Document summarization using positive pointwise mutual information
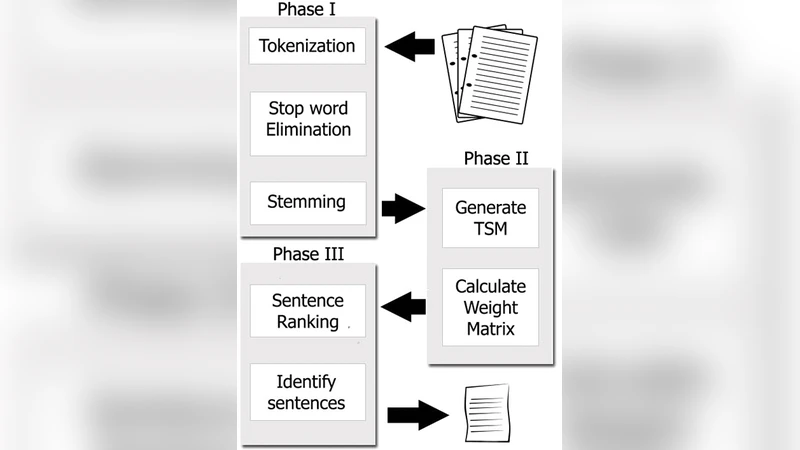
The degree of success in document summarization processes depends on the performance of the method used in identifying significant sentences in the documents. The collection of unique words characterizes the major signature of the document, and forms the basis for Term-Sentence-Matrix (TSM). The Positive Pointwise Mutual Information, which works well for measuring semantic similarity in the Term-Sentence-Matrix, is used in our method to assign weights for each entry in the Term-Sentence-Matrix. The Sentence-Rank-Matrix generated from this weighted TSM, is then used to extract a summary from the document. Our experiments show that such a method would outperform most of the existing methods in producing summaries from large documents.
💡 Research Summary
The paper presents a novel extractive summarization framework that leverages Positive Pointwise Mutual Information (PPMI) to weight a term‑sentence matrix (TSM) and subsequently rank sentences for summary generation. The authors begin by constructing a TSM where rows correspond to unique lexical items extracted from the document and columns correspond to individual sentences; each cell records the raw frequency of a term in a sentence. Unlike traditional TF‑IDF or LSA weighting schemes, the authors replace raw frequencies with PPMI values, defined as log