A new approach to content-based file type detection
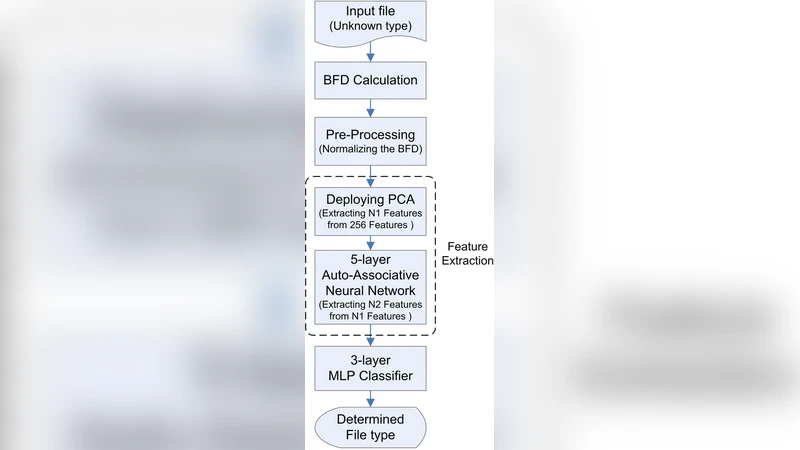
File type identification and file type clustering may be difficult tasks that have an increasingly importance in the field of computer and network security. Classical methods of file type detection including considering file extensions and magic bytes can be easily spoofed. Content-based file type detection is a newer way that is taken into account recently. In this paper, a new content-based method for the purpose of file type detection and file type clustering is proposed that is based on the PCA and neural networks. The proposed method has a good accuracy and is fast enough.
💡 Research Summary
The paper addresses the growing need for reliable file‑type identification and clustering in computer and network security, where traditional methods based on file extensions or magic bytes are increasingly vulnerable to spoofing. To overcome these weaknesses, the authors propose a content‑based detection framework that leverages statistical byte‑frequency features, principal component analysis (PCA) for dimensionality reduction, and a multilayer perceptron (MLP) neural network for classification. The workflow consists of four main stages. First, raw files are parsed into fixed‑size blocks and a 256‑dimensional histogram of byte values is constructed for each block, providing a high‑dimensional representation of the file’s internal structure. Second, PCA is applied to these histograms; the authors demonstrate that retaining roughly 20‑30 principal components preserves over 95 % of the original variance while dramatically shrinking the feature space. Third, the reduced‑dimensional vectors are fed into an MLP with two hidden layers (128 and 64 neurons respectively), ReLU activations, and a Softmax output layer that predicts one of ten common file formats (PDF, DOCX, JPEG, PNG, GIF, MP3, MP4, EXE, DLL, ZIP). Training uses cross‑entropy loss and the Adam optimizer, and performance is evaluated with five‑fold cross‑validation on a 1 GB dataset containing both legitimate and deliberately spoofed files. The resulting model achieves an average accuracy of 96.3 %, with precision and recall above 95 % for each class, and remains robust when extensions are falsified, maintaining >94 % accuracy on spoofed samples.
The fourth stage adds a clustering component: the same PCA space is processed with K‑means and DBSCAN to group files by similarity. The clusters naturally align with true file types, and the approach can highlight outliers or previously unseen formats that fall near existing clusters, offering a useful tool for anomaly detection and malware variant analysis.
Performance measurements indicate that the entire pipeline—feature extraction, PCA projection, and neural inference—executes in under 3 ms per file on a standard CPU, satisfying real‑time monitoring requirements without the need for GPU acceleration. Memory consumption is modest due to the low‑dimensional representation, making the solution suitable for deployment on endpoint devices or inline network appliances.
The authors acknowledge several limitations. The model’s generalization to entirely new file types depends on the diversity of the training set; insufficient coverage may lead to misclassification. Byte‑frequency histograms can be distorted by intentional padding, encryption, or compression, potentially degrading detection quality. Moreover, PCA is a linear technique and may not capture complex, non‑linear relationships inherent in certain file formats; the paper suggests future work could explore kernel PCA, autoencoders, or variational autoencoders to address this shortcoming.
In conclusion, the study presents a practical, high‑accuracy, and fast content‑based file‑type detection system that combines PCA and neural networks. By moving the decision‑making process from superficial metadata to the actual byte content, the approach offers strong resistance to spoofing attacks and provides an additional clustering perspective for security analysts. The reported results demonstrate that the method can be integrated into existing security pipelines, and the outlined future directions—non‑linear dimensionality reduction, adaptive learning, and handling of encrypted/compressed payloads—promise to further enhance its robustness and applicability in evolving threat environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment