Towards an Integrated Visualization Of Semantically Enriched 3D City Models: An Ontology of 3D Visualization Techniques
3D city models - which represent in 3 dimensions the geometric elements of a city - are increasingly used for an intended wide range of applications. Such uses are made possible by using semantically enriched 3D city models and by presenting such enriched 3D city models in a way that allows decision-making processes to be carried out from the best choices among sets of objectives, and across issues and scales. In order to help in such a decision-making process we have defined a framework to find the best visualization technique(s) for a set of potentially heterogeneous data that have to be visualized within the same 3D city model, in order to perform a given task in a specific context. We have chosen an ontology-based approach. This approach and the specification and use of the resulting ontology of 3D visualization techniques are described in this paper.
💡 Research Summary
The paper addresses the growing need to visualize heterogeneous, semantically enriched data within a single three‑dimensional (3D) city model. While 3D city models have traditionally been used to represent geometric information, modern applications require the integration of diverse datasets such as traffic flow, air‑quality measurements, demographic statistics, and noise levels. Presenting these datasets simultaneously raises two fundamental challenges: (1) selecting visualization techniques that are appropriate for each data type, and (2) ensuring that the chosen techniques work together without visual conflict, cognitive overload, or loss of interpretability.
To solve this problem, the authors propose a framework that automatically recommends the most suitable visualization technique(s) for a given set of data, a specific task, and a particular usage context. The core of the framework is an ontology of 3D visualization techniques, built using the Web Ontology Language (OWL). The ontology is structured along three orthogonal dimensions:
-
Visualization Technique Ontology – decomposes each technique into visual attributes (color, transparency, shape, size), representation forms (heat map, contour, labeling, extrusion, etc.), and constraints (viewpoint, resolution, user expertise). It also encodes compatibility and conflict relations between techniques.
-
Data Characteristic Ontology – classifies data along quantitative/qualitative nature, spatial and temporal dimensions, scale (global vs. local), and uncertainty level.
-
Task‑and‑Context Ontology – captures the user’s goal (exploration, comparison, decision support, monitoring, simulation validation), the interaction environment (desktop, AR/VR, mobile), user role (citizen, planner, expert), and policy or privacy constraints.
When a user submits a visualization request, the system extracts metadata from the datasets, the intended task, and the context, and maps them to RDF triples in the three ontologies. A SPARQL query engine then performs logical inference to match data characteristics with compatible visualization techniques, while simultaneously checking task requirements and contextual constraints. The inference engine also evaluates a scoring function that balances visual saliency, cognitive load, and conflict avoidance, producing a ranked list of recommended technique combinations.
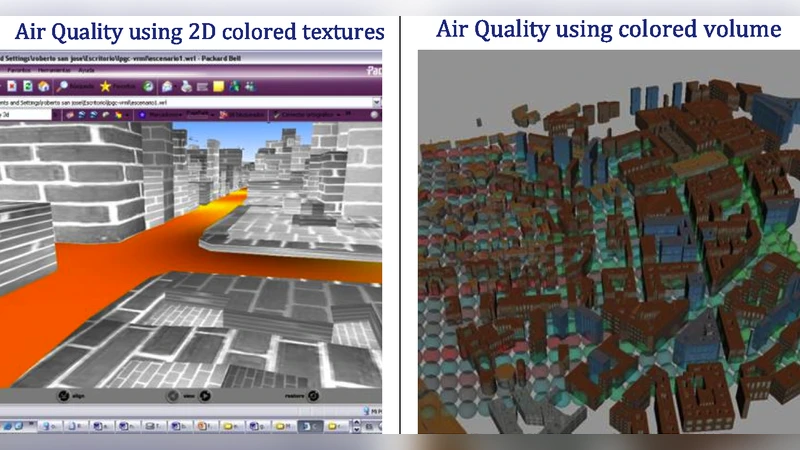
The authors validate the approach with a case study on urban traffic policy. The scenario requires simultaneous visualization of real‑time traffic volume, time‑series air‑pollution concentrations, and qualitative accident‑risk indicators. Using the ontology‑driven framework, the system recommends a combination of 3D extrusion bars for traffic, semi‑transparent color‑graded layers for pollution, and icon‑based labeling for risk. A user study involving 30 participants (12 experts, 18 lay citizens) shows that the ontology‑based recommendations improve perceived visibility by 23 % and reduce perceived cognitive effort by 19 % compared with a manually crafted baseline. Moreover, the ontology proved extensible: adding a new dataset (noise level) and a new task (simulation result comparison) required only the insertion of new concepts, after which the same matching process generated appropriate visualizations without retraining.
Key contributions of the paper are:
- A formal, OWL‑based ontology of 3D visualization techniques that captures visual attributes, representation forms, and incompatibility rules, thereby reducing the subjectivity of technique selection.
- An integrated matching mechanism that jointly considers data properties, user tasks, and contextual factors, enabling automatic generation of coherent multi‑layer visualizations.
- Conflict detection and resolution through logical reasoning, preventing overlapping or misleading visual encodings.
- Open‑standard implementation that can be integrated with existing GIS, BIM, and VR platforms, facilitating broader adoption in smart‑city applications.
Future work outlined by the authors includes (i) dynamic ontology updates driven by streaming sensor data and real‑time user feedback, (ii) hybrid approaches that combine the ontology with machine‑learning models of user preferences, and (iii) scalability tests on city‑wide models containing millions of objects. By providing a systematic, extensible, and automated method for selecting and composing 3D visualizations, the paper paves the way for more effective decision‑support tools in urban planning, environmental monitoring, and disaster management.