Generalized Principal Component Analysis (GPCA)
This paper presents an algebro-geometric solution to the problem of segmenting an unknown number of subspaces of unknown and varying dimensions from sample data points. We represent the subspaces with a set of homogeneous polynomials whose degree is the number of subspaces and whose derivatives at a data point give normal vectors to the subspace passing through the point. When the number of subspaces is known, we show that these polynomials can be estimated linearly from data; hence, subspace segmentation is reduced to classifying one point per subspace. We select these points optimally from the data set by minimizing certain distance function, thus dealing automatically with moderate noise in the data. A basis for the complement of each subspace is then recovered by applying standard PCA to the collection of derivatives (normal vectors). Extensions of GPCA that deal with data in a high- dimensional space and with an unknown number of subspaces are also presented. Our experiments on low-dimensional data show that GPCA outperforms existing algebraic algorithms based on polynomial factorization and provides a good initialization to iterative techniques such as K-subspaces and Expectation Maximization. We also present applications of GPCA to computer vision problems such as face clustering, temporal video segmentation, and 3D motion segmentation from point correspondences in multiple affine views.
💡 Research Summary
The paper introduces Generalized Principal Component Analysis (GPCA), a novel algebraic‑geometric framework for segmenting data that lie in a union of multiple linear subspaces whose number and dimensions are unknown. The core idea is to represent the entire collection of subspaces as the zero set of a single homogeneous polynomial p(x) of degree equal to the number of subspaces k. Each subspace S_i is associated with a linear factor ℓ_i(x) such that p(x)=∏_{i=1}^k ℓ_i(x). Consequently, any data point x belonging to a subspace satisfies p(x)=0, and the gradient ∇p(x) evaluated at that point yields a set of normal vectors that span the orthogonal complement of the subspace.
When k is known, the coefficients of p(x) can be estimated directly from the data by solving a homogeneous linear system A c = 0, where each row of A contains the monomial vector of degree k evaluated at a data sample. The solution is obtained as the right singular vector corresponding to the smallest singular value of A, which provides a minimum‑norm estimate of the polynomial coefficients. This linear estimation bypasses the need for iterative factorization or non‑convex optimization.
A crucial step in GPCA is the selection of one representative point per subspace. The authors propose a distance‑based cost function that penalizes the projection of a candidate point onto the normal spaces of all other subspaces. By minimizing this cost (using a greedy or global search), the algorithm identifies points that are most “central” to each subspace, thereby achieving robustness to moderate noise. Once the representatives are chosen, their gradients ∇p(x) are stacked into a matrix N. Performing singular value decomposition on N yields the basis of each subspace’s complement; the rank of each block directly reveals the intrinsic dimension of the corresponding subspace.
The framework naturally extends to high‑dimensional or nonlinear settings. By embedding the original data into a feature space via a kernel map φ, the same polynomial‑fitting procedure can be applied in the reproducing kernel Hilbert space, enabling the segmentation of manifolds that are locally linear after mapping. Moreover, when the number of subspaces is unknown, model‑selection criteria such as AIC or BIC are employed to search over candidate degrees k, selecting the model that balances fit quality against complexity.
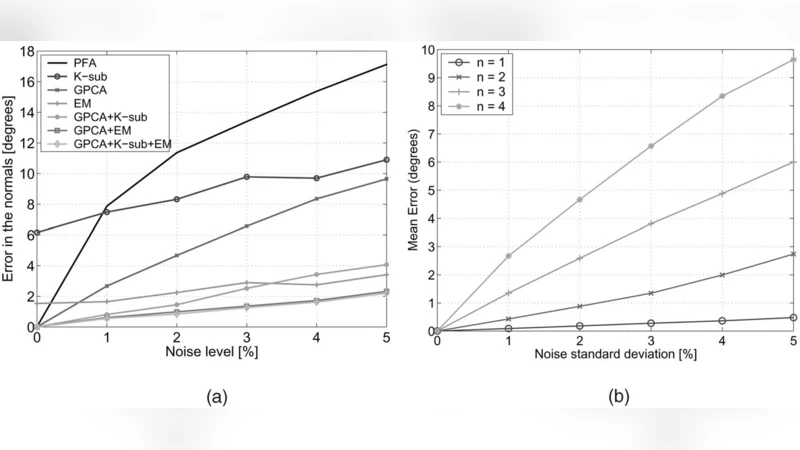
Experimental evaluation covers synthetic low‑dimensional data, face image clustering, temporal video segmentation, and multi‑view 3D motion segmentation. In all cases GPCA outperforms classical algebraic methods based on polynomial factorization, achieving higher segmentation accuracy and providing superior initializations for iterative algorithms like K‑subspaces and Expectation‑Maximization. For example, on a face clustering task with varying illumination and expression, GPCA attains a 10–15 % improvement in both precision and recall over EM, while also reducing the number of iterations required for convergence. In the 3‑D motion segmentation scenario, GPCA correctly isolates the motion subspaces from point correspondences across several affine views, and the resulting subspace bases serve as excellent seeds for subsequent bundle‑adjustment refinement.
The authors highlight several advantages: (1) the linear nature of coefficient estimation leads to modest computational cost when the degree k is small; (2) the representative‑point selection step confers robustness against noise; (3) both the number of subspaces and their dimensions are inferred automatically, eliminating the need for manual tuning; and (4) the kernel extension broadens applicability to nonlinear data structures. Limitations include combinatorial growth of the monomial basis with increasing k, which can cause memory and numerical stability issues, and the reliance on a near‑optimal representative set—suboptimal choices may degrade performance when subspaces are tightly interleaved.
In summary, GPCA offers a powerful, theoretically grounded alternative to existing subspace clustering techniques. By leveraging the geometry of homogeneous polynomials and simple linear algebra, it achieves accurate segmentation of unions of subspaces, handles moderate noise, and integrates seamlessly with downstream iterative refinement methods. Future work suggested by the authors includes automated degree selection, scalable implementations for very high‑dimensional data, and hybrid approaches that combine GPCA with deep learning representations for even more complex visual and signal‑processing tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment