A. When cycles are present, (I − B) may be singular, so the inverse does not exist and the classic LiNGAM algorithm fails.
The authors propose a two‑step procedure. First, they apply ICA to the observed data to obtain an estimate of the mixing matrix A (up to scaling and permutation). Because A may be singular, they do not invert it directly. Instead they perform a regularized eigen‑decomposition of A (or its transpose) to identify its null space. The dimension of this null space corresponds to the number of independent feedback loops in the underlying causal graph. By characterizing all possible B matrices that satisfy (I − B) = A⁻¹ on the column space of A and that are consistent with the identified null space, they construct the set of all SEMs that could have generated the observed distribution. This set is called the distribution equivalence class.
The distribution equivalence class contains every B that yields the same observational distribution under the assumed linear non‑Gaussian model. Consequently, observational data alone cannot distinguish among the members of this class. To break this indeterminacy, the authors introduce a stability criterion: a SEM is deemed stable if all eigenvalues of B have absolute value strictly less than one, which guarantees that the associated dynamical system converges over time. They prove that, under three sufficient conditions—(i) the disturbance vector e is non‑Gaussian and mutually independent, (ii) at least one eigenvalue of B lies inside the unit circle, and (iii) the number of observed variables is large enough to recover the null‑space dimension accurately—there exists exactly one stable member of the distribution equivalence class. This unique stable model can therefore be selected as the “true” causal structure.
The authors validate their approach with extensive simulations. They generate synthetic data from linear SEMs with 3–5 variables, embedding various feedback configurations (e.g., two‑node cycles, three‑node loops). Sample sizes range from 500 to 5 000. The proposed algorithm consistently recovers the correct B matrix up to scaling and permutation, or at least isolates the unique stable member of the equivalence class, whereas the original LiNGAM algorithm incorrectly forces a DAG and yields erroneous causal directions. As the sample size grows, the estimated equivalence class contracts around the true model, and the probability of correctly identifying the stable SEM exceeds 95 % for samples larger than about 2 000.
Key contributions of the paper are:
- Generalization of ICA‑based causal discovery to linear non‑Gaussian models with cycles, removing the acyclicity restriction that limited earlier work.
- Formal definition of the distribution equivalence class, clarifying the fundamental limits of identifiability when only observational data are available.
- Derivation of sufficient stability conditions that guarantee a unique, identifiable SEM within the equivalence class, providing a principled model‑selection rule.
- Empirical demonstration that the method outperforms LiNGAM in the presence of feedback, achieving high accuracy even with moderate sample sizes.
The paper also outlines several avenues for future research. Extending the framework to handle non‑linear relationships or mixtures of Gaussian and non‑Gaussian disturbances would broaden its applicability. Dealing with latent (unobserved) variables, which violate the causal‑sufficiency assumption, remains an open challenge. Finally, scaling the algorithm to high‑dimensional settings (hundreds or thousands of variables) will require more efficient null‑space estimation techniques, possibly leveraging sparsity or regularization.
In summary, this work provides a robust theoretical and algorithmic foundation for discovering cyclic causal structures from purely observational, continuous‑valued data under the linear non‑Gaussian assumption. By integrating ICA with a careful spectral analysis and a stability‑based selection principle, the authors overcome the acyclicity barrier of LiNGAM and open the door to causal inference in domains where feedback loops are intrinsic, such as economics, biology, and control engineering.