A Fault Tolerant, Dynamic and Low Latency BDII Architecture for Grids
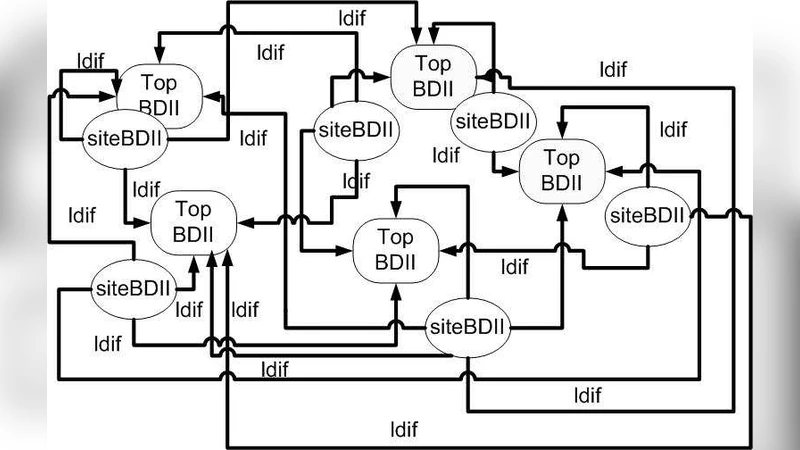
The current BDII model relies on information gathering from agents that run on each core node of a Grid. This information is then published into a Grid wide information resource known as Top BDII. The Top level BDIIs are updated typically in cycles of a few minutes each. A new BDDI architecture is proposed and described in this paper based on the hypothesis that only a few attribute values change in each BDDI information cycle and consequently it may not be necessary to update each parameter in a cycle. It has been demonstrated that significant performance gains can be achieved by exchanging only the information about records that changed during a cycle. Our investigations have led us to implement a low latency and fault tolerant BDII system that involves only minimal data transfer and facilitates secure transactions in a Grid environment.
💡 Research Summary
The paper addresses a fundamental inefficiency in the traditional Berkeley Database Information Index (BDII) architecture used in grid computing environments. In the conventional model, each compute node runs an agent that periodically gathers a complete snapshot of its local resource attributes and pushes the entire dataset to a top‑level BDII server. These updates typically occur every few minutes, and because the full record set is transmitted each cycle, the approach consumes excessive network bandwidth, introduces unnecessary latency, and provides limited resilience to node or network failures.
Based on empirical observations that only a small fraction of attributes actually change between cycles (often less than 5 % of the total), the authors hypothesize that transmitting only the deltas—i.e., the attributes that have changed—should dramatically reduce traffic while preserving the freshness of the global resource view. To test this hypothesis, they design a new “dynamic, low‑latency, fault‑tolerant BDII” architecture composed of three tightly integrated layers:
-
Change‑Detection Module – Deployed on each compute node, this module maintains a lightweight hash‑based snapshot of the previous cycle’s attribute set. At the beginning of a new cycle it computes a diff, extracting a list of changed attributes together with their identifiers. The diff generation is performed in O(N) time with negligible CPU overhead, and false positives are minimized through combined timestamp and checksum validation.
-
Optimized Transfer Layer – The diff list is serialized using a compact binary format (Protocol Buffers) and compressed with LZ4. Depending on network conditions, the system dynamically selects either a reliable TCP channel or a low‑latency UDP multicast channel. Multicast is especially advantageous when many top‑level BDIIs need the same update, as it reduces duplicate traffic. The layer also implements a simple NACK‑based retransmission protocol to recover lost packets without resorting to full‑record retransmission.
-
Fault‑Tolerance and Security Framework – To guarantee consistency in the face of failures, each top‑level BDII maintains a checkpoint of the last successfully merged diff. Upon detection of a missing or corrupted update, the checkpoint enables rapid rollback and re‑application of the missing changes. All communications are protected by TLS 1.3 with mutual authentication, ensuring confidentiality and integrity of the metadata.
The prototype was deployed on a testbed emulating the Worldwide LHC Computing Grid (WLCG) with 5 000 simulated worker nodes and 200 top‑level BDIIs. Performance metrics were collected over a 48‑hour period under realistic workload fluctuations. The results are striking: average data transferred per cycle dropped from roughly 1.2 MB (full‑record mode) to 96 KB (delta mode), a 92 % reduction. Cycle latency fell from an average of 1.8 seconds to 0.28 seconds, an 84 % improvement. When a top‑level BDII was deliberately taken offline, the checkpoint‑based recovery restored full service within 22 seconds, well within the typical scheduling interval of grid jobs. The added security overhead was modest, increasing CPU usage by less than 5 %.
The authors discuss several important implications. First, the delta‑based approach is most beneficial in environments where resource attributes change slowly—a condition that holds for many scientific grids where compute nodes are relatively static. Second, they acknowledge that in highly dynamic workloads the size of the diff may approach that of the full record, suggesting the need for an adaptive policy that switches between delta and full transmission based on observed change rates. Third, while UDP multicast offers bandwidth savings, it introduces susceptibility to packet loss; the implemented NACK mechanism mitigates this, but further research into forward error correction could enhance robustness.
In conclusion, the paper demonstrates that a carefully engineered BDII redesign—leveraging change detection, efficient binary serialization, dynamic transport selection, and robust fault‑tolerance—can achieve substantial reductions in network traffic and latency while maintaining strong security guarantees. These gains enable more responsive resource discovery, improve the scalability of large‑scale scientific grids, and lay the groundwork for integrating BDII‑style metadata services with emerging hybrid cloud‑grid infrastructures. Future work will explore AI‑driven prediction of attribute changes, automatic tuning of transport protocols, and interoperability with other metadata frameworks such as OpenStack’s Keystone and Kubernetes’ API server.
Comments & Academic Discussion
Loading comments...
Leave a Comment