BAMBI: blind accelerated multimodal Bayesian inference
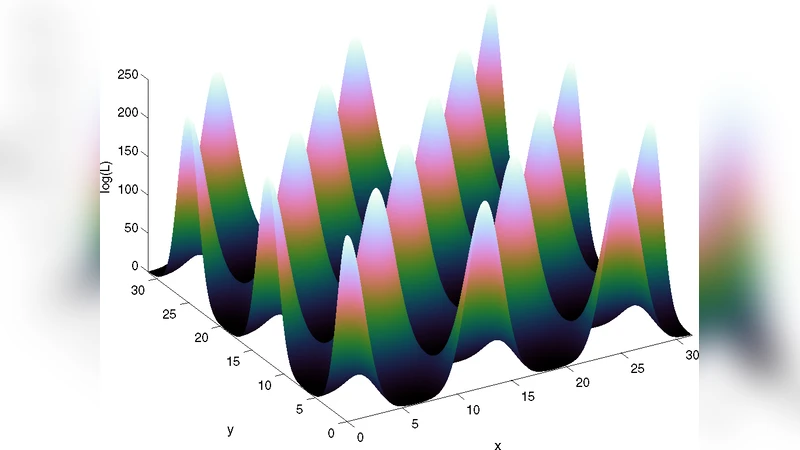
In this paper we present an algorithm for rapid Bayesian analysis that combines the benefits of nested sampling and artificial neural networks. The blind accelerated multimodal Bayesian inference (BAMBI) algorithm implements the MultiNest package for nested sampling as well as the training of an artificial neural network (NN) to learn the likelihood function. In the case of computationally expensive likelihoods, this allows the substitution of a much more rapid approximation in order to increase significantly the speed of the analysis. We begin by demonstrating, with a few toy examples, the ability of a NN to learn complicated likelihood surfaces. BAMBI’s ability to decrease running time for Bayesian inference is then demonstrated in the context of estimating cosmological parameters from Wilkinson Microwave Anisotropy Probe and other observations. We show that valuable speed increases are achieved in addition to obtaining NNs trained on the likelihood functions for the different model and data combinations. These NNs can then be used for an even faster follow-up analysis using the same likelihood and different priors. This is a fully general algorithm that can be applied, without any pre-processing, to other problems with computationally expensive likelihood functions.
💡 Research Summary
The paper introduces BAMBI (Blind Accelerated Multimodal Bayesian Inference), a hybrid algorithm that couples the MultiNest implementation of nested sampling with an artificial neural network (ANN) trained to approximate the likelihood function. The motivation stems from the fact that, in many cosmological and particle‑physics problems, evaluating the likelihood can take several seconds per point, making traditional MCMC or even nested‑sampling approaches computationally expensive when millions of likelihood calls are required.
BAMBI works in two alternating phases. First, MultiNest explores the parameter space as usual, generating a set of “live” points. After a user‑specified number of new points have been accepted, these points (parameter vectors together with their log‑likelihood values) are split into a training set (≈80 %) and a validation set (≈20 %). A three‑layer feed‑forward network (input layer, one hidden layer with tanh activation, linear output) is then trained to map parameters to log‑likelihood. The training follows a Bayesian regularisation scheme: weights have a Gaussian prior with precision α, and the output noise σ is treated as a hyper‑parameter. An initial α is set proportional to the gradient magnitude of the log‑likelihood, and the optimisation proceeds via conjugate‑gradient steps that incorporate a Hessian‑free second‑order approximation (Newton‑like update). After convergence, the validation error is compared against a user‑defined tolerance. If the network meets the tolerance, its predictions replace the true likelihood for all subsequent MultiNest proposals, reducing the evaluation time from seconds to milliseconds.
If the validation error exceeds the tolerance, MultiNest continues sampling with the true likelihood until enough additional points have been gathered, at which point the network is retrained. This dynamic retraining loop ensures that the ANN remains accurate even when the likelihood surface is highly multimodal or exhibits strong degeneracies.
The authors demonstrate the method on several toy problems (egg‑box, Gaussian shells, ring‑shaped likelihoods) that are deliberately multimodal and have curved degeneracies. In these tests BAMBI reproduces the posterior distributions and evidence values of the original MultiNest runs with negligible bias while achieving speed‑ups of roughly 5–8×.
The main scientific application presented is the estimation of cosmological parameters using WMAP‑7 data combined with BAO and supernova measurements. The likelihood for this problem involves computing theoretical CMB power spectra, which is computationally intensive. By training an ANN on the log‑likelihood values obtained during the early phase of the run, BAMBI reduces the total wall‑clock time by a factor of about six compared with a pure MultiNest analysis, without compromising the precision of the recovered parameters or the Bayesian evidence.
A further advantage highlighted is the reusability of the trained network. Once an ANN has learned the likelihood for a given model and data set, it can be employed in subsequent analyses that use different priors or explore extensions of the model, eliminating the need for additional expensive likelihood evaluations.
Key technical contributions include:
-
Bayesian regularisation of network weights – the use of a Gaussian prior on weights (α) and an explicit noise hyper‑parameter (σ) provides a principled way to avoid over‑fitting while allowing the network to adapt to the scale of the likelihood surface.
-
Second‑order optimisation – by approximating the Hessian through conjugate‑gradient steps, the training converges faster than standard stochastic gradient descent, which is crucial when the training set is relatively small (a few thousand points).
-
Dynamic retraining strategy – the algorithm automatically decides when the ANN is no longer trustworthy and triggers a new training phase, ensuring robustness across a wide range of likelihood complexities.
-
Compatibility with MultiNest’s ellipsoidal sampling – because the ANN only replaces the likelihood evaluation, the sophisticated ellipsoidal clustering and multimodal handling of MultiNest remain fully operational.
Limitations discussed by the authors include the difficulty of approximating likelihoods that contain sharp discontinuities or highly non‑smooth features, the need for user‑chosen hyper‑parameters such as the number of hidden nodes and the validation tolerance, and the increased memory footprint required to store the live points used for training.
In conclusion, BAMBI offers a practical and generally applicable framework for accelerating Bayesian inference in problems where likelihood evaluations dominate the computational cost. By integrating a well‑trained neural surrogate into the nested‑sampling workflow, it achieves substantial speed‑ups while preserving the accuracy of posterior estimates and evidence calculations. The method is especially promising for large‑scale cosmological analyses, particle‑physics parameter scans, and any other domain where expensive forward models are coupled with Bayesian inference. Future work could focus on automated hyper‑parameter optimisation, handling of non‑smooth likelihoods, and scaling to even higher‑dimensional problems.
Comments & Academic Discussion
Loading comments...
Leave a Comment