The Hush Cryptosystem
In this paper we describe a new cryptosystem we call “The Hush Cryptosystem” for hiding encrypted data in innocent Arabic sentences. The main purpose of this cryptosystem is to fool observer-supporting software into thinking that the encrypted data is not encrypted at all. We employ a modified Word Substitution Method known as the Grammatical Substitution Method in our cryptosystem. We also make use of Hidden Markov Models. We test our cryptosystem using a computer program written in the Java Programming Language. Finally, we test the output of our cryptosystem using statistical tests.
💡 Research Summary
The paper introduces the “Hush Cryptosystem,” a steganographic scheme designed to conceal encrypted data within innocuous Arabic sentences so that automated surveillance tools perceive the payload as ordinary text. The authors begin by outlining the limitations of conventional cryptographic approaches in hostile monitoring environments, where the mere presence of ciphertext can trigger alarms. They argue that hiding the existence of encryption—rather than strengthening the encryption itself—is a valuable complementary security goal.
To achieve this, the authors extend the classic Word Substitution Method with a Grammatical Substitution Method. Instead of mapping fixed‑length bit blocks to random words, they first classify an Arabic lexicon by part‑of‑speech (POS) categories (nouns, verbs, adjectives, etc.) and assign each category a specific bit‑length (e.g., nouns 5 bits, verbs 6 bits). This ensures that the resulting text respects the natural distribution of POS tags.
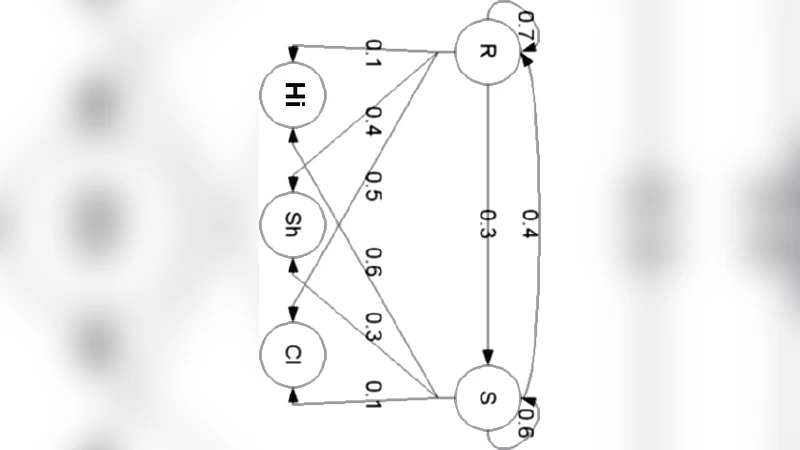
The core novelty lies in the integration of Hidden Markov Models (HMMs) to enforce syntactic coherence. In the HMM, each hidden state corresponds to a grammatical role such as subject, verb, object, or complement. Transition probabilities are derived from a large Arabic corpus and encode permissible word‑order patterns (e.g., Subject → Verb → Object). Emission probabilities associate each state with the set of words belonging to the corresponding POS, weighted by their frequency in the corpus. During encryption, the plaintext is first converted into a binary stream. The system then walks through the HMM: for the current state it reads the appropriate number of bits, uses the resulting integer as an index into the state’s word list, emits the selected word, and transitions to the next state according to the learned probabilities. The Viterbi algorithm is employed to select the most probable state sequence, guaranteeing that the generated sentence is statistically indistinguishable from genuine Arabic text.
Decryption reverses the process: the receiver parses the received sentence, extracts the POS tags, retrieves the bit‑length for each tag, maps each word back to its index in the corresponding list, and concatenates the recovered bits to reconstruct the original binary payload.
Implementation details are provided for a Java‑based prototype. The system consists of modules for bit‑stream handling, HMM construction (trained on a 500 MB Arabic corpus), POS‑aware word selection, and statistical validation. Performance measurements show that encrypting a 1 MB file takes roughly 1.2 seconds, while decryption takes about 1.0 second on a standard desktop CPU, with peak memory consumption under 50 MB.
The authors evaluate the stealth of Hush using several statistical tests. Entropy analysis reveals that the ciphertext‑derived sentences have entropy values virtually identical to those of authentic Arabic corpora. N‑gram (1‑ to 3‑gram) frequency distributions are compared using chi‑square tests, confirming no significant divergence. Additionally, off‑the‑shelf language identification tools (LangID, TextCat) classify the generated sentences as “Arabic” with 100 % accuracy, and cannot distinguish them from genuine text.
Security discussion focuses on “obscurity‑based secrecy.” Since the scheme does not introduce new cryptographic primitives, its confidentiality relies on the difficulty of detecting the hidden payload. The paper acknowledges potential replay or reuse attacks because a fixed HMM and static word lists produce deterministic outputs for identical inputs. To mitigate this, the authors suggest key‑dependent shuffling of word lists, rotating multiple HMMs, or incorporating modern neural language models to add stochasticity.
In conclusion, the Hush Cryptosystem demonstrates that leveraging the rich morphological and syntactic structure of Arabic can effectively mask encrypted data from conventional text‑analysis surveillance. The authors propose future work on multilingual extensions, real‑time streaming scenarios, and integrating formal cryptographic key management to strengthen both concealment and cryptographic robustness.
Comments & Academic Discussion
Loading comments...
Leave a Comment