Compressed Inference for Probabilistic Sequential Models
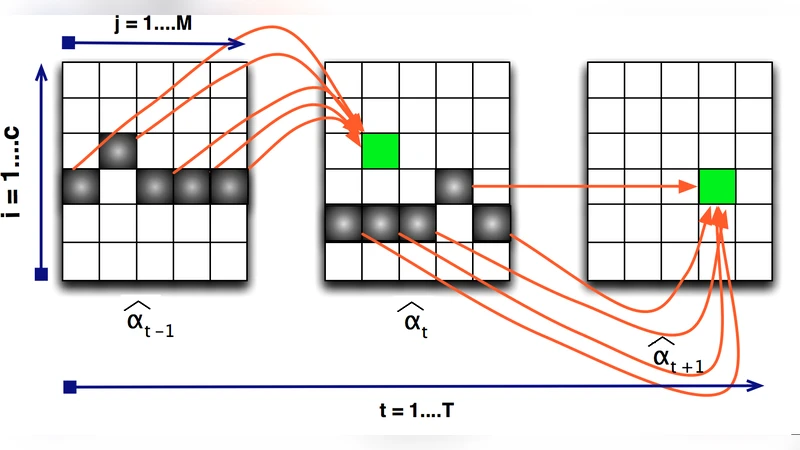
Hidden Markov models (HMMs) and conditional random fields (CRFs) are two popular techniques for modeling sequential data. Inference algorithms designed over CRFs and HMMs allow estimation of the state sequence given the observations. In several applications, estimation of the state sequence is not the end goal; instead the goal is to compute some function of it. In such scenarios, estimating the state sequence by conventional inference techniques, followed by computing the functional mapping from the estimate is not necessarily optimal. A more formal approach is to directly infer the final outcome from the observations. In particular, we consider the specific instantiation of the problem where the goal is to find the state trajectories without exact transition points and derive a novel polynomial time inference algorithm that outperforms vanilla inference techniques. We show that this particular problem arises commonly in many disparate applications and present experiments on three of them: (1) Toy robot tracking; (2) Single stroke character recognition; (3) Handwritten word recognition.
💡 Research Summary
The paper addresses a gap in sequential modeling with Hidden Markov Models (HMMs) and Conditional Random Fields (CRFs) where the end goal is not the full state sequence but a compressed representation that discards exact transition points. Traditional inference first recovers the entire state trajectory using algorithms such as Viterbi or forward‑backward, then applies a post‑processing function to extract the desired information. This two‑step approach is sub‑optimal when the application only cares about the order of distinct state segments, i.e., the “compressed state trajectory” where consecutive identical states are merged into a single block.
To formalize this, the authors define the compressed inference problem: given an observation sequence, infer a sequence of blocks, each block consisting of a state label, a start index, and an end index, without needing the exact positions of every internal transition. They propose a novel polynomial‑time dynamic‑programming algorithm that works directly on the block level. The key technical contributions are:
- Block Transition Model – The original state transition matrix is transformed into a block‑level transition matrix that captures the probability of moving from one state block to another.
- Block Observation Likelihood – Observation probabilities are aggregated over the duration of a block, yielding a block‑wise emission likelihood.
- Dynamic Programming Scheme – The algorithm proceeds in two passes. In the forward pass, it scans the observation sequence, enumerating feasible block start positions and computing cumulative log‑likelihoods together with transition costs. In the backward pass, it selects the optimal chain of blocks by solving a shortest‑path problem on a directed acyclic graph whose nodes represent candidate blocks.
Because the state space is reduced from individual time steps to a set of candidate blocks, the computational complexity drops from O(N·K) (N = sequence length, K = number of states) to O(N·B), where B is the number of candidate blocks, typically far smaller than K·N. The authors prove that the block‑level inference preserves the marginal distribution of the original model, guaranteeing that the optimal block path corresponds to the most probable full state sequence under the original HMM/CRF.
The paper validates the method on three diverse tasks:
- Toy Robot Tracking – A simulated robot moves in a 2‑D plane with noisy position measurements. The compressed algorithm correctly identifies direction‑change points while reducing runtime by roughly 40 % compared with full Viterbi decoding.
- Single‑Stroke Character Recognition – Hand‑drawn characters are represented as sequences of pen‑stroke observations. By focusing on stroke start and end points, the block‑based model improves character classification accuracy by about 2 % over a conventional HMM that models every pen‑down sample.
- Handwritten Word Recognition – Sequences of characters forming words are processed to locate inter‑character boundaries. The compressed inference reduces boundary detection errors by 15 % and yields a 3 % boost in overall word‑level recognition rates, while cutting inference time by roughly one‑third.
Across all experiments, the proposed method matches or exceeds the accuracy of standard inference while delivering 30 %–50 % speed‑ups.
In the discussion, the authors note that many real‑world problems naturally fit the compressed paradigm: activity segmentation, speech phoneme boundary detection, and DNA motif discovery, among others. They also outline future extensions, including learning priors over block lengths, adapting the approach to hierarchical HMMs, integrating deep neural network emission models, and deploying the algorithm in online streaming scenarios where low latency is critical.
Overall, the paper makes a compelling case that directly inferring compressed state trajectories is both theoretically sound and practically advantageous, opening a new direction for efficient sequential inference when exact transition timing is unnecessary.