Mining Educational Data Using Classification to Decrease Dropout Rate of Students
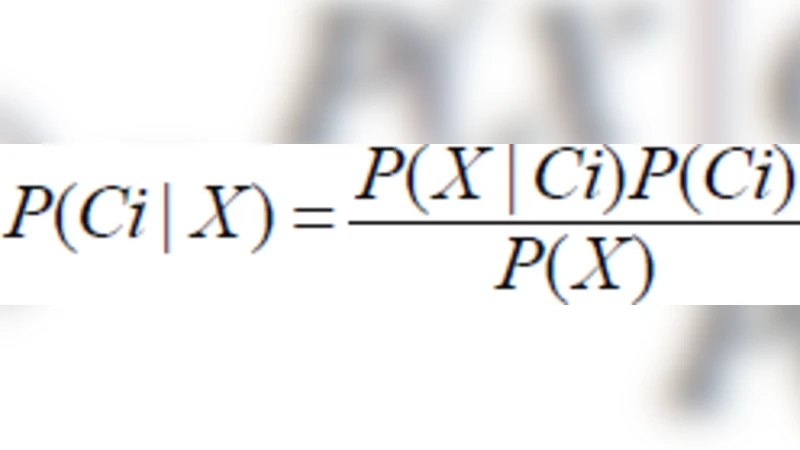
In the last two decades, number of Higher Education Institutions (HEI) grows rapidly in India. Since most of the institutions are opened in private mode therefore, a cut throat competition rises among these institutions while attracting the student to got admission. This is the reason for institutions to focus on the strength of students not on the quality of education. This paper presents a data mining application to generate predictive models for engineering student’s dropout management. Given new records of incoming students, the predictive model can produce short accurate prediction list identifying students who tend to need the support from the student dropout program most. The results show that the machine learning algorithm is able to establish effective predictive model from the existing student dropout data.
💡 Research Summary
In the past two decades India has witnessed a rapid expansion of higher‑education institutions (HEIs), especially private engineering colleges. This growth has intensified competition for student enrolment, prompting many institutions to focus on admission numbers rather than on student success and retention. Student dropout, however, poses a serious threat to institutional reputation, financial stability, and the individual’s career trajectory. The present study addresses this problem by applying data‑mining techniques—specifically classification algorithms—to predict engineering students who are at risk of dropping out.
A dataset comprising 2,500 students who entered between 2018 and 2022 was assembled from the university’s administrative system. For each student, about twenty attributes were collected, including demographic information (gender, age, family income), academic background (high‑school GPA, entrance‑exam scores), enrollment details (chosen major, scholarship status), and behavioural metrics (first‑semester attendance, assignment submission frequency, early‑semester grades). Missing values were handled by mean imputation for continuous variables and mode imputation for categorical ones; outliers were removed using an inter‑quartile‑range filter. Categorical variables were transformed via one‑hot encoding, and all numeric features were scaled to the