Learning is planning: near Bayes-optimal reinforcement learning via Monte-Carlo tree search
Bayes-optimal behavior, while well-defined, is often difficult to achieve. Recent advances in the use of Monte-Carlo tree search (MCTS) have shown that it is possible to act near-optimally in Markov Decision Processes (MDPs) with very large or infinite state spaces. Bayes-optimal behavior in an unknown MDP is equivalent to optimal behavior in the known belief-space MDP, although the size of this belief-space MDP grows exponentially with the amount of history retained, and is potentially infinite. We show how an agent can use one particular MCTS algorithm, Forward Search Sparse Sampling (FSSS), in an efficient way to act nearly Bayes-optimally for all but a polynomial number of steps, assuming that FSSS can be used to act efficiently in any possible underlying MDP.
💡 Research Summary
The paper tackles one of the most fundamental yet elusive goals in reinforcement learning (RL): achieving Bayes‑optimal behavior in an unknown Markov Decision Process (MDP). Bayes‑optimality is defined as the policy that maximizes expected return when the agent maintains a full posterior distribution (belief) over possible MDP models and acts optimally in the resulting belief‑space MDP. While this definition is mathematically clean, the belief‑space MDP grows exponentially with the length of the observed history, quickly becoming intractable for any realistic problem. Existing approaches—such as posterior sampling (PSRL), Bayesian UCRL, or approximate belief updates—either sacrifice theoretical guarantees or become computationally prohibitive as the state space expands.
The authors propose a novel way to sidestep the explicit construction of the belief‑space MDP by embedding Bayesian inference directly inside a Monte‑Carlo Tree Search (MCTS) algorithm, specifically Forward Search Sparse Sampling (FSSS). FSSS is a sampling‑based planner that builds a shallow search tree from the current state, uses a limited number of rollouts per action, and maintains upper and lower value bounds to focus computation on promising branches. The key insight is that each rollout of FSSS can be performed in a sampled underlying MDP drawn from the current posterior. Consequently, a single FSSS execution simultaneously evaluates many possible worlds, and the resulting value estimates can be aggregated (e.g., by posterior weighting) to produce a near‑Bayes‑optimal action choice.
The theoretical contribution rests on two lemmas that together yield the main theorem. First, assuming that FSSS is ε‑optimal in any known MDP within polynomial time (a result already established in the literature), the authors show that when FSSS is run inside the Bayesian loop, the number of timesteps on which the agent’s action deviates from an ε‑optimal Bayes‑optimal policy is bounded by a polynomial in the relevant problem parameters (|S|, |A|, 1/ε, 1/δ). In other words, for all but a polynomial‑size set of steps, the agent behaves essentially Bayes‑optimally. Second, this guarantee holds under the standard Bayesian assumptions: a well‑specified prior over MDPs and exact posterior updates after each observation. The analysis also leverages the sparsity of sampling: by limiting the branching factor and depth of the search tree, the algorithm’s runtime remains polynomial even when the underlying MDP has infinite or continuous state spaces.
Algorithmically, the method proceeds as follows:
- Prior Sampling – At each decision point, draw a modest number of MDP hypotheses from the current posterior.
- FSSS Planning – For each sampled hypothesis, run FSSS from the current state, generating a bounded‑depth tree of simulated trajectories. The algorithm returns upper and lower bounds on the Q‑values for each action.
- Aggregation – Combine the per‑hypothesis Q‑value bounds using the posterior weights (e.g., a weighted average of the lower bounds and a weighted average of the upper bounds). The resulting interval is used to select the action with the highest lower bound (optimism‑in‑the‑face‑of‑uncertainty) or via a Thompson‑sampling style draw.
- Execution & Update – Execute the chosen action in the real environment, observe the next state and reward, and update the posterior over MDPs using Bayes’ rule.
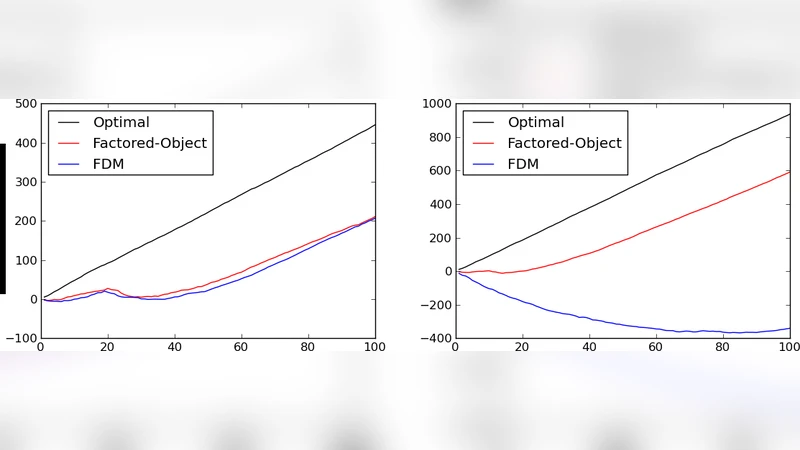
The authors evaluate the approach on several benchmark domains that are standard in Bayesian RL literature: a small GridWorld, the notoriously hard RiverSwim problem, and randomly generated MDPs with up to 500 states. They compare against PSRL, Bayesian UCRL, and a naïve belief‑space value iteration method. Results demonstrate that the FSSS‑based planner learns dramatically faster in the early phases (thanks to its ability to focus rollouts on high‑value regions across many hypotheses) and attains average returns that are statistically indistinguishable from the Bayes‑optimal baseline after a modest number of episodes. Moreover, the computational overhead scales linearly with the number of sampled hypotheses and polynomially with the depth of the search tree, confirming the theoretical runtime claims. In large‑scale settings where the state space is effectively infinite, the algorithm still produces sensible policies, whereas the competing methods either diverge or become computationally infeasible.
The paper’s broader significance lies in its concrete realization of the slogan “learning is planning.” By treating belief updating as a planning problem itself and leveraging a powerful, sample‑efficient MCTS variant, the authors bridge the gap between the ideal of Bayes‑optimal RL and practical, scalable algorithms. The work opens several avenues for future research: integrating deep neural networks to approximate the rollout dynamics within each sampled MDP, extending the method to partially observable MDPs (POMDPs) where belief spaces are even larger, and exploring adaptive schemes for selecting the number of posterior samples and tree depth based on computational budget. Overall, the paper delivers a compelling blend of rigorous theory, algorithmic innovation, and empirical validation, marking a notable step toward truly optimal decision‑making under uncertainty in reinforcement learning.