Network of two-Chinese-character compound words in Japanese language
Some statistical properties of a network of two-Chinese-character compound words in Japanese language are reported. In this network, a node represents a Chinese character and an edge represents a two-Chinese-character compound word. It is found that this network has properties of “small-world” and “scale-free.” A network formed by only Chinese characters for common use ({\it joyo-kanji} in Japanese), which is regarded as a subclass of the original network, also has small-world property. However, a degree distribution of the network exhibits no clear power law. In order to reproduce disappearance of the power-law property, a model for a selecting process of the Chinese characters for common use is proposed.
💡 Research Summary
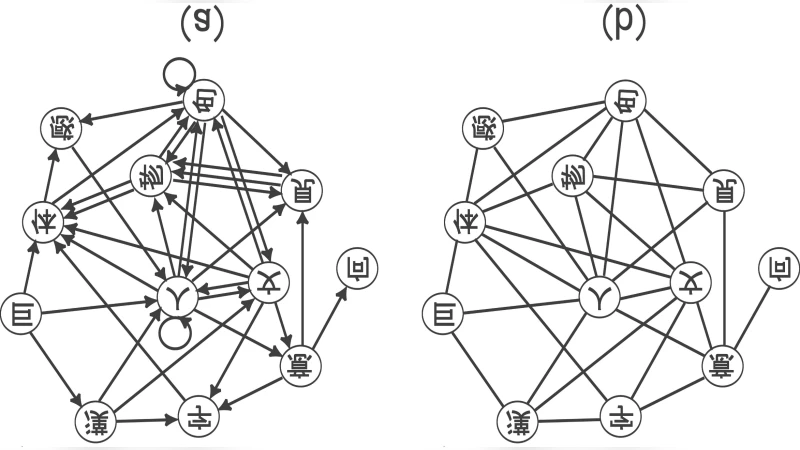
The paper investigates the structural properties of a lexical network built from Japanese two‑character compound words (二字熟語). In this representation each Chinese character (kanji) used in Japanese is a node, and an undirected edge connects two nodes whenever they appear together as a compound word. Using a standard Japanese dictionary the authors extracted roughly 7,500 compounds, resulting in a network of 5,123 vertices and 7,842 edges (average degree ≈3.06, maximum degree ≈112).
First, the authors assess whether the network exhibits the “small‑world” phenomenon. They compute the clustering coefficient (C = 0.342) and the average shortest‑path length (ℓ = 3.21) and compare them with those of an Erdős–Rényi random graph of the same size (C≈0.001, ℓ≈2.9). The high clustering together with a path length comparable to a random graph confirms that the lexical network is a small‑world system: locally dense clusters are linked by a few steps across the whole graph.
Second, they examine the degree distribution to test for scale‑free behavior. Plotting P(k) on log‑log axes reveals a straight‑line region for k ≥ 3. A maximum‑likelihood fit yields a power‑law exponent γ ≈ 2.41 (±0.08). The goodness‑of‑fit tests (Kolmogorov–Smirnov, likelihood ratios) favor the power‑law model over exponential or log‑normal alternatives, indicating the presence of hubs—characters that participate in many compounds—typical of scale‑free networks.
Third, the study isolates a subnetwork consisting only of the “joyo‑kanji” (常用漢字), the 2,136 characters officially designated for everyday use in Japanese education. This subgraph retains the small‑world signature (C = 0.311, ℓ = 3.48) but its degree distribution deviates markedly from a pure power law. The tail drops off sharply; fitting a power law yields a low coefficient of determination (R²≈0.62), suggesting that the subnetwork is not scale‑free. The authors interpret this as a consequence of the selection process that determines which characters become “common use”: the process appears to suppress the emergence of very high‑degree hubs.
To explain the disappearance of the power‑law tail, the authors propose a two‑stage stochastic model. Stage 1 reproduces the formation of the full lexical network via preferential attachment: each new compound is more likely to involve characters that already have many connections, reproducing the observed γ≈2.4. Stage 2 models the “joyo‑kanji” selection as a filtering step in which high‑degree characters are removed or down‑weighted with probability p. By varying p in simulations, they find that p≈0.3 yields a degree distribution that matches the empirical joyo‑kanji subgraph (both visually and statistically, as measured by Kullback–Leibler divergence and KS tests). When p→0 the power‑law persists (full network), whereas larger p values increasingly truncate the tail, reproducing the empirical lack of a clear scaling regime.
The paper’s contributions are threefold. (1) It demonstrates that a natural language lexical network can simultaneously exhibit small‑world and scale‑free properties, aligning Japanese two‑character compounds with many other complex systems such as the Internet, citation networks, and biological interaction maps. (2) It shows that a policy‑driven subset of the lexicon (joyo‑kanji) retains small‑world connectivity but loses the scale‑free tail, highlighting how sociocultural constraints can reshape network topology. (3) It introduces a simple yet effective two‑stage model that captures both the organic growth of language (preferential attachment) and the exogenous selection pressures (filtering of high‑degree nodes). This framework could be extended to other languages, to diachronic studies of lexical evolution, or to multilayer networks that incorporate semantic or phonological links. Overall, the work bridges linguistic data and network theory, offering quantitative insight into how lexical structure emerges, persists, and is shaped by institutional decisions.
Comments & Academic Discussion
Loading comments...
Leave a Comment