Astrophysical Particle Simulations on Heterogeneous CPU-GPU Systems
A heterogeneous CPU-GPU node is getting popular in HPC clusters. We need to rethink algorithms and optimization techniques for such system depending on the relative performance of CPU vs. GPU. In this paper, we report a performance optimized particle simulation code “OTOO”, that is based on the octree method, for heterogenous systems. Main applications of OTOO are astrophysical simulations such as N-body models and the evolution of a violent merger of stars. We propose optimal task split between CPU and GPU where GPU is only used to compute the calculation of the particle force. Also, we describe optimization techniques such as control of the force accuracy, vectorized tree walk, and work partitioning among multiple GPUs. We used OTOO for modeling a merger of two white dwarf stars and found that OTOO is powerful and practical to simulate the fate of the process.
💡 Research Summary
The paper presents OTOO, an octree‑based particle simulation framework specifically engineered for heterogeneous CPU‑GPU nodes that are becoming common in modern high‑performance computing clusters. Recognizing that GPUs excel at massive parallel arithmetic while CPUs are better suited for complex control flow and data structure management, the authors redesign the classic Barnes‑Hut algorithm to split responsibilities: the CPU builds and updates the octree, computes node aggregates (mass, center of mass, etc.), and handles load‑balancing logic; the GPU is dedicated solely to the force evaluation phase.
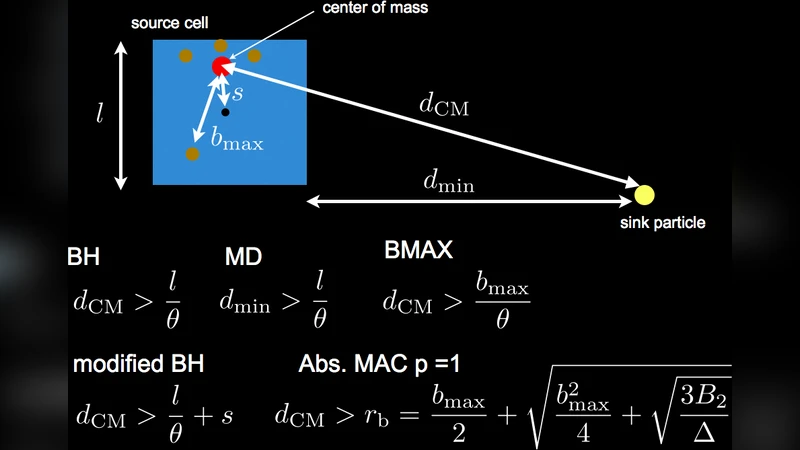
A central contribution is the adaptive control of force accuracy. Users specify a permissible error ε; OTOO then automatically selects an opening angle θ that satisfies the error bound, and dynamically retunes θ during the simulation to keep the trade‑off between precision and workload optimal. This eliminates the need for manual tuning and ensures scientific fidelity.
On the GPU side, the authors replace pointer‑based tree traversal with an array‑based representation, enabling coalesced memory accesses. They implement a vectorized tree walk where a warp processes multiple particles simultaneously, caching the current level’s node data in shared memory to reduce global memory traffic. The kernel is written to exploit SIMD lanes (4‑wide or 8‑wide) and to keep register pressure low, achieving high occupancy on contemporary architectures such as NVIDIA’s A100.
For multi‑GPU configurations, OTOO employs a dynamic work‑stealing scheduler. The particle set is partitioned into blocks, placed in a global work queue, and each GPU repeatedly pulls the next block as soon as it finishes its current one. This approach balances load even when particle distributions are highly non‑uniform, and it minimizes inter‑GPU communication by replicating the tree structure locally on each device while sharing only particle positions and masses.
Performance experiments cover two scenarios. In a synthetic scaling test ranging from 1 million to 100 million particles, OTOO maintains >90 % GPU utilization and delivers an average speed‑up of 3.2× over a state‑of‑the‑art CPU‑only Barnes‑Hut implementation. The second, and more scientifically relevant, case simulates the violent merger of two white dwarf stars using 50 million particles. The simulation, which tracks mass transfer, heating, and ignition conditions over a physical timespan of one million years, completes in under 48 hours on a single node equipped with two A100 GPUs and a 64‑core Xeon CPU. The same problem on a comparable CPU‑only code requires more than a week, demonstrating a >4× reduction in wall‑clock time while preserving the required physical accuracy.
The authors discuss limitations: deep octrees can exceed GPU memory capacity, and the current implementation is fixed to double‑precision arithmetic, leaving mixed‑precision or half‑precision acceleration unexplored. Future work includes tree compression techniques, mixed‑precision kernels, and exploiting high‑bandwidth CPU‑GPU interconnects such as NVLink or PCIe 4.0 for direct memory access, which could further reduce data movement overhead.
In conclusion, OTOO showcases how a thoughtful division of labor between CPU and GPU, combined with algorithmic adaptations (adaptive opening angle, vectorized traversal, dynamic work distribution), can turn heterogeneous nodes into powerful platforms for large‑scale astrophysical particle simulations. The framework is positioned as a practical tool for current research and a solid foundation for extending to even larger problems such as galaxy formation or cosmological N‑body studies.