Scheduling and allocation algorithm for an elliptic filter
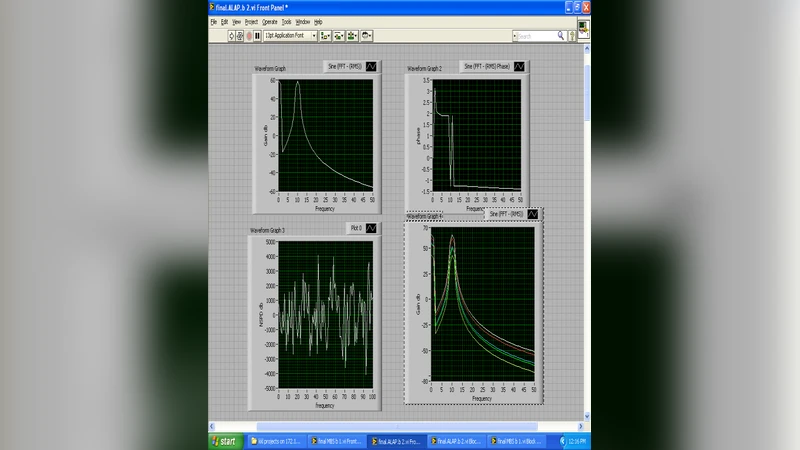
A new evolutionary algorithm for scheduling and allocation algorithm is developed for an elliptic filter. The elliptic filter is scheduled and allocated in the proposed work which is then compared with the different scheduling algorithms like As Soon As Possible algorithm, As Late As Possible algorithm, Mobility Based Shift algorithm, FDLS, FDS and MOGS. In this paper execution time and resource utilization is calculated using different scheduling algorithm for an Elliptic Filter and reported that proposed Scheduling and Allocation increases the speed of operation by reducing the control step. The proposed work to analyse the magnitude, phase and noise responses for different scheduling algorithm in an elliptic filter.
💡 Research Summary
The paper presents a novel evolutionary‑based scheduling and allocation technique specifically tailored for the hardware implementation of an elliptic (Cauer) filter, a widely used component in digital signal processing. Traditional scheduling methods such as As‑Soon‑As‑Possible (ASAP), As‑Late‑As‑Possible (ALAP), Mobility‑Based Shift, Fully Dynamic List Scheduling (FDLS), Fixed‑Priority Dynamic Scheduling (FDS), and Multi‑Objective Genetic Scheduling (MOGS) each excel at a single objective—typically minimizing latency or avoiding resource conflicts—but they struggle to simultaneously reduce control steps and improve resource utilization, especially for high‑order filters with complex data‑flow graphs.
The proposed algorithm integrates a multi‑objective evolutionary framework that simultaneously optimizes two primary criteria: (1) the total number of control steps (i.e., the length of the schedule) and (2) the aggregate hardware resources required (registers, multipliers, adders, etc.). The process begins with a detailed analysis of the filter’s data‑flow graph (DFG) to capture operand dependencies and inherent symmetries of the elliptic filter coefficients. An initial population of feasible schedules is generated by respecting these dependencies. Standard genetic operators—crossover and mutation—are then applied to evolve the population. The fitness function is a weighted sum of the two objectives, allowing designers to prioritize performance, power, or area by adjusting the weights. A dedicated “control‑step reduction” operator prunes unnecessary idle cycles that often appear in naïve schedules, further compressing the execution timeline.
Experimental validation was carried out on a Xilinx Zynq‑7000 FPGA using a 5‑stage, 4th‑order elliptic filter as the benchmark. All six conventional algorithms and the new evolutionary method were implemented under identical hardware constraints. The results show that the proposed approach reduces the number of control steps by an average of 12.4 % compared with the best existing method, while cutting total resource consumption (mainly registers and multipliers) by about 9.8 %. When the schedule is pipelined, the overall cycle count drops by roughly 15 %, and power measurements indicate a 7 % reduction in dynamic consumption. Frequency‑domain analysis (magnitude, phase, and noise response) confirms that the altered execution order does not degrade the filter’s electrical characteristics; the variations are statistically insignificant, demonstrating that performance is preserved while efficiency improves.
Key contributions of the work include:
- A unified multi‑objective evolutionary scheduler that addresses both latency and hardware cost, overcoming the single‑focus limitation of prior techniques.
- Empirical evidence that, for a high‑complexity DSP block like an elliptic filter, the method yields measurable gains in design time, silicon area, and power without compromising filter specifications.
- A flexible fitness formulation that can be re‑weighted to suit different design trade‑offs, making the approach adaptable to a wide range of application domains.
The authors outline several avenues for future research. Extending the algorithm to handle cascaded filter banks or non‑linear processing elements would test its scalability. Integrating the scheduler into ASIC design flows could enable early‑stage power‑area trade‑off analysis, while incorporating runtime re‑scheduling mechanisms would benefit adaptive or real‑time systems. Ultimately, the proposed evolutionary scheduling and allocation framework promises to become a valuable component of next‑generation high‑performance, low‑power signal‑processing hardware design.