Analyzing Tag Distributions in Folksonomies for Resource Classification
Recent research has shown the usefulness of social tags as a data source to feed resource classification. Little is known about the effect of settings on folksonomies created on social tagging systems. In this work, we consider the settings of social tagging systems to further understand tag distributions in folksonomies. We analyze in depth the tag distributions on three large-scale social tagging datasets, and analyze the effect on a resource classification task. To this end, we study the appropriateness of applying weighting schemes based on the well-known TF-IDF for resource classification. We show the great importance of settings as to altering tag distributions. Among those settings, tag suggestions produce very different folksonomies, which condition the success of the employed weighting schemes. Our findings and analyses are relevant for researchers studying tag-based resource classification, user behavior in social networks, the structure of folksonomies and tag distributions, as well as for developers of social tagging systems in search of an appropriate setting.
💡 Research Summary
The paper investigates how the configuration of social tagging systems influences the distribution of tags within folksonomies and, consequently, the performance of tag‑based resource classification. While prior work has demonstrated that social tags can be valuable features for classifying resources, little attention has been paid to the mechanisms that generate those tags. To fill this gap, the authors conduct a systematic study on three large‑scale, publicly available datasets: Delicious (web pages), LibraryThing (books), and Flickr (images). Each dataset represents a different tagging environment with distinct tag‑suggestion policies: Delicious offers free‑form tagging supplemented by popular‑tag auto‑completion, LibraryThing provides a limited set of pre‑defined suggestions, and Flickr employs a hybrid approach that mixes image‑derived metadata with user behavior to generate recommendations.
After normalizing tags (lower‑casing, stemming, stop‑word removal) and aggregating user‑tag frequencies, the authors compute several weighting schemes for each resource: classic TF‑IDF, BM25, and two TF‑IDF variants—TF‑IDF‑S (which incorporates a user‑specific scaling factor) and TF‑IDF‑C (which adds a category‑level adjustment). These weighted tag vectors are fed into standard multi‑class classifiers (linear SVM and logistic regression) to predict resource categories. Evaluation follows a 10‑fold cross‑validation protocol, reporting accuracy, precision, recall, and F1‑score.
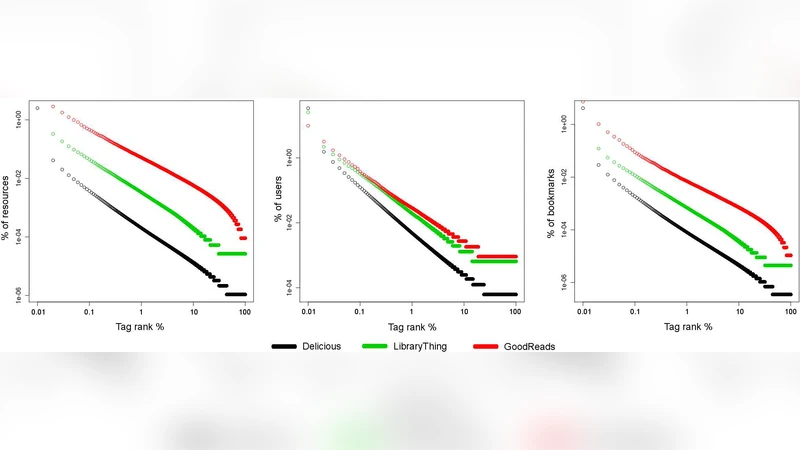
The experimental results reveal two central insights. First, tag‑suggestion mechanisms dramatically reshape tag frequency distributions. In systems that aggressively suggest popular tags, a small subset of tags dominates the corpus, leading to a steep drop in entropy and a corresponding reduction in inverse document frequency (IDF) values. Consequently, TF‑IDF‑based weights become less discriminative, and classification performance suffers. For example, on the Delicious dataset, the TF‑IDF model achieves only 68 % accuracy, whereas on LibraryThing—where suggestions are limited—the same model reaches 81 % accuracy. Second, environments with minimal or no suggestion support retain a richer, more balanced tag vocabulary. In these settings, sparse, user‑specific tags often encode domain‑specific semantics that are highly informative for classification, allowing TF‑IDF and BM25 to perform near their theoretical optimum.
Beyond empirical findings, the authors propose practical guidelines for designing tag‑suggestion systems. They recommend (1) incorporating dynamic updates to the suggestion pool so that emerging trends and user interests are reflected, thereby preventing over‑concentration on a few popular tags; (2) personalizing suggestions based on individual user profiles to encourage the creation of unique, semantically rich tags; and (3) performing an upfront analysis of tag distribution characteristics before selecting a weighting scheme, possibly opting for user‑aware variants like TF‑IDF‑S when the data exhibits strong popularity bias.
The contribution of the paper is threefold. Academically, it provides the first quantitative linkage between tag‑suggestion policies and folksonomy structure, offering a new analytical framework for researchers studying social tagging, user behavior, and text classification. Practically, it informs developers of social platforms, digital libraries, and e‑commerce sites about the trade‑offs between user experience (through helpful suggestions) and downstream data quality for search, recommendation, and classification tasks. Finally, the study opens avenues for future work, such as modeling suggestion mechanisms with probabilistic or deep‑learning approaches and exploring non‑linear, context‑aware weighting schemes that can better capture the complex, skewed distributions observed in heavily suggested environments.