A consistent adjacency spectral embedding for stochastic blockmodel graphs
We present a method to estimate block membership of nodes in a random graph generated by a stochastic blockmodel. We use an embedding procedure motivated by the random dot product graph model, a particular example of the latent position model. The em…
Authors: Daniel L. Sussman, Minh Tang, Donniell E. Fishkind
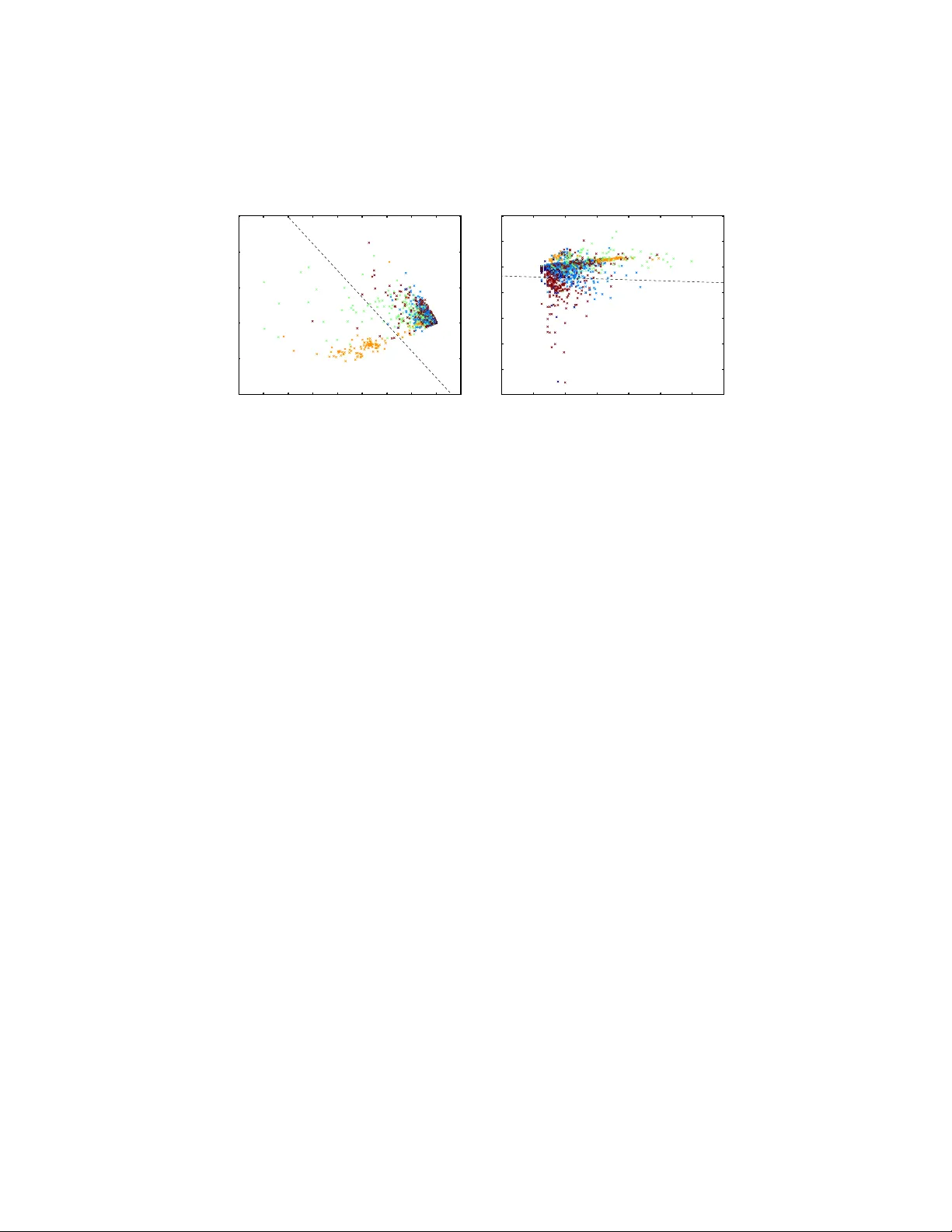
A consisten t adjacency sp ectral em b edding for sto c hastic blo c kmo del graphs Daniel L. Sussman, Minh T ang, Donniell E. Fishkind, Carey E. Prieb e Johns Hopkins Univ ersity , Applied Math and Statistics Departmen t No vem ber 27, 2024 Abstract W e presen t a method to estimate blo c k mem b ership of no des in a ran- dom graph generated b y a sto c hastic blo ckmodel. W e use an embedding pro cedure motiv ated by the random dot pro duct graph mo del, a partic- ular example of the laten t p osition mo del. The embedding asso ciates eac h no de with a vector; these vectors are clustered via minimization of a square error criterion. W e pro ve that this method is consistent for assigning nodes to blo c ks, as only a negligible num b er of no des will be mis-assigned. W e pro ve consistency of the metho d for directed and undi- rected graphs. The consisten t block assignment mak es possible consistent parameter estimation for a sto chastic blockmodel. W e extend the result in the setting where the num b er of blo c ks gro ws slowly with the num- b er of no des. Our metho d is also computationally feasible even for very large graphs. W e compare our metho d to Laplacian sp ectral clustering through analysis of simulated data and a graph derived from Wikip edia do cumen ts. 1 Bac kground and Ov erview Net work analysis is rapidly b ecoming a key tool in the analysis of mo dern datasets in fields ranging from neuroscience to so ciology to bio c hemistry . In eac h of these fields, there are ob jects, suc h as neurons, p eople, or genes, and there are relationships b et ween ob jects, suc h as synapses, friendships, or pro- tein interactions. The formation of these relationships can dep end on attributes of the individual ob jects as well as higher order prop erties of the net work as a whole. Ob jects with similar attributes can form communities with similar connectiv e structure, while unique prop erties of individuals can fine tune the shap e of these relationships. Graphs enco de the relationships b etw een ob jects as edges b etw een no des in the graph. Clustering ob jects based on a graph enables iden tification of communities and ob jects of in terest as w ell as illumination of o v erall net work structure. Find- ing optimal clusters is difficult and will dep end on the particular setting and 1 task. Ev en in mo derately sized graphs, the num ber of p ossible partitions of no des is enormous, so a tractable search strategy is necessary . Metho ds for finding clusters of no des in graphs are many and v aried, with origins in ph ysics, engineering, and statistics; F ortunato ( 2010 ) and Fjallstrom ( 1998 ) pro vide com- prehensiv e reviews of clustering tec hniques. In addition to tec hniques motiv ated b y heuristics based on graph structure, others hav e attempted to fit statistical mo dels with inheren t communit y structure to a graph. ( Airoldi et al. , 2008 ; Handco c k et al. , 2007 ; Nowic ki and Snijders , 2001 ; Snijders and Nowic ki , 1997 ). These statistical mo dels use random graphs to mo del relationships b et w een ob jects; Golden b erg et al. ( 2010 ) provides a review of statistical models for net works. A graph consists of a set of no des, representing the ob jects, and a set of edges, represen ting relationships betw een the ob jects. The edges can be either directed (ordered pairs of nodes) or undirected (unordered pairs of no des). In our setting, the no de set is fixed and the set of edges is random. Hoff et al. ( 2002 ) prop osed what they call a latent space mo del for random graphs. Under this mo del eac h no de is asso ciated with a latent random v ector. There ma y also b e additional cov ariate information which w e do not consider in this work. The vectors are indep endent and identically distributed and the probabilit y of an edge b et ween t wo nodes dep ends only on their latent v ectors. Conditioned on the latent v ectors, the presence of each edge is an indep endent Bernoulli trial. One example of a latent space mo del is the random dot pro duct graph (RDPG) mo del ( Y oun g and Scheinerman , 2007 ). Under the RDPG mo del, the probabilit y an edge b et ween t wo no des is presen t is given b y the dot pro duct of their respective latent v ectors. F or example, in a so cial netw ork with edges indicating friendships, the comp onen ts of the vector may b e interpreted as the relativ e interest of the individual in v arious topics. The magnitude of the v ec- tor can be in terpreted as how talk ativ e the individual is, with more talk ativ e individuals more likely to form relationships. T alk ative individuals in terested in the same topics are most lik ely to form relationships while individuals who do not share interests are unlikely to form relationships. W e present an embedding motiv ated by the RDPG mo del which uses a decomp osition of a lo w rank appro ximation of the adjacency matrix. The de- comp osition giv es an embedding of the nodes as vectors in a low dimensional space. This embedding is similar to embeddings used in sp ectral clustering but op erates directly on the adjacency matrix rather than a Laplacian. W e discuss a relationship b etw een sp ectral clustering and our work in Section 7 . Our results are for graphs generated b y a sto chastic blo c kmo del ( Holland et al. , 1983 ; W ang and W ong , 1987 ). In this mo del, each no de is assigned to a blo c k, and the probability of an edge b et w een tw o no des dep ends only on their resp ectiv e blo ck mem b erships; in this manner tw o no des in the same blo c k are sto c hastically equiv alen t. In the context of the laten t space mo del, all no des in the same blo ck are assigned the same latent v ector. An adv antage of this mo del is the clear and simple blo ck structure, where blo ck mem b ership is determined solely by the laten t v ector. Giv en a graph generated from a sto c hastic blo ckmodel, our primary goal is 2 Algorithm 1 The adjacency sp ectral clustering pro cedure for directed graphs. Input : A ∈ { 0 , 1 } n × n P arameters : d ∈ { 1 , 2 , . . . , n } , K ∈ { 2 , 3 , . . . , n } Step 1 : Compute the singular v alue decomposition, A = e U 0 e Σ 0 e V 0 T . Let e Σ 0 ha ve decreasing main diagonal. Step 2 : Let e U and e V b e the first d columns of e U 0 and e V 0 , resp ectively , and let e Σ b e the sub-matrix of e Σ 0 giv en b y the first d rows and columns. Step 3 : Define e Z = [ e U e Σ 1 / 2 | e V e Σ 1 / 2 ] ∈ R n × 2 d to b e the concatenation of the co ordinate-scaled singular vector matrices. Step 4 : Let ( ˆ ψ , ˆ τ ) = argmin ψ ; τ P n u =1 k e Z u − ψ τ ( u ) k 2 2 giv e the centroids and blo c k assignments, where e Z u is the u th ro w of e Z , ˆ ψ ∈ R K × d are the cen troids and ˆ τ is a function from [ n ] to [ K ]. return ˆ τ , the blo c k assignmen t function, to accurately assign all of the no des to their correct blo c ks. Algorithm 1 gives the main steps of our procedure. In summary these steps in volv e computing the singular v alue decomp osition of the adjacency matrix, reducing the dimen- sion, co ordinate-scaling the singular vectors by the square ro ot of their singular v alue and, finally , clustering via minimization of a square error criterion. W e note that Step 4 in the pro cedure is a mathematically con venien t stand in for what might b e used in practice. Indeed, the standard K -means algorithm ap- pro ximately minimizes the square error and w e use K -means for ev aluating the pro cedure empirically . This pap er sho ws that the no de assignmen ts returned b y Algorithm 1 are consisten t. Consistency of no de assignmen ts means that the prop ortion of mis-assigned no des goes to zero (probabilistically) as the n um b er of no des go es to infinity . Others hav e already sho wn similar consistency of no de assignments. Snijders and No wicki ( 1997 ) pro vided an algorithm to consisten tly assign nodes to blocks under the sto c hastic blo c kmo del for t wo blocks, and later Condon and Karp ( 2001 ) provided a consistent metho d for equal s ized blocks. Bick el and Chen ( 2009 ) show ed that maximizing the Newman–Girv an modularity ( Newman and Girv an , 2004 ) or the lik eliho o d mo dularity provides consisten t estimation of blo c k mem b ership. Choi et al. ( In press ) used likelihoo d methods to show consistency with rapidly gro wing n umbers of blo c ks. Maximizing mo dularities and likelihoo d metho ds are both computationally difficult, but pro vide theoretical results for rapidly growing num b ers of blo c ks. Our metho d is related to that of McSherry ( 2001 ), in that w e consider a lo w rank approximation the adjacency matrix, but their results do not pro vide con- sistency of no de assignments. Rohe et al. ( 2011 ) used sp ectral clustering to sho w consisten t estimation of blo ck partitions with growing n umber of blo c ks; in this pap er we demonstrate that for b oth directed and undirected graphs, our prop osed embedding allows for accurate block assignment in a sto chastic blo c k- mo del. These matrix decomposition metho ds are computati onally feasible, even for graphs with a large num b er of no des. 3 The remainder of the pap er is organized as follows. In Section 2 we formally presen t the sto c hastic blockmodel, the random dot pro duct graph mo del and our adjacency sp ectral embedding. In Section 3 w e state and prov e our main theorem, and in Section 4 w e presen t some useful Corollaries. Sections 2 – 4 focus only on directed random graphs; in Section 5 we presen t mo del and results for undirected graphs. In Section 6 we present sim ulations and empirical analysis to illustrate the p erformance of the algorithm. Finally , in section 7 we discuss further extensions to the theorem. In the appendix, we pro ve some k ey tec hnical results to prov e our main theorem. 2 Mo del and Em b edding First, we adopt the following con ven tions. F or a matrix M ∈ R n × m , entry i, j is denoted b y M ij . Ro w i is denoted M T i ∈ R 1 × d , where M i is a column vector. Column j is denoted as M · j and o ccasionally we refer to row i as M i · . The no de set is [ n ] = { 1 , 2 , . . . , n } . F or directed graphs edges are ordered pairs of elements in [ n ]. F or a random graph, the no de set is fixed and the edge set is random. The edges are enco ded in an adjacency matrix A ∈ { 0 , 1 } n × n . F or directed graphs, the entry A uv is 1 or 0 according as an edge from no de u to no de v is presen t or absent in the graph. W e co nsider graphs with no lo ops, meaning A uu = 0 for all u ∈ [ n ]. 2.1 Sto c hastic Blo ckmodel Our results are for random graphs distributed according to a sto c hastic blo c k- mo del ( Holland et al. , 1983 ; W ang and W ong , 1987 ), where each node is a mem- b er of exactly one blo c k and the probability of an edge from no de u to no de v is determined b y the blo ck mem b erships of no des u and v for all u, v ∈ [ n ]. The mo del is parametrized by P ∈ [0 , 1] K × K , and ρ ∈ (0 , 1) K with P K i =1 ρ i = 1. K is the n umber of blo cks, which are lab eled 1 , 2 , . . . , K . The blo c k mem b er- ships of all no des are determined by the random blo c k membership function τ : [ n ] 7→ [ K ]. F or all nodes u ∈ [ n ] and blo c ks i ∈ [ K ], τ ( u ) = i would mean no de u is a mem b er of blo ck i ; no de memberships are indep enden t with P [ τ ( u ) = i ] = ρ i . The en try P ij giv es the probability of an edge from a node in blo c k i to a no de in blo c k j for eac h i, j ∈ [ K ]. Conditioned on τ , the en tries of A are indep enden t, and A uv is a Bernoulli random v ariable with parameter P τ ( u ) ,τ ( v ) for all u 6 = v ∈ [ n ]. This gives P [ A | τ ] = Y u 6 = v P [ A uv | τ ( u ) , τ ( v )] = Y u 6 = v ( P τ ( u ) ,τ ( v ) ) A uv (1 − P τ ( u ) ,τ ( v ) ) 1 − A uv , (1) with the pro duct ov er all ordered pairs of no des. 4 The row P i · and column P · i determine the probabilities of the presence of edges inciden t to a no de in blo c k i . In order that the blo c ks be distinguishable, w e require that different blo c ks hav e distinct probabilities so that either P i · 6 = P j · or P · i 6 = P · j for all i 6 = j ∈ [ K ]. Theorem 1 sho ws that using our em b edding (Section 2.3 ) and a mean square error clustering criterion (Section 2.4 ), we are able to accurately assign no des to blo c ks, for all but a negligible n umber of nodes, for graphs distributed according to a sto chastic blo ckmodel. 2.2 Random Dot Pro duct Graphs W e present the random dot pro duct graph (RDPG) mo del to motiv ate our em b edding technique (Section 2.3 ) and provide a second parametrization for sto c hastic blo ckmodels (Section 2.5 ). Let X , Y ∈ R n × d b e such that X = [ X 1 , X 2 , . . . , X n ] T and Y = [ Y 1 , Y 2 , . . . , Y n ] T , where X u , Y u ∈ R d for all u ∈ [ n ]. The matrices X and Y are random and satisfy P [ h X u , Y v i ∈ [0 , 1]] = 1 for all u, v ∈ [ n ]. Conditioned on X and Y , the entries of the adjacency matrix A are indep enden t and A uv is a Bernoulli random v ariable with parameter h X u , Y v i for all u 6 = v ∈ [ n ]. This gives P [ A | X , Y ] = Y u 6 = v P [ A uv | X u , Y v ] = Y u 6 = v h X u , Y v i A uv (1 − h X u , Y v i ) 1 − A uv , (2) where the pro duct is ov er all ordered pairs of no des. 2.3 Em b edding The RDPG mo del motiv ates the following em b edding. By an embedding of an adjacency matrix A w e mean ( e X , e Y ) = argmin ( X † , Y † ) ∈ R n × d × R n × d k A − X † Y † T k F (3) where d , the target dimensionalit y of the em b edding, is fixed and kno wn and k · k F denotes the F robenius norm. Though e X e Y T ma y b e a p o or appro ximation of A , Theorems 1 and 12 sho w that such an embedding provides a represen- tation of the no des whic h enables clustering of the no des pro vided the random graph is distributed according to a sto chastic blo ckmodel. In fact, if a graph is distributed according to an RDPG mo del then a solution to Eqn. 3 provides an estimate of the laten t vectors given b y X and Y . W e do not explore prop erties of this estimate but instead fo cus on the sto c hastic blo c kmo del. Ec k art and Y oung ( 1936 ) provided the following solution to Eqn. 3 . Let A = e U 0 e Σ 0 e V 0 T b e the singular v alue decomp osition of A , where e U 0 , e V 0 ∈ R n × n are orthogonal and e Σ 0 ∈ R n × n is diagonal, with diagonals σ 1 ( A ) ≥ σ 2 ( A ) ≥ 5 · · · ≥ σ n ( A ) ≥ 0, the singular v alues of A . Let e U ∈ R n × d and e V ∈ R n × d b e the first d columns of e U 0 and e V 0 , resp ectiv ely , and let e Σ ∈ R d × d b e the diagonal matrix with diagonals σ 1 ( A ) , . . . , σ d ( A ). Eqn. 3 is solved by e X = e U e Σ 1 / 2 and e Y = e V e Σ 1 / 2 . W e refer to ( e X , e Y ) as the “scaled adjacency sp ectral embedding” of A . W e refer to ( e U , e V ) as the “unscaled adjacency sp ectral embedding” of A . The adjacency sp ectral embedding is similar to an embedding which is presented in Marc hette et al. ( 2011 ). It is also similar to sp ectral clustering where the decomp osition is on the normalized graph Laplacian. Theorem 1 uses a clustering of the unscaled adjacency sp ectral embedding of A while Corollary 9 extends the result to clustering on the scaled adjacency sp ectral embedding. Though this embedding is proposed for em b edding an adjacency matrix, we use the same pro cedure to embed other matrices. 2.4 Clustering Criterion W e pro ve that for a graph distributed according to the sto c hastic blockmodel, w e can use the following clustering criterion on the adjacency sp ectral embedding of A to accurately assign no des to blo c ks. Let Z ∈ R n × m . W e use the following mean square error criterion for clustering the rows of Z into K blo c ks, ( ˆ ψ , ˆ τ ) = argmin ψ ; τ n X u =1 k Z u − ψ τ ( u ) k 2 2 , (4) where ˆ ψ ∈ R K × m , ˆ ψ i ∈ R m giv es the cen troid of blo ck i and ˆ τ : [ n ] 7→ [ K ] is the blo c k assignment function. Again, note that other computationally less exp ensiv e criterion can also b e quite effective. Indeed, in Section 6.1 , w e achiev e misclassification rates which are empirically better than our theoretical bounds using the K -means clustering algorithm, which only attempts to solve Eqn. 4 . Additionally , other clustering algorithms ma y prov e useful in practice though presently we do not in vestigate these pro cedures. 2.5 Sto c hastic Blo ckmodel as RDPG Mo del W e presen t another parametrization of a stochastic blo c kmo del corresp onding to the RDPG mo del. Suppose w e ha ve a sto chastic blo c kmo del with rank( P ) = d . Then there exist ν , µ ∈ R K × d suc h that P = ν µ T and by definition P ij = h ν i , µ j i . Let τ : [ n ] 7→ [ K ] b e the random blo c k membership function. Let X ∈ R n × d and Y ∈ R n × d ha ve row u giv en b y X T u = ν T τ ( u ) and Y T u = µ T τ ( u ) , resp ectiv ely , for all u . Then we ha ve P [ A uv = 1] = P τ ( u ) ,τ ( v ) = h ν τ ( u ) , µ τ ( v ) i = h X u , Y v i . (5) In this w a y , the sto c hastic blo c kmo del can b e parametrized b y ν , µ ∈ R K × d and ρ provided that ( ν µ T ) ij ∈ [0 , 1] for all i, j ∈ [ K ]. This viewp oint prov es v aluable in the analysis and clustering of the adjacency sp ectral embedding. 6 Imp ortan tly , the distinctness of ro ws or columns in P is equiv alen t to the distinctness of the rows of ν or µ . (Indeed note, that for i 6 = j , P i · − P j · = 0 if and only if ( ν T i − ν T j ) µ = 0, but rank( µ ) = d so ν T i = ν T j . Similarly , P · i = P · j if and only if µ i = µ j .) Also note, w e can take ( ν , µ ) as the adjacency sp ectral em b edding of P with target dimensionalit y rank( P ) to get suc h a represen tation from any giv en P . 3 Main Results 3.1 Notation W e use the follo wing notation for the remainder of this paper. Let P ∈ [0 , 1] K × K and ρ ∈ (0 , 1) K b e a vector with positive en tries summing to unity . Supp ose rank( P ) = d . Let ν µ T = P with ν , µ ∈ R K × d . W e now define the following constan ts not dep ending on n : • α > 0 suc h that all eigenv alues of ν T ν and µ T µ are greater than α ; • β > 0 such that β < k ν i − ν j k or β < k µ i − µ j k for all i 6 = j ; • γ > 0 such that γ < ρ i for all i ∈ [ K ]. W e consider a sequence of random adjacency matrices A ( n ) with no de set [ n ] for n ∈ { 1 , 2 , . . . } . The edges are distributed according to a stochastic blo c kmo del with parameters P and ρ . Let τ ( n ) : [ n ] 7→ [ K ] b e the random blo c k mem b ership function, whic h induces the matrices X ( n ) , Y ( n ) ∈ R n × d as in Section 2.5 . Let n i = |{ u : τ ( u ) = i }| b e the size of blo c k i . Let XY T = UΣV be the singular v alue of decomposition, with U , V ∈ R n × d and Σ ∈ R d × d , so that ( U , V ) is the unscaled spectral embedding of the XY T . Let ( e X , e Y ) b e the adjacency spectral em b edding of A and let ( e U , e V ) b e the unscaled adjacency sp ectral embedding of A . Finally , let W ∈ R n × 2 d b e the concatenation [ U | V ] and similarly f W = [ e U | e V ]. 3.2 Main Theorem The main contribution of this pap er is the following consistency result in terms of the estimation of the block mem b erships for each node based on the blo c k assignmen t function ˆ τ whic h assigns blo c ks based on f W . In the follo wing, an ev ent o ccurs “almost alwa ys” if with probabilit y 1 the ev ent o ccurs for all but finitely many n ∈ { 1 , 2 , . . . } . Theorem 1. Under the c onditions of Se ction 3.1 , supp ose that the numb er of blo cks K and the latent ve ctor dimension d ar e known. L et ˆ τ ( n ) : V 7→ [ K ] b e the blo ck assignment function ac c or ding to a clustering of the r ows of f W ( n ) satisfying Eqn. 4 . L et S K b e the set of p ermutations on [ K ] . It almost always holds that min π ∈S K |{ u ∈ V : τ ( u ) 6 = π ( ˆ τ ( u )) }| ≤ 2 3 3 2 6 α 5 β 2 γ 5 log n. (6) 7 T o pro ve this theorem, we first pro vide a b ound on the F rob enius norm of AA T − ( XY T )( XY T ) T , following Rohe et al. ( 2011 ). Using this results and prop erties of the sto chastic blockmodel, we then find a low er b ound for the smallest non-zero singular v alue of XY T and the corresp onding singular v alue of A . This enables us to apply the Davis-Kahan Theorem ( Da vis and Kahan , 1970 ) to sho w that the unscaled adjacency sp ectral em b edding of A is approximately a rotation of the unscaled adjacency sp ectral embedding of XY T . Finally , we low er bound the distances betw een the at most K distinct ro ws of U and V . These gaps, together with the goo d approximation b y the embedding of A is sufficien t to prov e consistency of the mean square error clustering of the em b edded vectors. Most results, except the imp ortant Proposition 2 and the main theorem, are pro ved in the App endix. Prop osition 2. L et Q ( n ) ∈ [0 , 1] n × n b e a se quenc e of r andom matric es and let A ( n ) ∈ { 0 , 1 } n × n b e a se quenc e of r andom adjac ency matric es c orr esp onding to a se quenc e of r andom gr aphs on n no des for n ∈ { 1 , 2 , . . . } . Supp ose the pr ob ability of an e dge fr om no de u to no de v is given by Q ( n ) uv and that the pr esenc e of e dges ar e c onditional ly indep endent given Q ( n ) . Then the fol lowing holds almost always: k A ( n ) A ( n ) T − Q ( n ) Q ( n ) T k F ≤ √ 3 n 3 / 2 p log n. (7) Pr o of. F or ease of exp osition, we dropped the index n from Q ( n ) . Note that, conditioned on Q , A uw and A v w are independent Bernoulli random v ariables for all w ∈ [ n ] provided u 6 = v . F or each w / ∈ { u, v } , A uw A v w is a conditionally indep enden t Bernoulli with parameter Q uw Q v w . F or u 6 = v , w e hav e AA T uv − QQ T uv = X w / ∈{ u,v } ( A uw A v w − Q uw Q v w ) − Q uu Q v u − Q uv Q v v . (8) Th us, b y Ho effding’s inequality , P [( AA T uv − QQ T uv ) 2 ≥ 2( n − 2) log n + 2 n + 4 | Q ] ≤ 2 n − 4 . (9) W e can integrate ov er all c hoices of Q so that Eqn. 9 holds unconditionally . F or the diagonal en tries, ( AA T uu − QQ T uu ) 2 ≤ n 2 alw ays. The diagonal terms and the 2 n + 4 terms from equation 9 all sum to at most 3 n 3 + 4 n 2 ≤ n 3 log n for n large enough. Combining these inequalities we get the inequality P [ k AA T − QQ T k 2 F ≥ 3 n 3 log n ] ≤ 2 n − 2 . (10) Applying the Borel-Cantelli Lemma gives the result. T aking Q = XY T giv es the following imme diate corollary . 8 Corollary 3. It almost always holds that k AA T − XY T ( XY T ) T k F ≤ √ 3 n 3 / 2 p log n (11) and k A T A − ( XY T ) T XY T k F ≤ √ 3 n 3 / 2 p log n. (12) The next tw o results pro vide b ounds on the singular v alues of XY T and A based on lo wer bounds for the eigenv alues of P and the blo c k membership probabilities. Lemma 4. It almost always holds that αγ n ≤ σ d ( XY T ) and it always holds that σ d +1 ( XY T ) = 0 and σ 1 ( XY T ) ≤ n . Corollary 5. It almost always holds that αγ n ≤ σ d ( A ) and σ d +1 ( A ) ≤ 3 1 / 4 n 3 / 4 log 1 / 4 n (13) and it always holds that σ 1 ( A ) ≤ n . W e note that Corollary 5 immediately suggests a consistent estimator of the rank of XY T giv en by ˆ d = max { d 0 : σ d 0 ( A ) > 3 1 / 4 n 3 / 4 log 1 / 4 n } . Presen tly we do not inv estigate the use of this estimator and assume that the d = rank( P ) is kno wn. The follo wing is the v ersion of the Da vis-Kahan Theorem ( Da vis and Kahan , 1970 ) as stated in Rohe et al. ( 2011 ). Theorem 6 (Da vis and Kahan) . L et H , H 0 ∈ R n × n b e symmetric, supp ose S ⊂ R is an interval, and supp ose for some p ositive inte ger d that W , W 0 ∈ R n × d ar e such that the c olumns of W form an orthonormal b asis for the sum of the eigensp ac es of H asso ciate d with the eigenvalues of H in S and that the c olumns of W 0 form an orthonormal b asis for the sum of the eigensp ac es of H 0 asso ciate d with the eigenvalues of H 0 in S . L et δ b e the minimum distanc e b etwe en any eigenvalue of H in S and any eigenvalue of H not in S . Then ther e exists an ortho gonal matrix R ∈ R d × d such that k WR − W 0 k F ≤ √ 2 δ k H − H 0 k F . F or completeness, we pro vide a brief discussion of this imp ortan t result in App endix B . Applying Theorem 6 and Lemma 4 to AA T and XY T ( XY T ) T , w e ha ve the following result. Lemma 7. It almost always holds that ther e exists an ortho gonal matrix R ∈ R 2 d × 2 d such that k WR − f W k ≤ √ 2 √ 6 α 2 γ 2 q log n n . Recall that XY T = UΣV T . W e now pro vide b ounds for the gaps b et ween the at most K distinct rows of U and V . Lemma 8. It almost always holds that, for al l u, v such that X u 6 = X v , k U u − U v k ≥ β √ αγ n − 1 / 2 . Similarly, for al l Y u 6 = Y v , k V u − V v k ≥ β √ αγ n − 1 / 2 . As a r esult, k W u − W v k ≥ β √ αγ n − 1 / 2 for al l u, v such that τ ( u ) 6 = τ ( v ) . 9 W e now hav e the necessary ingredients to show our main result. Pr o of of The or em 1 . Let ˆ ψ and ˆ τ satisfy the clustering criterion for f W (where f W = [ e U | e V ] takes the role of Z in Section 2.4 ). Let C ∈ R n × 2 d ha ve ro w u giv en b y C u = ˆ ψ τ ( u ) . Then Equation 4 gives that k C − f W k F ≤ k WR − f W k F as W has at most K distinct rows. Thus, Lemma 7 gives that k C − WR k F ≤ k C − f W k F + k f W − WR k F ≤ 2 3 / 2 √ 6 α 2 γ 2 r log n n . (14) Let B 1 , B 2 , . . . , B K b e balls of radius r = β 3 √ αγ n − 1 / 2 eac h centered around the K distinct rows of W . By Lemma 8 , these balls are almost alwa ys disjoint. No w note that almost alw ays the n umber of ro ws u suc h that k C u − W u R k > r is at most 2 3 3 2 6 α 5 β 2 γ 5 log n . If this were not so then infinitely often we would hav e k C − WR k F > 2 3 3 2 6 α 5 β 2 γ 5 log n β 3 √ αγ n − 1 / 2 = 2 3 / 2 √ 6 α 2 γ 2 r log n n , (15) in contradiction to Eqn. 14 . Since n i > γ n > 2 3 3 2 6 α 5 β 2 γ 5 log n almost alw ays, each ball B i can contain exactly one of the K distinct rows of C . This gives the n umber of misclassifications as 2 3 3 2 6 α 5 β 2 γ 5 log n as desired. This gives that a clustering of the concatenation of the matrices e U and e V from the singular v alue decomp osition giv es an accurate blo ck assignmen t. One ma y also cluster the scaled singular vectors given b y e X and e Y without a change in the order of the num b er of misclassifications. 4 Extensions Corollary 9. Under the c onditions of The or em 1 , let ˆ τ : V → [ K ] b e a cluster- ing of e Z = [ e X | e Y ] . Then it almost always holds that min π ∈S K |{ u ∈ V : π ( ˆ τ ( u )) 6 = τ ( u ) }| ≤ 2 3 3 2 6 α 6 β 2 γ 6 log n. (16) The pro of relies on the fact that the square ro ot of the singular v alues are all of the same order and differ by a m ultiplicative factor of at most √ αγ . W e now present consisten t estimators of the parameters P and ρ for the sto c hastic blo c kmo del. Consider the follo wing estimates ˆ n k = |{ u : ˆ τ ( u ) = k }| , ˆ ρ k = ˆ n k n (17) 10 and ˆ P ij = 1 ˆ n i ˆ n j X ( u,v ) ∈ ˆ τ − 1 ( i ) × ˆ τ − 1 ( j ) A uv , if i 6 = j or, 1 ˆ n 2 i − ˆ n i X ( u,v ) ∈ ˆ τ − 1 ( i ) × ˆ τ − 1 ( j ) A uv , if i = j. (18) This gives the follo wing corollary . Corollary 10. Under the c onditions of The or em 1 , min π ∈S K | ρ i − ˆ ρ π ( i ) | a.s. − → 0 (19) and min π ∈S K | ˆ P π ( i ) π ( j ) − P ij | a.s. − → 0 (20) for al l i, j ∈ [ K ] as n → ∞ . The pro of is immediate from Theorem 1 and the law of large num b ers. If we tak e ( ˆ ν , ˆ µ ) to b e the adjacency sp ectral embedding of ˆ P then w e also ha ve that ˆ ν and ˆ µ pro vide consisten t estimates for ( ν , µ ), the adjacency spectral em b edding of P , in the following sense. Corollary 11. Under the c onditions of The or em 1 , with pr ob ability 1 ther e exists a se quenc e of ortho gonal matric es R ( n ) 1 , R ( n ) 2 ∈ R d × d such that k ˆ ν − ν R ( n ) 1 k F → 0 and k ˆ µ − µ R ( n ) 2 k F → 0 . (21) The pro of relies on applications of the Da vis-Kahan Theorem in a similar w ay to Lemma 7 . 5 Undirected V ersion W e now present the undirected v ersion of the sto c hastic blo ckmodel and state the main result. The setting and notation are from Section 3.1 . F or the undirected version of the sto c hastic blo c kmo del, the matrix P is symmetric and P ij = P j i giv es the probabilit y of an edge betw een a node in blo c k i and a no de in blo c k j for eac h i, j ∈ [ K ]. Conditioned on τ , A uv is a Bernoulli random v ariable with parameter P τ ( u ) ,τ ( v ) for all u 6 = v ∈ [ n ]. As A is symmetric, all en tries of A are not independent, but the en tries are independent pro vided t wo en tries do not corresp ond to the same undirected edge. F or the undirected v ersion a re-parametrization of the sto c hastic block mo del as a RDPG mo del as in Section 2.5 is not alwa ys p ossible. How ev er, we can find ν , µ ∈ R K × d suc h that ν µ T = P and ν and µ ha ve equal columns up to a p ossible change in sign in each column. This means the rows of ν and µ are distinct so it is not necessary to cluster on the concatenated embeddings. Instead, we consider clustering the rows of e U or e X , which gives a factor of tw o impro vemen t in misclassification rate. 11 Theorem 12. Under the undir e cte d version of the sto chastic blo ckmo del, sup- p ose that the numb er of blo cks K and the latent fe atur e dimension d ar e known. L et ˆ τ : V 7→ [ K ] b e a blo ck assignment function ac c or ding to a clustering of the r ows of e U satisfying the criterion in Eqn. 4 . It almost always holds that min π ∈S K |{ u ∈ V : τ ( u ) 6 = π ( ˆ τ ( u )) }| ≤ 2 2 3 2 6 α 5 β 2 γ 5 log n. (22) Corollary 9 holds when clustering on e X , with the same factor of 2 impro ve- men t in misclassification rate. Corollaries 10 and 11 also hold without change. 6 Empirical Results W e ev aluated this pro cedure and compared it to the sp ectral clustering pro ce- dure of Rohe et al. ( 2011 ) for both simulated data ( § 6.1 ) and using a Wikipedia h yp erlink graph ( § 6.2 ). 6.1 Sim ulated Data T o illustrate the effectiv eness of the adjacency sp ectral embedding, we simulate random undirected graphs generated from the following sto chastic blo c kmo del: P = 0 . 42 0 . 42 0 . 42 0 . 5 ! and ρ = ( . 6 , . 4) T (23) F or each n ∈ { 500 , 600 , . . . , 2000 } , we sim ulated 100 monte carlo replicates from this mo del conditioned on the fact that |{ u ∈ [ n ] : τ ( u ) = i }| = ρ i n for each i ∈ { 1 , 2 } . In this mo del w e assume that d = 2 and K = 2 are known. W e ev aluated four different em b edding pro cedures and for each embedding w e used K -means clustering, whic h attempts to iterativ ely find the solution to Eqn. 4 , to generate the no de assignmen t function ˆ τ . The four em b edding pro cedure are the scaled and unscaled adjacency sp ectral em b edding as well as the scaled and unscaled Laplacian sp ectral embedding. The Laplacian sp ectral em b edding uses the same spectral decomposition but w orks with the normalized Laplacian (as defined in Rohe et al. ( 2011 )) rather then the adjacency matrix. The normalized Laplacian is given by L = D − 1 / 2 AD − 1 / 2 where D ∈ R n × n is diagonal with D v v = deg( v ), the degree of no de v . W e ev aluated the p erformance of the node assignmen ts b y computing the p ercen tage of mis-assigned no des, min π ∈ S 2 |{ u ∈ [ n ] : τ ( u ) 6 = π ( ˆ τ ( u )) }| /n , as in Eqn. 6 . Figure 1 demonstrates that p erformance of K -means on all four em b eddings impro ves with increasing num b er of no des. It also demonstrates (via a paired Wilcoxon test) that for these mo del parameters the adjacency em b edding is superior to the Laplacian embeddings for large n . In fact, for n ≥ 1400 w e observ ed that for eac h sim ulated graph the scaled adjacency em b edding alw ays p erformed b etter than b oth Laplacian embeddings. W e note that these 12 400 600 800 1000 1200 1400 1600 1800 2000 n - Number of vertices 0 . 05 0 . 10 0 . 15 0 . 20 0 . 25 0 . 30 0 . 35 0 . 40 0 . 45 0 . 50 P ercent Error Adjacency (Scaled) Adjacency (Unscaled) Laplacian (Scaled) Laplacian (Unscaled) Figure 1: Mean error for 100 monte carlo replicates using K -means on four differen t em b edding pro cedures. mo del parameters w ere sp ecifically constructed to demonstrate a case where the adjacency embedding is sup erior to the Laplacian embedding. Figure 2 shows an example of the scaled adjacency (left) and scaled Lapla- cian (right) spectral embeddings. The graph has 2000 no des and the p oin ts are colored according to their blo c k membership. The dashed line shows the discriminan t b oundary giv en by the K -means algorithm with K = 2. 6.2 Wikip edia Graph F or this data, eac h no de in the graph corresp onds to a Wikip edia page and the edges corresp ond to the presence of a hyperlink b et ween tw o pages (in either direction). W e consider this as an undirected graph. Every article within t wo hyperlinks of the article “Algebraic Geometry” w as included as a no de in the graph. This resulted in n = 1382 no des. Additionally , eac h do cumen t, and hence eac h node, w as man ually labeled as one of the following: Category , P erson, Lo cation, Date and Math. T o illustrate the utilit y of this algorithm we embedded this graph using the scaled adjacency and Laplacian procedures. Figure 3 sho ws the t wo em b eddings for d = 2. The p oin ts are colored according to their man ually assigned labels. First w e note that on the whole the tw o embeddings lo ok mo derately differen t. In fact, for the adjacency embedding one can see that the orange p oin ts are w ell separated from the remaining data. On the other hand, with the Laplacian em b edding we can see that the red p oin ts are somewhat separated from the remaining data. The dashed lines sho w the result boundary as determined b y K -means with K = 2. T o ev aluate the p erformance we considered the 5 differen t tasks of iden tifying one blo c k and grouping the remaining blo c ks together. F or each of the 5 blo cks, 13 − 1 . 0 − 0 . 8 − 0 . 6 − 0 . 4 − 0 . 2 − 0 . 6 − 0 . 4 − 0 . 2 0 . 0 0 . 2 0 . 4 0 . 6 − 0 . 035 − 0 . 030 − 0 . 025 − 0 . 020 − 0 . 015 − 0 . 010 − 0 . 020 − 0 . 015 − 0 . 010 − 0 . 005 0 . 000 0 . 005 0 . 010 0 . 015 0 . 020 Figure 2: Scatter plots of the scaled adjacency (left) and Laplacian (right) em b eddings of a 2000 no de graph. w e compared eac h of the one-vs-all blo ck lab els to the estimated lab els from K -means, with K = 2, on the tw o em b eddings. T able 1 shows the num b er of incorrectly assigned nodes, as in Eqn. 6 , as well as the adjusted Rand index ( Hub ert and Arabie , 1985 ). The adjusted Rand index (ARI) has the prop erty that the optimal v alue is 1 and a v alue of zero indicates the exp ected v alue if the lab els were assigned randomly . W e can see from this table that K -means on the adjacency embedding iden- tifies the separation of the Date block from the other four while on the Laplacian em b edding K -means identifies the separation of the Math blo c k from the other four. This indicates that for this data set (and indeed more generally) the c hoice of embedding pro cedure will dep end greatly on the desired exploitation task. W e note that for b oth embeddings, the clusters generated using K -means, with K = 5, p oorly reflect the manually assigned blo c k memberships. W e hav e not inv estigated b ey ond the illustrativ e 2-dimensional embeddings. Category (119) P erson (372) Location (270) Date (191) Math (430) Error ARI Error ARI Error ARI Error ARI Error ARI A 242 -0.08 495 -0.07 341 0.01 130 0.47 543 0.06 L 299 -0.02 495 -0.02 476 -0.1 401 -0.10 350 0.19 T able 1: One versus all comparison of each block against the estimated K -means blo c k assignments with K = 2. 14 − 1 . 6 − 1 . 4 − 1 . 2 − 1 . 0 − 0 . 8 − 0 . 6 − 0 . 4 − 0 . 2 0 . 0 0 . 2 − 1 . 0 − 0 . 5 0 . 0 0 . 5 1 . 0 1 . 5 Adjacency − 0 . 02 0 . 00 0 . 02 0 . 04 0 . 06 0 . 08 0 . 10 0 . 12 − 0 . 25 − 0 . 20 − 0 . 15 − 0 . 10 − 0 . 05 0 . 00 0 . 05 0 . 10 Laplacian Figure 3: Scatter plots for the Wikipedia graph. The left pane show the scaled adjacency embedding and the right pane show the scaled Laplacian embedding. Eac h point is colored according to the man ually assigned lab els. The dashed line represents the discriminant b oundary determined b y K -means with K = 2. 7 Discussion Our simulations demonstrate that for a particular example of the sto chastic blo c kmo del, the prop ortion of mis-assigned no des will rapidly b ecome small. Though our b ound shows that the num b er of mis-assigned no des will not grow faster than O (log n ), in some instances this b ound may b e very lo ose. W e also demonstrate that using the adjacency em b edding o v er the Laplacian em b edding can pro vide p erformance impro vemen ts in some settings. It is also clear from Figure 2 that the use of other unsup ervised clustering tec hniques, such as Gaus- sian mixture mo deling, will likely lead to further p erformance impro vemen ts. On the Wikip edia graph, the t wo-dimensional em b edding demonstrates that the adjacency embedding pro cedure provides an alternativ e to the Laplacian em b edding and the t wo ma y hav e fundamentally differen t prop erties. Both the Date blo c k and the Math blo ck ha ve some differentiating structure in the graph but these structures are illuminated more in one embedding then the other. This analysis suggests that further inv estigations into comparisons b et w een the adjacency embedding and the Laplacian embeddings will b e fruitful. Our empirical analysis indicates that the adjacency spectral em b eddings and the Laplacian spectral em b eddings are strongly related while the tw o em b ed- dings ma y emphasize different asp ects of the particular graph. Rohe et al. ( 2011 ) used similar techniques to show consistency of blo ck assignment on the Lapla- cian embedding and achiev ed the same asymptotic rates of misclassification. Indeed, if one considers the em b edding given by D − 1 / 2 e X , then this embedding will b e very close to the scaled Laplacian embedding and may provide a link b et w een the tw o pro cedures. Note that consistent block assignments are possible using either the singular 15 v ectors or the scaled version of the singular vectors. The singular vectors them- selv es are essen tially a whitened v ersion of scaled singular v ectors. Since the singular vectors are orthogonal, the estimated cov ariance of ro ws of the scaled v ectors is prop ortional to the diagonal matrix given b y the singular v alues of A . This suggests that clustering using a c riterion inv ariant to co ordinate-scalings and rotations will lik ely ha ve similar asymptotic prop erties. Critical to the pro of is the b ound provided b y Prop osition 2 . Since this b ound do es not dep end on the method for generating Q , it suggests that exten- sions to this theorem are possible. One such extension is to tak e the num b er of blo c ks K = K n to go slowly to infinity . F or K n gro wing, the parameters α , β , and γ are no longer constan t in n , so we m ust imp ose conditions on these parameters. If we take d fixed and assume these parameters go to 0 slo wly , it is possible to allow K n = n for sufficiently small. Under these conditions, it can b e shown that the num b er of incorrect blo c k assignmen ts is o ( nγ ), which is negligible to blo c k sizes. Our pro of technique breaks do wn for K n = Ω( n 1 / 4 ) as Prop osition 2 no longer implies a gap in the singular v alues of A . In order to a void the mo del selection quagmire, we assumed in Theorem 1 that the n umber of blo c ks K and the latent feature dimension d are kno wn. Ho wev er, the pro of of this theorem suggests that b oth K and and d can b e estimated consisten tly . Corollary 5 , sho ws that all but d of the singular v alues of A are less than 3 1 / 4 n 3 / 4 log 1 / 4 n for n large enough. As discussed earlier, this shows that ˆ d = max { i : σ i ( A ) > 3 1 / 4 n 3 / 4 log 1 / 4 n } will b e a consistent estimator for d . Though this estimator is consisten t, the required n umber of no des for it to b ecome accurate will depend highly on the sparsity of the graph, whic h con trols the magnitude of the largest singular v alues of A . F urthermore, our bounds suggest that the num b er of no des required for this estimate to b e accurate will increase exp onen tially as the exp ected graph density decreases. Estimating K is more complicated, and w e do not present a formal metho d to do so. W e do note that the pro of shows that most of the embedded vectors are concentrated around K separated p oin ts. An appropriate cov ering of the p oin ts b y slowly v anishing balls would allow for a consistent estimate of K . More work is needed to pro vide mo del selection criteria whic h are practical to the practitioner. Note that some practitioners ma y hav e estimates or b ounds for the param- eters P and ρ , derived from some prior study . In this case, pro vided b ounds on α , β , and γ can b e determined, the pro of can b e used to derive high proba- bilit y b ounds on the num b er of no des that hav e b een assigned to the incorrect blo c k. This may also enable the practitioner to choose n to optimize some misassignmen t and cost criteria. The pro ofs ab ov e would remain v alid if the diagonals of the adjacency ma- trix are mo dified pro vided that each modification is bounded. In fact, modifying the diagonals may impro ve the em b edding to give lo wer num b ers of misassign- men ts. Marchette et al. ( 2011 ) suggests replacing the diagonal element A uu with deg( u ) / ( n − 1) for each node u ∈ [ n ]. Scheinerman and T uck er ( 2010 ) pro vided an iterative algorithm to impute the diagonal. An optimal choice the diagonal is not kno wn for general sto c hastic blo c kmo dels. 16 Another practical concern is the p ossibilit y of missing data in the observ ed graph. One example may b e that each edge in the true graph is only observed with probability p in the observed graph. Our theory will b e unaffected by this t yp e of error since the observed graph is also distributed according to a sto c hastic blo ckmodel with edge probabilities P 0 = p P . As a result, asymptotic consistency remains v alid. W e may also allow p to decrease slo wly with n and still achiev e asymptotically negligible misassignments. How ever, t ypically the finite sample p erformance will if p is small. Ov erall, the theory and results presen ted suggest that this em b edding pro- cedure is w orthy of further in vestigation. The problems estimating K and d , c ho osing betw een scaled and unscaled em b edding and b et ween the adjacency and the Laplacian will all b e considered in future work. This work is also b eing generalized to more general latent position mo dels. Finally , under the sto chastic blockmodel, our metho d will b e less computa- tionally demanding than ones which dep end on maximizing likelihoo d or mod- ularit y criterion. F ast methods to compute singular v alue decomp ositions are p ossible, esp ecially for sparse matrices. There are a plethora of metho ds for ef- ficien tly clustering p oin ts in Euclidean space. Overall, this em b edding metho d ma y b e v aluable to the practitioner to pro vide a rapid metho d to iden tify blo c ks in netw orks. A Pro ofs of T ec hnical Lemmas In this app endix, we pro ve the tec hnical results stated in Section 3.2 . Lemma 4 . It almost alwa ys holds that αγ n ≤ σ d ( XY T ) and it alw ays holds that σ d +1 ( XY T ) = 0 and σ 1 ( XY T ) ≤ n . Pr o of. Since XY T ∈ [0 , 1] n × n , the nonnegativ e matrix XY T ( XY T ) T has en- tries b ounded by n . The row sums are b ounded b y n 2 giving that σ 2 1 ( XY T ) = λ 1 ( XY T ( XY T ) T ) ≤ n 2 . Since X and Y are at most rank d , w e hav e σ d +1 ( XY ) = 0. The nonzero eigen v alues of XY T ( XY T ) T = XY T Y T X are the same as the nonzero eigen v alues of Y T YX T X . It almost alwa ys holds that n i ≥ γ n for all i so that X T X = K X i =1 n i ν i ν T i = γ n ν T ν + K X i =1 ( n i − γ n ) ν i ν T i (24) is the sum of t wo p ositive semidefinite matrices, the first of which has eigenv alues all greater then αγ n . This gives λ d ( X T X ) ≥ αγ n and similarly λ d ( Y T Y ) ≥ αγ n . This gives that Y T YX T X is the pro duct of p ositiv e definite matrices. W e then use a b ound on the smallest eigenv alues of the pro duct of tw o p ositiv e semi-definite matrices, so that λ d ( Y T YX T X ) ≥ λ d ( Y T Y ) λ d ( X T X ) ≥ ( αγ n ) 2 ( Zhang and Zhang , 2006 , Corollary 11). This establishes σ 2 d ( XY T ) ≥ ( αγ n ) 2 . 17 Corollary 5 . It almost alwa ys holds that αγ n ≤ σ d ( A ) and σ d +1 ( A ) ≤ 3 1 / 4 n 3 / 4 log 1 / 4 n and it alw ays holds that σ 1 ( A ) ≤ n . Pr o of. First, by the same arguments as Lemma 4 we ha ve σ 1 ( A ) ≤ n . By W eyl’s inequality ( Horn and Johnson , 1985 , § 6.3), we hav e that | σ 2 i ( A ) − σ 2 i ( XY T ) | = | λ i ( AA T ) − λ i ( XY T ( XY T ) T ) | ≤ k AA T − XY T ( XY T ) T k F . (25) T ogether with Corollary 3 this sho ws that σ d +1 ( A ) ≤ 3 1 / 4 n 3 / 4 log 1 / 4 n almost alw ays. Since γ < ρ i for each i , Lemma 4 can b e strengthened to show that there exists > 0, not dep enden t on n , suc h that ( αγ + ) n < σ d ( XY T ). Th us, we hav e that ( αγ + ) 2 n 2 < σ 2 d ( XY T ) so that ( αγ ) 2 n 2 ≤ σ 2 d ( A ) since √ 3 n 3 / 2 √ log n < 2 n 2 for n large enough. The singular v alue decomp osition of XY T is given b UΣV T . The next result pro vides b ounds for the gaps b et ween the at most K distinct rows of U and V . Recall that for a matrix M , row u is given M T u for all u . Lemma 8 . It almost alwa ys holds that, for all u, v suc h that X u 6 = X v , k U u − U v k ≥ β √ αγ n − 1 / 2 . Similarly , for all Y u 6 = Y v , k V u − V v k ≥ β √ αγ n − 1 / 2 . As a result, k W u − W v k ≥ β √ αγ n − 1 / 2 for all u, v suc h that τ ( u ) 6 = τ ( v ). Pr o of. Let Y T Y = ED 2 E T for E ∈ R d × d orthogonal, D ∈ R d × d diagonal. Define G = XE , G 0 = GD , and U 0 = UΣ . Let u, v b e such that X u 6 = X v . F rom Lemma 4 and its pro of, diagonals of D are almost alwa ys at least √ αγ n and the diagonals of Σ are at most n . No w, G 0 G 0 T = GD 2 G T = XED 2 E T X T = XY T YX T = UΣV T VΣU T = UΣ 2 U T = U 0 U 0 T . (26) Let e ∈ R n denote the vector with all zeros except 1 in the u th co ordinate and − 1 in the v th co ordinate. By the ab o v e we hav e k G 0 u − G 0 v k 2 = e T G 0 G 0 T e = e T U 0 U 0 T e = k U 0 u − U 0 v k 2 . Therefore w e obtain that β ≤ k X u − X v k = k G u − G v k ≤ 1 √ αγ n k G 0 u − G 0 v k = 1 √ αγ n k U 0 u − U 0 v k ≤ 1 √ αγ n n k U u − U v k , as desired. A symmetric argumen t holds for k V u − V v k . F or k W u − W v k note that if τ ( u ) 6 = τ ( v ) then either U u 6 = U v or V u 6 = V v . Lemma 7 . It almost alwa ys holds that there exists an orthogonal matrix R ∈ R 2 d × 2 d suc h that k WR − f W k ≤ √ 2 √ 6 α 2 γ 2 q log n n . Pr o of. Let S = ( 1 2 α 2 γ 2 n 2 , ∞ ). By Lemma 4 and Corollary 5 , it almost alwa ys holds that exactly d eigenv alues of AA T and XY T ( XY T ) T are in S . Addition- ally , Lemma 4 shows that the gap δ > α 2 γ 2 n 2 . T ogether with Corollary 3 , we ha ve that √ 2 k AA T − XY T ( XY T ) T k F δ ≤ √ 2 √ 3 n 3 / 2 √ log n α 2 γ 2 n 2 . (27) 18 This shows there exists an R 1 ∈ R d × d suc h that k UR 1 − e U k F ≤ √ 6 α 2 γ 2 q log n n . No w note that all of the abov e could be repeated for A T A and ( XY T ) T XY T , to find R 2 ∈ R d × d suc h that k VR 2 − e V k F ≤ √ 6 α 2 γ 2 q log n n . T aking R as the direct sum of R 1 and R 2 giv es the result. B Da vis-Kahan Theorem W e now state and pro vide a brief discussion of the Davis-Kahan theorem ( Da vis and Kahan , 1970 ; Rohe et al. , 2011 ). First, w e consider some general results from the theory of Grassmann spaces ( Qi et al. , 2005 ). Let G d,n denote the set of d -dimensional subspaces of R n . Two imp ortan t metrics on G d,n are the gap metric d g and the Hausdorff metric d h whic h are defined as follows. F or all W , W 0 ∈ G d,n , d g ( W , W 0 ) = v u u t d X i =1 sin 2 θ i ( W , W 0 ) (28) d h ( W , W 0 ) = v u u t d X i =1 2 sin θ i ( W , W 0 ) 2 2 (29) where θ 1 ( W , W 0 ), θ 2 ( W , W 0 ), . . . θ d ( W , W 0 ) denote the princip al angles b et ween W and W 0 . By simple trigonometry d h ( W , W 0 ) ≤ √ 2 · d g ( W , W 0 ). Supp ose W , W 0 ∈ R n,d ha ve columns which are orthonormal bases for W and W 0 , re- sp ectiv ely . It is w ell kno wn that d h ( W , W 0 ) = min R k WR − W 0 k F where the minim um is ov er all orthogonal matrices R ∈ R d × d . The next theorem states the original form of the theorem from Davis and Kahan ( 1970 ) follow ed by the version pro ved in Rohe et al. ( 2011 ). Theorem 6 (Davis and Kahan) . Let H , H 0 ∈ R n × n b e symmetric, supp ose S ⊂ R is an in terv al, and supp ose for some p ositiv e integer d that W ∈ G d,n is the sum of the eigenspaces of H associated with the eigenv alues of H in S , and that W 0 ∈ G d,n is the sum of the eigenspaces of H 0 asso ciated with the eigen v alues of H 0 in S . If δ is the minimum distance b et ween any eigen v alue of H in S and any eigenv alue of H not in S then δ · d g ( W , W 0 ) ≤ k H − H 0 k F . F urthermore, supp ose W , W 0 ∈ R n × d are such that the columns of W form an orthonormal basis for W and that the columns W 0 form an orthonormal basis for W 0 . Then there exists an orthogonal matrix R ∈ R d × d suc h that k WR − W 0 k F ≤ √ 2 δ k H − H 0 k F . F rom the preceding analysis we see that the version from Rohe et al. ( 2011 ) follo ws from the original theorem; indeed, we hav e for some orthogonal R ∈ R d × d that k WR − R 0 k F = d h ( W , W 0 ) ≤ √ 2 d g ( W , W 0 ) ≤ √ 2 δ k H − H 0 k F . 19 References E. M. Airoldi, D. M. Blei, S. E. Fienberg, and E. P . Xing. Mixed membership sto c hastic blo c kmo dels. The Journal of Machine L e arning R ese ar ch , 9:1981– 2014, 2008. 2 P . J. Bick el and A. Chen. A nonparametric view of netw ork models and Newman-Girv an and other modularities. Pr o c e e dings of the National A c ademy of Scienc es of the Unite d States of A meric a , 106:21068–21073, 2009. 3 D. S. Choi, P . J. W olfe, and E. M. Airoldi. Sto c hastic blo c kmo dels with gro wing n umber of classes. Biometrika , In press. 3 A. Condon and R. M. Karp. Algorithms for graph partitioning on the planted partition mo del. R andom Structur es and Algorithms , 18:116–140, 2001. 3 C. Da vis and W. Kahan. The rotation of eigenv ectors b y a pertubation. I II. Siam Journal on Numeric al Analysis , 7:1–46, 1970. 8 , 9 , 19 C. Eck art and G. Y oung. The approximation of one matrix by another of lo wer rank. Psychometika , 1:211–218, 1936. 5 P . Fjallstrom. Algorithms for graph partitioning: A survey. Computer and Information Scienc e , 3(10), 1998. 2 S. F ortunato. Communit y detection in graphs. Physics R ep orts , 486:75–174, 2010. 2 A. Goldenberg, A. X. Zheng, S. E. Fien b erg, and E. M. Airoldi. A survey of statistical netw ork mo dels. F oundations and T r ends in Machine L e arning , 2, 2010. 2 M. S. Handco c k, A. E. Raftery , and J. M. T antrum. Mo del-based clustering for so cial netw orks. Journal of the R oyal Statistic al So ciety: Series A (Statistics in So ciety) , 170:301–354, 2007. 2 P . Hoff, A. E. Raftery , and M. S. Handco ck. Laten t space approaches to so cial net work analysis. Journal of the A meric an Statistic al Asso ciation , 97:1090– 1098, 2002. 2 P . W. Holland, K. Laskey , and S. Leinhardt. Sto c hastic blo c kmo dels: First steps. So cial Networks , 5:109–137, 1983. 2 , 4 R. Horn and C. Johnson. Matrix A nalysis . Cam bridge Universit y Press, 1985. 18 L. Hub ert and P . Arabie. Comparing partitions. Journal of Classific ation , 2: 193–218, 1985. 14 D. J. Marchette, C. E. Prieb e, and G. Copp ersmith. V ertex nomination via attributed random dot product graphs. In Pr o c e e dings of the 57th ISI World Statistics Congr ess , 2011. 6 , 16 20 F. McSherry . Spectral partitioning of random graphs. In Pr o c e e dings of the 42nd IEEE symp osium on F oundations of Computer Scienc e , pages 529–537. IEEE Computer So ciety , 2001. 3 M. Newman and M. Girv an. Finding and ev aluating communit y structure in net works. Physic al R eview , 69:1–15, 2004. 3 K. No wicki and T. A. B. Snijders. Estimation and Prediction for Sto c hastic Blo c kstructures. Journal of the A meric an Statistic al Asso ciation , 96:1077– 1087, 2001. 2 L. Qi, Y. Zhang, and C.-K Li. Unitarily Inv ariant Metrics on the Grassmann Space. SIAM Journal on Matrix Analysis and Applic ations , 27:507–531, 2005. 19 K. Rohe, S. Chatterjee, and B. Y u. Sp ectral clustering and the high-dimensional sto c hastic blo c kmo del. Annals of Statistics , 39:1878–1915, 2011. 3 , 8 , 9 , 12 , 15 , 19 E. Scheinerman and K. T uc ker. Mo deling graphs using dot pro duct represen ta- tions. Computational Statistics , 25:1–16, 2010. 16 T. Snijders and K. No wic ki. Estimation and prediction for sto cc hastic blo c k mo dels for graphs with latent blo c k structure. Journal of Classific ation , 14: 75–100, 1997. 2 , 3 Y. J. W ang and G. Y. W ong. Sto chastic Blo c kmo dels for Directed Graphs. Journal of the Americ an Statistic al Asso ciation , 82:8–19, 1987. 2 , 4 S. Y oung and E. Scheinerman. Random dot pro duct models for so cial netw orks. In Pr o c e e dings of the 5th international c onfer enc e on algorithms and mo dels for the web-gr aph , pages 138–149, 2007. 2 F. Zhang and Q. Zhang. Eigen v alue inequalities for matrix pro duct. Automatic Contr ol, IEEE T r ansactions on , 51:1506–1509, 2006. 17 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment