Rigorous Calculation of the Partition Function for the Finite Number of Ising Spins
The high-performance scalable parallel algorithm for rigorous calculation of partition function of lattice systems with finite number Ising spins was developed. The parallel calculations run by C++ code with using of Message Passing Interface and massive parallel instructions. The algorithm can be used for the research of the interacting spin systems in the Ising models of 2D and 3D. The processing power and scalability is analyzed for different parallel and distributed systems. Different methods of the speed up measuring allow obtain the super-linear speeding up for the small number of processes. Program code could be useful also for research by exact method of different Ising spin systems, e.g. system with competition interactions.
💡 Research Summary
**
The paper presents a high‑performance, scalable parallel algorithm for the exact calculation of the partition function of finite‑size Ising spin systems on two‑ and three‑dimensional lattices. Recognizing that computing the partition function is an NP‑complete problem for non‑planar lattices, the authors aim to overcome the limitations of traditional single‑threaded exhaustive enumeration by exploiting bit‑level parallelism and message‑passing interface (MPI) communication.
The core idea is to encode each lattice row (or column in 3‑D) as a 32‑bit unsigned integer, where each bit represents the state of a spin (up = 1, down = 0). The total magnetisation M for a configuration is obtained by counting the number of set bits across all row integers using the classic Kernighan algorithm, which runs in time proportional to the number of ones rather than the word length. Interaction energy is computed separately for rows and columns. For rows, a pairwise XOR between adjacent row integers (including periodic boundary conditions) identifies mismatched spins; a subsequent NOT operation flips the bits, and the number of resulting set bits again yields the count of aligned nearest‑neighbour pairs. Column‑wise energy is calculated by circularly shifting the bits of each row to align with the column neighbours, then applying the same XOR‑NOT‑count sequence. The total exchange energy follows from a simple arithmetic combination of these counts.
All possible spin configurations are enumerated by iterating a counter from 0 to 2ⁿ‑1, where n is the number of rows (or columns). The enumeration space is partitioned evenly among MPI processes; each process independently evaluates its assigned sub‑range using the bit‑level kernels described above. Communication is limited to a final reduction step where the root process gathers, sorts, and stores the (M, E) pairs. The authors also discuss a dynamic process‑generation scheme that could map the two nested loops onto a hierarchical process tree, allowing automatic load balancing as the number of cores grows.
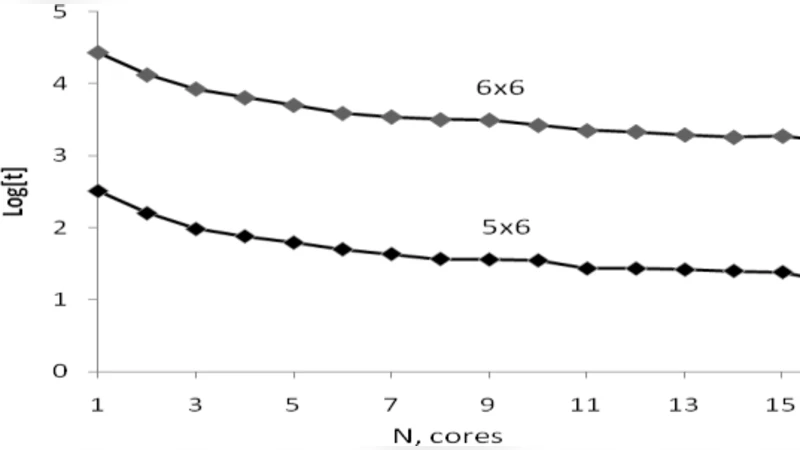
Performance testing was carried out on two heterogeneous clusters. The first “Console Cluster” combined Intel Core 2 Quad and AMD Athlon 64 X2 nodes running OpenMPI 1.4.2 under a PelicanHPC Linux distribution. The second “HP Cluster” comprised 16 Intel Xeon E5410 cores. For a 4 × 4 lattice (16 spins) the algorithm completed in a few hundredths of a second on a single core. Scaling experiments showed near‑linear speedup up to 8 cores and a modest super‑linear gain (up to ~4 % above the ideal) for small core counts, which the authors attribute to improved cache utilization during massive bit‑wise operations. However, the exponential growth of the state space remains prohibitive: a 7 × 7 lattice (49 spins) would require roughly 76 years of wall‑clock time on just two cores. Even with 16 cores, a 10 × 10 lattice (100 spins) would demand on the order of 10³³ operations, translating to ~10¹⁵ seconds (≈31.7 million years) on an ExaMIPS (10¹⁸ MIPS) machine.
The authors acknowledge that, despite the algorithm’s scalability and efficient low‑level implementation, the fundamental O(2ᴺ) complexity cannot be eliminated for exact enumeration. They suggest future directions such as exploiting global symmetries (spin‑flip, lattice rotations), hyper‑symmetry reductions, GPU‑accelerated bit‑wise kernels, and distributed checkpointing to push the practical limit further. The exact (M, E) data produced by the code can serve as a benchmark for Monte‑Carlo simulations and for comparison with experimental magnetisation measurements of finite‑size magnetic materials.
In conclusion, the work delivers a concrete, high‑performance tool for exact Ising partition‑function calculations on modest lattice sizes, demonstrates its parallel scalability across heterogeneous hardware, and provides a clear roadmap for extending its applicability to larger systems through algorithmic and architectural innovations.
Comments & Academic Discussion
Loading comments...
Leave a Comment