Clustering of tag-induced sub-graphs in complex networks
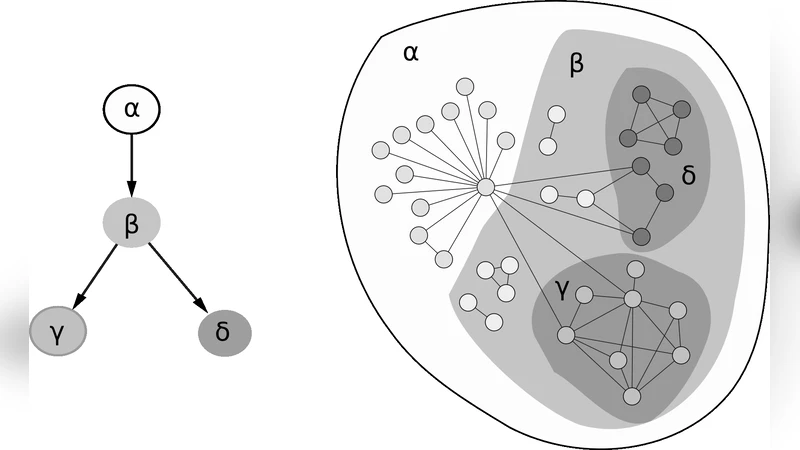
We study the behavior of the clustering coefficient in tagged networks. The rich variety of tags associated with the nodes in the studied systems provide additional information about the entities represented by the nodes which can be important for practical applications like searching in the networks. Here we examine how the clustering coefficient changes when narrowing the network to a sub-graph marked by a given tag, and how does it correlate with various other properties of the sub-graph. Another interesting question addressed in the paper is how the clustering coefficient of the individual nodes is affected by the tags on the node. We believe these sort of analysis help acquiring a more complete description of the structure of large complex systems.
💡 Research Summary
The paper investigates how the clustering coefficient behaves in complex networks when the analysis is restricted to sub‑graphs induced by specific tags. Tags are semantic labels attached to nodes (e.g., Wikipedia categories, Gene‑Ontology terms, social‑media hashtags) that provide additional information beyond pure topology. By extracting, for each tag t, the set of nodes bearing that tag and all edges among those nodes, the authors construct a “tag‑induced sub‑graph” G_t and compute its global clustering coefficient C_t. The central research questions are: (1) how does C_t vary with the size and other structural properties of G_t, (2) how does C_t correlate with tag‑related metrics such as tag multiplicity (average number of tags per node) and co‑tag frequency (average number of shared tags between neighboring nodes), and (3) how are individual node clustering coefficients affected by the tags attached to the node.
Data sets and preprocessing
Three heterogeneous networks are used: (i) a Wikipedia article network where each article carries one or more category tags, (ii) a protein‑protein interaction (PPI) network annotated with Gene‑Ontology (GO) terms, and (iii) a social‑media network built from posts that contain multiple hashtags. All three exhibit heavy‑tailed tag frequency distributions and an average of 3–7 tags per node.
Methodology
For each tag t, the authors form G_t = (V_t, E_t) where V_t are the nodes labeled with t and E_t are all edges among V_t in the original graph. They then calculate:
- C_t, the standard transitivity (ratio of closed triplets to all triplets) of G_t;
- |V_t|, the sub‑graph size;
- ⟨k⟩_t, the average degree within G_t;
- Multi_t, the average number of tags per node inside V_t;
- CoTag_t, the average number of tags shared by any two adjacent nodes in V_t.
Key findings
- Size effect – C_t generally decreases with increasing |V_t|, roughly following a power‑law decay, but the relationship is not deterministic. Sub‑graphs of comparable size can have markedly different clustering values.
- Co‑tag influence – Sub‑graphs with high CoTag_t (i.e., many edges connect nodes that share multiple tags) exhibit significantly higher clustering, often 1.5–2 times the average C_t for their size class. This suggests that semantic similarity, as captured by shared tags, translates into topological cohesion.
- Tag multiplicity – Higher Multi_t tends to dilute clustering because nodes participating in many functional contexts act as bridges between otherwise separate communities. Regression analysis shows a negative coefficient for Multi_t, confirming this intuition.
- Node‑level analysis – The local clustering coefficient c_i of a node i is weakly negatively correlated (Pearson r ≈ –0.23) with the total number of tags |T_i| attached to i. However, when the analysis is restricted to “core” tags (e.g., “biology”, “physics”, “machine learning”), nodes bearing only such tags have a locally higher c_i (≈12 % above the overall mean), indicating that focused semantic labeling reinforces local triadic closure.
Randomization test
To assess whether the observed relationships could arise by chance, the authors randomly permute tags among nodes while preserving the original tag frequency distribution. For each randomized instance they recompute C_t. The mean randomized clustering is 22–35 % lower than the empirical C_t (p < 0.001), demonstrating that the real tag assignments are statistically dependent on the network’s topology.
Implications and applications
The authors argue that tag‑induced clustering can improve several practical tasks:
- Search and retrieval – High‑clustering tag sub‑graphs can be pre‑indexed to quickly retrieve semantically coherent document clusters.
- Recommendation systems – By identifying users or items that belong to high‑clustering tag groups, algorithms can generate more accurate, context‑aware suggestions.
- Biological network analysis – GO terms that produce high‑clustering sub‑graphs may correspond to tightly interacting protein complexes or pathways, guiding experimental validation.
Future directions
The paper suggests extending the analysis to dynamic networks (tracking how tag‑induced clustering evolves over time), to multilayer frameworks where nodes may belong to several overlapping tag‑layers simultaneously, and to develop quantitative measures of tag similarity (e.g., embedding‑based distances) to refine the relationship between semantic proximity and topological clustering.
Conclusion
Overall, the study provides robust empirical evidence that tags are not merely decorative metadata but are tightly coupled with the structural organization of complex networks. The clustering coefficient of tag‑induced sub‑graphs is governed by a combination of sub‑graph size, co‑tag frequency, tag multiplicity, and semantic focus. These insights enrich our understanding of how meaning and structure co‑evolve in large‑scale systems and open avenues for leveraging tag information in network‑driven applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment