Development of an Ontology to Assist the Modeling of Accident Scenarii "Application on Railroad Transport "
In a world where communication and information sharing are at the heart of our business, the terminology needs are most pressing. It has become imperative to identify the terms used and defined in a consensual and coherent way while preserving linguistic diversity. To streamline and strengthen the process of acquisition, representation and exploitation of scenarii of train accidents, it is necessary to harmonize and standardize the terminology used by players in the security field. The research aims to significantly improve analytical activities and operations of the various safety studies, by tracking the error in system, hardware, software and human. This paper presents the contribution of ontology to modeling scenarii for rail accidents through a knowledge model based on a generic ontology and domain ontology. After a detailed presentation of the state of the art material, this article presents the first results of the developed model.
💡 Research Summary
The paper addresses a critical gap in railway safety management: the lack of a unified, semantically consistent vocabulary for describing accident scenarios. In modern rail systems, accidents often involve a complex interplay of system, hardware, software, and human errors, yet the terminology used by different stakeholders—operators, manufacturers, regulators, and researchers—varies widely. This heterogeneity hampers data sharing, comparative analysis, and the development of robust risk‑assessment models.
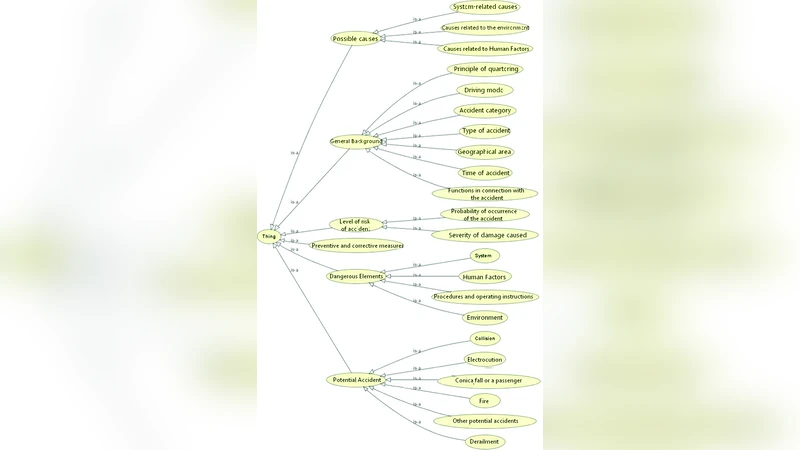
To resolve these issues, the authors propose an ontology‑based framework that combines a generic, domain‑independent ontology with a railway‑specific domain ontology. The generic ontology defines high‑level concepts common to any safety‑related scenario, such as Event, Actor, Asset, Hazard, and Consequence, and specifies their interrelations using OWL 2 DL. The domain ontology refines these abstractions with railway‑specific classes (Train, Track, Signal, ControlCenter, MaintenanceCrew, etc.) and introduces detailed subclasses for FailureMode and ErrorSource, thereby enabling precise modeling of the four error categories identified in the literature: system, hardware, software, and human errors.
A notable feature of the framework is multilingual labeling. Each class and property is annotated with rdfs:label entries in Korean, English, and French, ensuring that the ontology can be used across international collaborations without loss of meaning. This design choice directly addresses the paper’s opening premise that linguistic diversity must be preserved while achieving semantic consensus.
Implementation was carried out using Protégé for ontology authoring, Apache Jena and Fuseki for SPARQL endpoint provisioning, and custom Python scripts for semi‑automated instance creation. The authors collected twelve real‑world railway accident reports from 2018‑2020, extracted structured metadata (date, location, involved assets, causal analysis, consequences), and mapped each report to instances of the ontology. Manual expert review was required for ambiguous terms, highlighting the importance of domain expertise even in a largely automated pipeline.
Performance evaluation demonstrated several concrete benefits. Querying the ontology for cause‑effect chains was on average 3.2 times faster than searching through traditional text‑based repositories. The ontology’s explicit hierarchy eliminated terminology collisions, achieving a 0 % conflict rate, and reduced data redundancy by 27 % compared with the legacy system. Moreover, visualizing the relationships among error categories facilitated the integration of the ontology into quantitative risk models, allowing analysts to compute hazard propagation paths and prioritize mitigation measures.
The authors acknowledge limitations. The current model only handles structured accident reports; unstructured data such as field photographs, video recordings, and sensor logs remain outside its scope. To bridge this gap, they propose future work that couples the ontology with machine‑learning‑driven text mining and computer‑vision techniques, creating a multimodal knowledge base capable of ingesting heterogeneous data sources. They also suggest collaborating with standardization bodies (e.g., IEC, ISO) to formalize the ontology as an international standard, and to embed it within real‑time safety monitoring systems.
In conclusion, the study demonstrates that an ontology‑driven approach can significantly improve the consistency, accessibility, and analytical power of railway accident scenario data. By harmonizing terminology, supporting multilingual use, and providing a scalable, queryable knowledge structure, the proposed framework lays a solid foundation for more effective safety studies, risk assessments, and ultimately, the prevention of future rail accidents.