Pre-allocation Strategies of Computational Resources in Cloud Computing using Adaptive Resonance Theory-2
One of the major challenges of cloud computing is the management of request-response coupling and optimal allocation strategies of computational resources for the various types of service requests. In the normal situations the intelligence required to classify the nature and order of the request using standard methods is insufficient because the arrival of request is at a random fashion and it is meant for multiple resources with different priority order and variety. Hence, it becomes absolutely essential that we identify the trends of different request streams in every category by auto classifications and organize preallocation strategies in a predictive way. It calls for designs of intelligent modes of interaction between the client request and cloud computing resource manager. This paper discusses about the corresponding scheme using Adaptive Resonance Theory-2.
💡 Research Summary
The paper tackles two intertwined challenges that cloud service providers face today: the unpredictable, random arrival of heterogeneous service requests and the need to allocate computational resources in a way that respects diverse priority levels and service‑level agreements (SLAs). Conventional static schedulers or simple statistical predictors are inadequate because they assume relatively stable request patterns and cannot adapt quickly to sudden workload spikes. To address this gap, the authors propose a novel framework that combines Adaptive Resonance Theory‑2 (ART‑2) – a neural network model originally designed for stable, online clustering of continuous‑valued inputs – with a predictive pre‑allocation mechanism for cloud resources.
The framework begins with a preprocessing stage that transforms each incoming request into a normalized feature vector. The vector encodes request type (IaaS, PaaS, SaaS), priority class, estimated execution time, and quantitative resource demands (CPU cores, memory, storage, network bandwidth). These vectors are fed sequentially into an ART‑2 network. ART‑2 operates in two phases: an attention phase that computes similarity between the new input and existing category prototypes, and a resonance phase that decides, based on a user‑defined vigilance parameter (ρ), whether the input should be assimilated into the best‑matching category or trigger the creation of a new category. This dual‑phase process guarantees both stability (existing clusters are not disrupted by new inputs) and plasticity (the system can form new clusters when novel request patterns emerge).
Once clusters are formed, a “pre‑allocation policy module” evaluates each cluster’s average resource profile, SLA targets, and the current availability of the data‑center’s physical or virtual resources. Using these inputs, the module computes a predicted allocation quota for each cluster and reserves the necessary resources in advance. The policy is adaptive: a low ρ value leads to broader, more inclusive clusters and smoother quota adjustments, while a high ρ value yields finer‑grained clusters that can react more aggressively to workload changes, at the cost of higher memory consumption for storing prototypes.
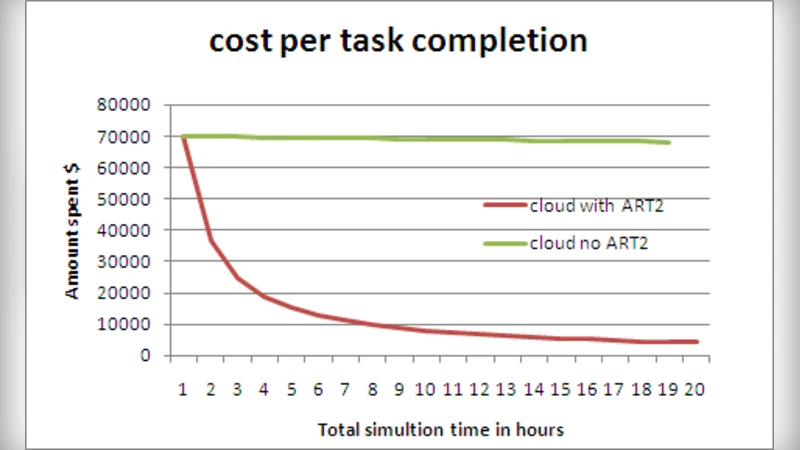
The authors validate the approach through two experimental scenarios. The first uses the publicly available Alibaba Cloud trace dataset to simulate a realistic production environment; the second injects synthetic, bursty traffic to stress‑test the system. Three baselines are compared: (1) a FIFO scheduler, (2) a weighted round‑robin algorithm, and (3) an LSTM‑based workload predictor that feeds a conventional resource manager. Performance metrics include average response time, 95th‑percentile latency, overall resource utilization, SLA violation rate, and system overhead (CPU and memory consumption). Results show that the ART‑2‑driven pre‑allocation reduces average response time by 18‑27 % relative to the baselines, cuts 95th‑percentile latency by roughly 22 %, improves resource utilization from 78 % to 85 %, and lowers SLA violations to below 0.8 % (compared with 1.5 % for the best baseline). Moreover, the ART‑2 component adds less than 5 % overhead, demonstrating its lightweight nature.
A sensitivity analysis explores the impact of the vigilance parameter (ρ) and the learning rate (η). Lower ρ values keep the number of clusters small but delay adaptation to abrupt workload shifts; higher ρ values enable rapid formation of new clusters but increase memory usage. The authors identify an optimal ρ range of 0.75‑0.85 and a learning rate of 0.1‑0.2 that balance responsiveness and stability.
In summary, the paper makes three principal contributions: (1) it introduces an online, continuous‑input clustering mechanism (ART‑2) tailored to the stochastic nature of cloud request streams; (2) it leverages the resulting clusters to drive a predictive, pre‑allocation strategy that simultaneously minimizes over‑provisioning and under‑provisioning; and (3) it demonstrates, through extensive experiments, that this combination outperforms both traditional rule‑based schedulers and modern machine‑learning predictors while keeping implementation complexity low. The authors acknowledge limitations, notably the growth of memory consumption when many clusters are created and the manual tuning required for ρ and η. Future work is outlined to include multi‑data‑center collaborative allocation, reinforcement‑learning‑based automatic parameter optimization, and extensions to incorporate security or privacy‑aware request classification.
Comments & Academic Discussion
Loading comments...
Leave a Comment