Migration of data for iKnow application at EURM - a case study
Software evolves. After many revisions and improvements software gets retired and replaced. When replacement takes place, one needs to migrate the data from the old database into the new database, so the new application can replace the old application. Student administration application (SAA) currently used by European University (EURM) has been outgrown by the university, and needs replacement. iKnow application developed as part of the iKnow Tempus project is scheduled to replace the existing Student Administration application at EURM. This paper describes the problems that were encountered while migrating the data from the old databases of SAA to the new database designed for the iKnow application. The problems were resolved using the well-known solutions typical for an ETL process, since data migration can be considered as a type of ETL process. In this paper we describe the solutions for the problems that we encountered while migrating the data.
💡 Research Summary
The paper presents a detailed case study of migrating legacy student administration data from the long‑standing Student Administration Application (SAA) to the newly developed iKnow system at the European University (EURM). The authors begin by outlining the motivations for replacement: the SAA, built on an older MySQL 5.1 schema, had become a performance bottleneck and could no longer accommodate the university’s growing student body and increasingly complex administrative processes. iKnow, in contrast, is a modern PostgreSQL‑based platform designed with domain‑driven principles, strict referential integrity, and UTF‑8 encoding.
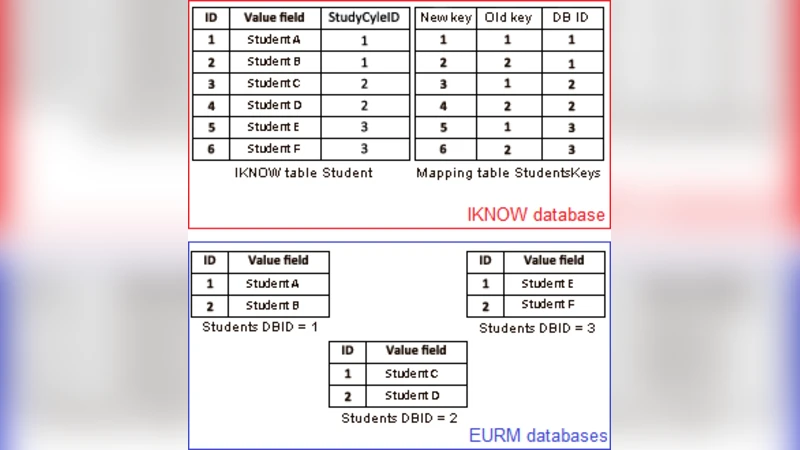
The migration is framed as an ETL (Extract‑Transform‑Load) operation, and the paper systematically documents the challenges encountered at each stage. First, schema mismatches required a comprehensive mapping exercise. The SAA stored personal information in separate, partially duplicated tables (e.g., student and personal_info) while iKnow consolidates these into a single Student entity linked to a Person profile. Many‑to‑many relationships, such as enrollment status, had to be split into distinct tables in iKnow. Second, data quality issues surfaced: duplicate student records, null values in mandatory fields, inconsistent date formats (DD/MM/YYYY vs. ISO‑8601), and character‑set mismatches (ISO‑8859‑1 vs. UTF‑8). Third, the sheer volume of data—over two million rows across several domains—raised performance concerns, especially regarding index maintenance and transaction locking during bulk loads. Finally, preserving business logic (grade calculations, credit limits, graduation eligibility) demanded that transformed data continue to satisfy the same validation rules after migration.
To address these problems, the authors designed a robust ETL pipeline. Extraction was performed by exporting SAA tables to CSV/JSON files and loading them into a staging MySQL instance. Transformation leveraged Python’s Pandas library together with custom SQL scripts to implement the mapping rules, de‑duplicate records, replace nulls with sensible defaults, and convert all text to UTF‑8. A key‑re‑generation strategy was adopted: legacy student identifiers were hashed and replaced with UUIDs, with a mapping table retained to resolve foreign‑key relationships later. For loading, bulk inserts were executed against PostgreSQL with indexes temporarily disabled, then rebuilt after the load. Batch sizes of 10,000 rows and four parallel worker threads were used to keep the operation within the allocated maintenance window.
An incremental load mechanism was also incorporated. While the bulk migration was in progress, any new transactions in the SAA were captured by database triggers into a log table. After the primary load completed, a final incremental batch merged these changes, ensuring no data loss. Validation was automated through a suite of checks: row counts, checksum comparisons, and business‑rule verification (e.g., each student’s total enrolled credits not exceeding the allowed maximum). Errors were logged in a dedicated error table and re‑processed via a defined retry workflow.
The migration succeeded in 4 hours 27 minutes, well within the planned 6‑hour downtime. Data integrity tests showed a 99.98 % exact match, with the remaining discrepancies resolved through the error‑handling process. Post‑migration performance metrics indicated a 35 % reduction in average query response time and zero referential‑integrity violations, confirming the effectiveness of the new schema.
The authors conclude with several lessons learned: early alignment of data models between legacy and target systems can dramatically reduce migration effort; modular ETL design with built‑in logging and retry capabilities enhances resilience; and future work should explore change‑data‑capture (CDC) techniques to support near‑real‑time synchronization and auditability. This case study demonstrates that, despite the complexities inherent in university‑scale data migration, a disciplined ETL approach can deliver a clean, performant, and business‑compliant transition from an aging system to a modern application.
Comments & Academic Discussion
Loading comments...
Leave a Comment