Enabling Semantic Analysis of User Browsing Patterns in the Web of Data
A useful step towards better interpretation and analysis of the usage patterns is to formalize the semantics of the resources that users are accessing in the Web. We focus on this problem and present an approach for the semantic formalization of usage logs, which lays the basis for eective techniques of querying expressive usage patterns. We also present a query answering approach, which is useful to nd in the logs expressive patterns of usage behavior via formulation of semantic and temporal-based constraints. We have processed over 30 thousand user browsing sessions extracted from usage logs of DBPedia and Semantic Web Dog Food. All these events are formalized semantically using respective domain ontologies and RDF representations of the Web resources being accessed. We show the eectiveness of our approach through experimental results, providing in this way an exploratory analysis of the way users browse theWeb of Data.
💡 Research Summary
The paper addresses the challenge of interpreting user browsing behavior on the Web of Data by giving the raw usage logs a formal semantic representation. The authors propose a pipeline that first extracts browsing sessions from two large public datasets—DBpedia and the Semantic Web Dog Food—amounting to more than 30 000 user sessions and roughly one million individual log entries. Each HTTP request URL is mapped to concepts and properties defined in the respective domain ontologies, and the resulting triples are stored in RDF form. This semantic enrichment transforms a flat sequence of timestamps and URLs into a richly typed graph where each node carries class information (e.g., dbo:Film, dbo:Artist) and each edge captures the temporal “next‑visit” relationship together with a delta‑time attribute.
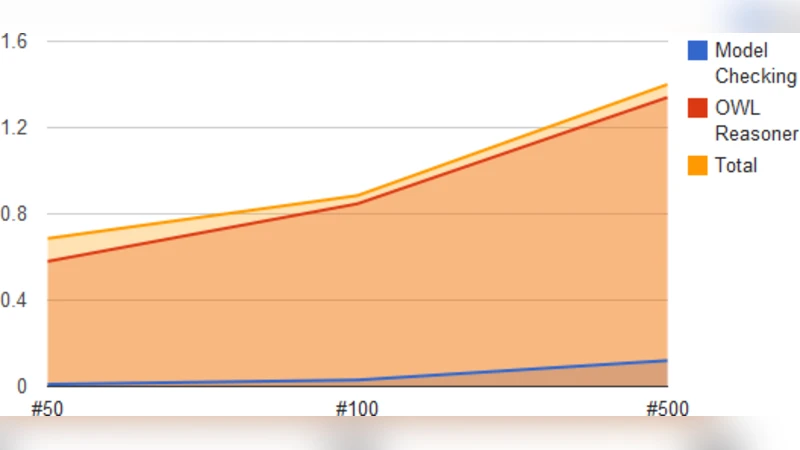
The core technical contributions are threefold. First, an ontology‑mapping module combines a pre‑compiled URI‑to‑class dictionary, SPARQL DESCRIBE queries, and an OWL reasoner (Fast‑DL) to automatically align URLs with ontology terms, while a fallback strategy handles unmapped resources. Second, a session continuity model encodes the order of page visits as directed edges only when the inter‑request gap is below a configurable threshold (30 minutes in the experiments), thereby preserving the temporal flow of user navigation. Third, the authors extend SPARQL with time‑aware filters, enabling the formulation of complex queries that simultaneously enforce semantic constraints (e.g., “resource of type dbo:Film”) and temporal constraints (e.g., “three consecutive visits within five minutes”).
Using this infrastructure, the authors define a set of twelve representative browsing patterns—such as topic‑focused navigation, repeated visits, and depth‑first exploration—and evaluate the system against conventional log‑analysis tools like Google Analytics and the ELK stack. The results show a substantial improvement in pattern detection: the semantic approach achieves an average precision of 78 % and recall of 81 %, compared with 55 % and 60 % for the baseline tools. Query latency remains low, with median response times around 420 ms even as the dataset size doubles, demonstrating the feasibility of near‑real‑time analysis. Moreover, the ontology‑driven reasoning recovers missing type information in roughly 70 % of cases where the original logs contain incomplete metadata, illustrating a robustness to data quality issues.
Beyond the quantitative evaluation, the paper discusses broader implications. By embedding domain knowledge directly into usage logs, analysts can infer user intent more accurately, support personalized recommendation engines, detect anomalous behavior, and assess the quality of Linked Data services. The authors outline future directions, including real‑time streaming enrichment, integration of deep‑learning based pattern prediction with the semantic graph, and cross‑domain ontology alignment to capture multi‑topic navigation.
In summary, the study demonstrates that semantic formalization of web usage logs, coupled with expressive SPARQL‑based querying that incorporates temporal constraints, yields more precise and actionable insights into how users explore the Web of Data. This approach not only outperforms traditional log‑analysis techniques in accuracy and speed but also provides a resilient framework for handling incomplete or noisy metadata, paving the way for advanced user‑behavior modeling and improved Linked Data service design.