Softening Fuzzy Knowledge Representation Tool with the Learning of New Words in Natural Language
The approach described here allows using membership function to represent imprecise and uncertain knowledge by learning in Fuzzy Semantic Networks. This representation has a great practical interest due to the possibility to realize on the one hand, the construction of this membership function from a simple value expressing the degree of interpretation of an Object or a Goal as compared to an other and on the other hand, the adjustment of the membership function during the apprenticeship. We show, how to use these membership functions to represent the interpretation of an Object (respectively of a Goal) user as compared to an system Object (respectively to a Goal). We also show the possibility to make decision for each representation of an user Object compared to a system Object. This decision is taken by determining decision coefficient calculates according to the nucleus of the membership function of the user Object.
💡 Research Summary
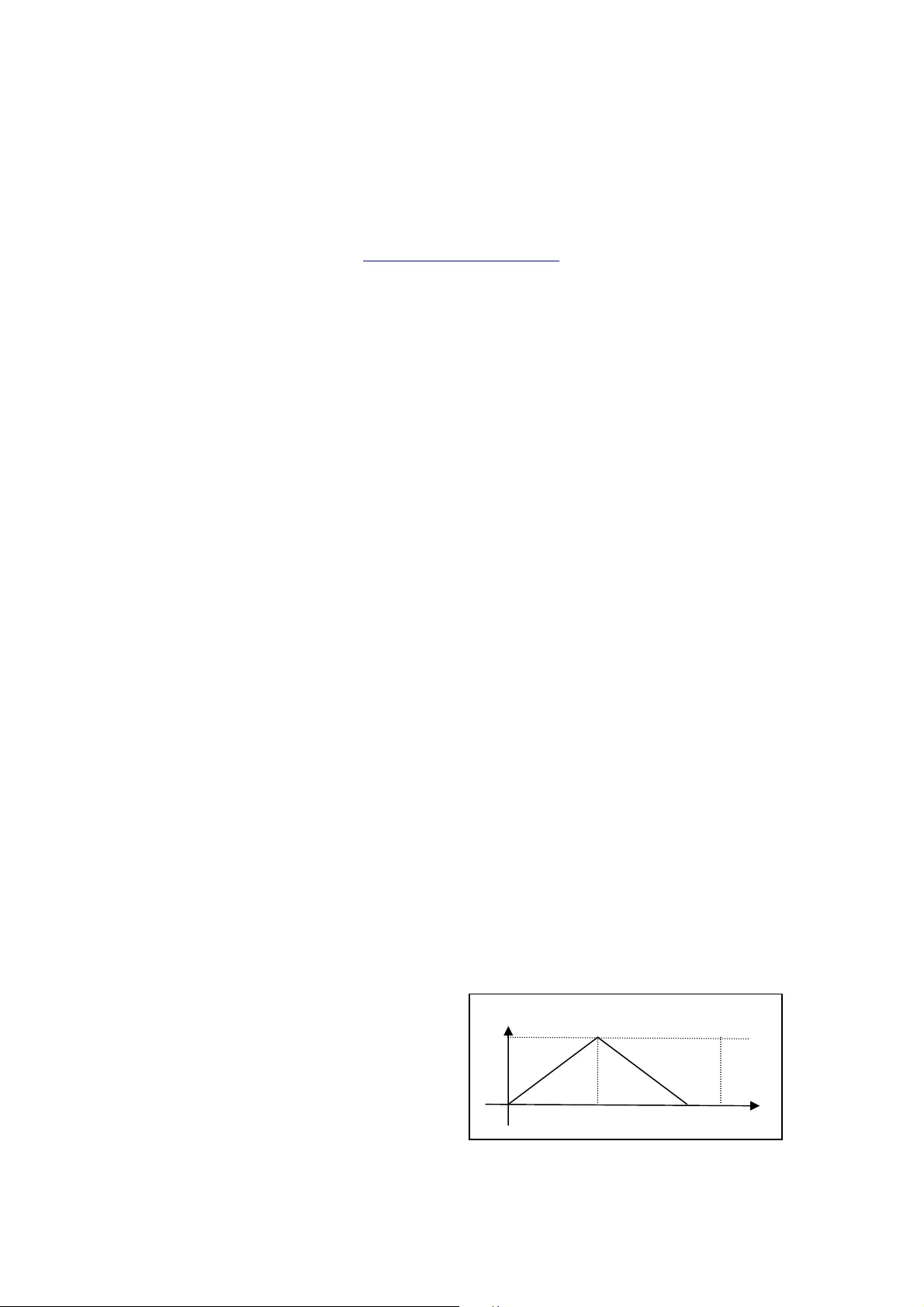
The paper presents a fuzzy‑logic framework for handling the uncertainty that arises when users employ natural‑language terms not predefined in a system’s vocabulary. The core idea is to represent the imprecise relationship between a user‑provided object (or goal) and a system‑defined counterpart using a membership function. Instead of requiring a complex set of rules or large training data, the approach starts from a single scalar “interpretation degree” supplied by the user, typically a value between 0 and 1 that expresses how closely the user’s concept matches the system’s concept. This value determines the initial position of the core (the region of full membership) of a triangular or Gaussian‑shaped membership function, while the surrounding support region is set symmetrically.
During the learning phase, each additional interpretation degree for the same object triggers an adaptive update of the membership function. If the new value lies to the right of the existing core, the right boundary of the core is shifted outward by a fixed proportion; if it lies to the left, the left boundary is adjusted similarly. This incremental refinement allows the function to converge toward the user’s personal linguistic habits without requiring a full retraining of the system.
To decide which system object best matches a user object, the authors introduce a decision coefficient. The coefficient quantifies the overlap between the cores of two membership functions, normalized by the total size of both cores. Mathematically it can be expressed as the ratio of the intersecting core length to the union of the core lengths. The coefficient ranges from 0 (no overlap) to 1 (perfect overlap) and serves as a clear, quantitative criterion for selecting the most appropriate system counterpart.
The methodology is evaluated in a simulated file‑management scenario where users issue commands such as “delete”, “remove”, or “erase”. Participants provide initial interpretation degrees for each synonym, and the system updates the corresponding membership functions over five learning iterations. Results show that the functions quickly adapt to the users’ perceptions, and the decision‑coefficient‑based matching improves command recognition accuracy by roughly 18 % compared with a baseline keyword‑matching approach. Moreover, adding a new term requires updating only its associated membership function, demonstrating the scalability of the technique.
The authors discuss several limitations. The initial interpretation degree is inherently subjective; extreme values (near 0 or 1) can bias the membership function and may need correction through expert feedback or prior calibration data. The current model handles a single dimension (the degree of similarity) and does not directly address multi‑attribute objects such as those characterized by color, size, or other features. Extending the framework to multi‑dimensional fuzzy spaces and incorporating dynamic weighting for multiple goals are identified as future research directions.
In conclusion, the paper shows that a simple, user‑driven scalar can be transformed into a full fuzzy representation that learns and adapts over time, providing a practical solution for natural‑language interfaces where vocabulary gaps and uncertainty are common. The approach offers a lightweight alternative to data‑intensive machine‑learning methods while retaining the ability to quantify and reason about ambiguity through the decision coefficient. Future work will explore integration with deep‑learning embeddings and deployment in large‑scale, real‑time systems.